

一、 初步认识
mysql的下载和安装请看:
Navicat安装和汉化:
MAC--安装mysql及可视化工具 Navicat Premiun
1、命令行打开数据库
mysql -u root -p
// 然后输入密码
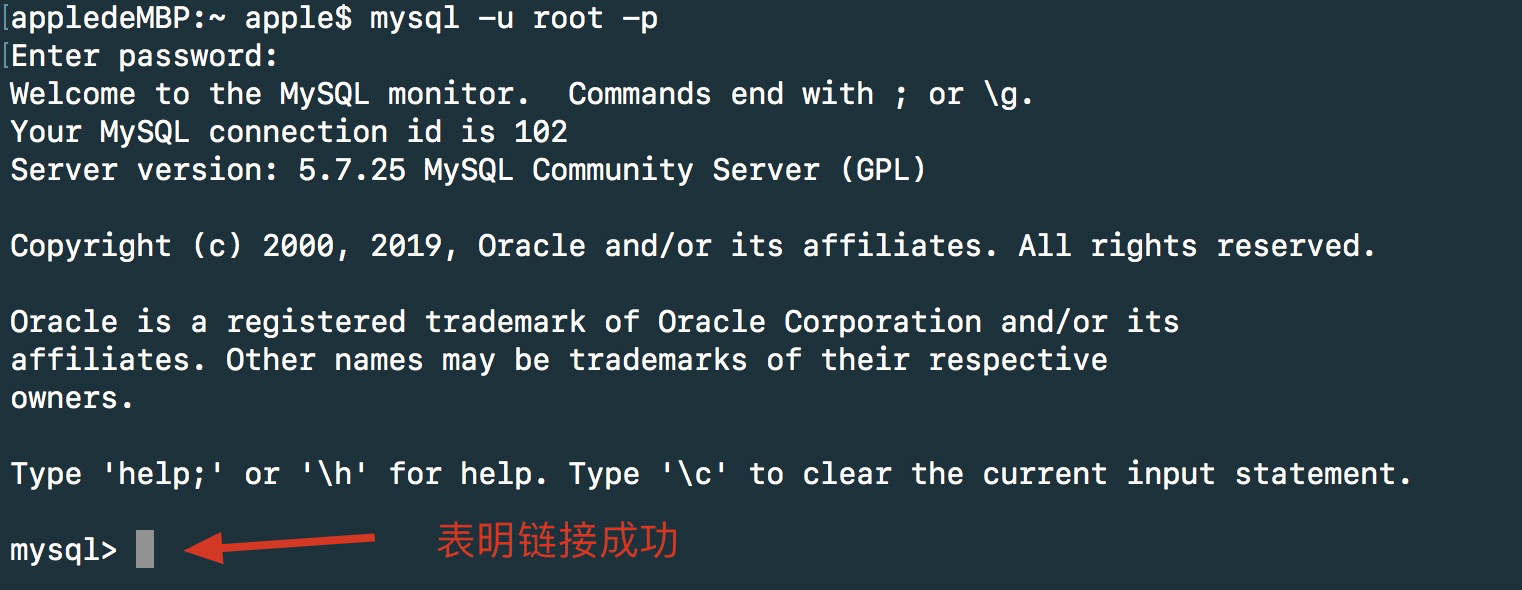
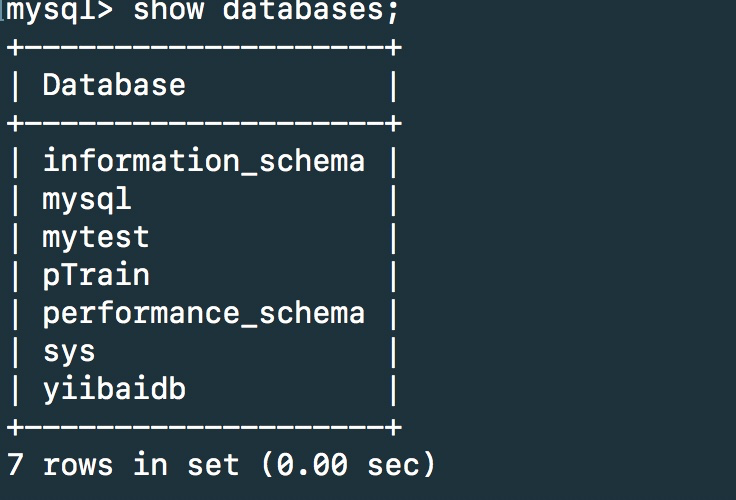
查看当前数据库
2、Navicat 如何连接
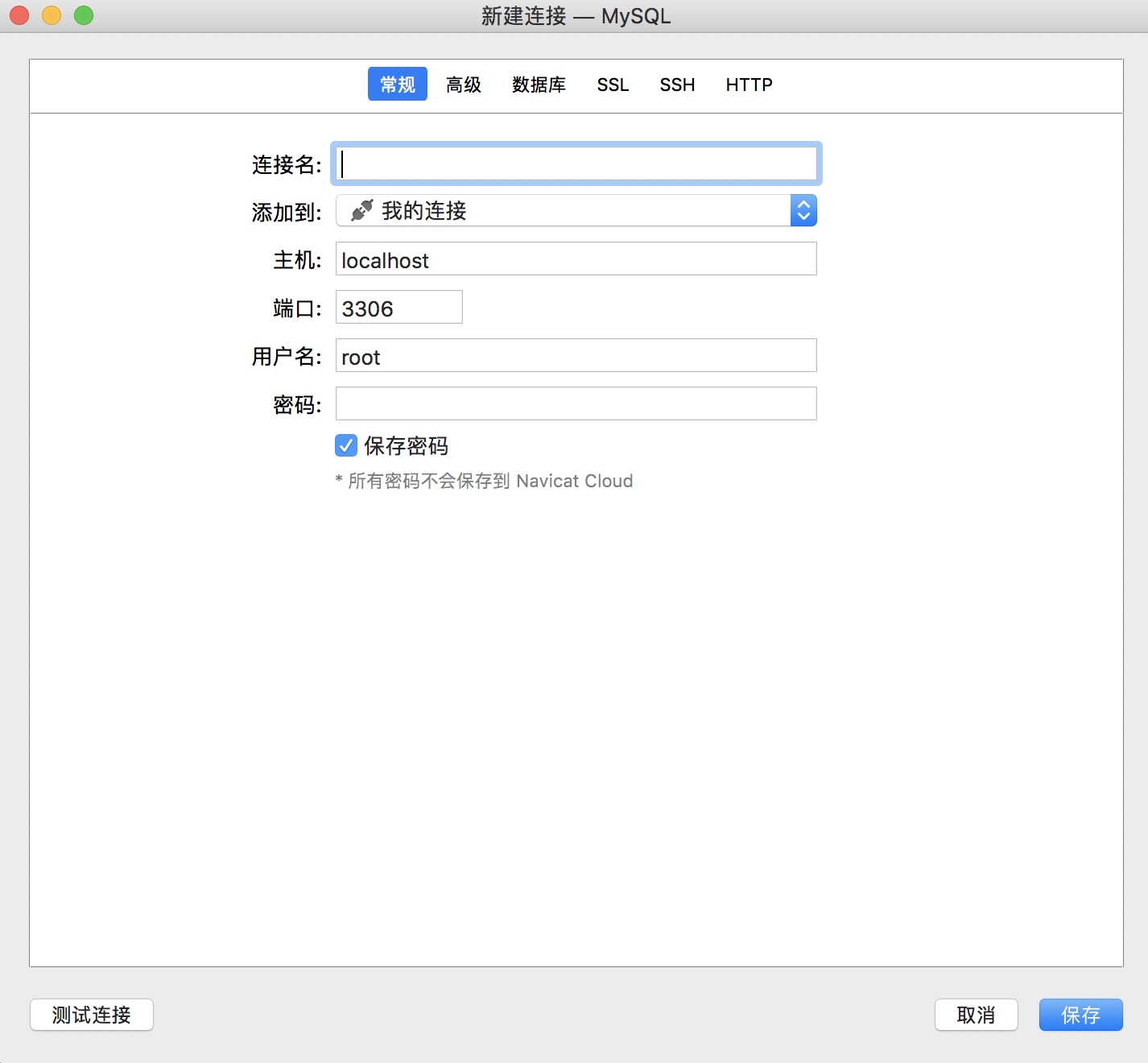
切记一定要输入密码哦~,密码是你自己设置的。
创建数据库:
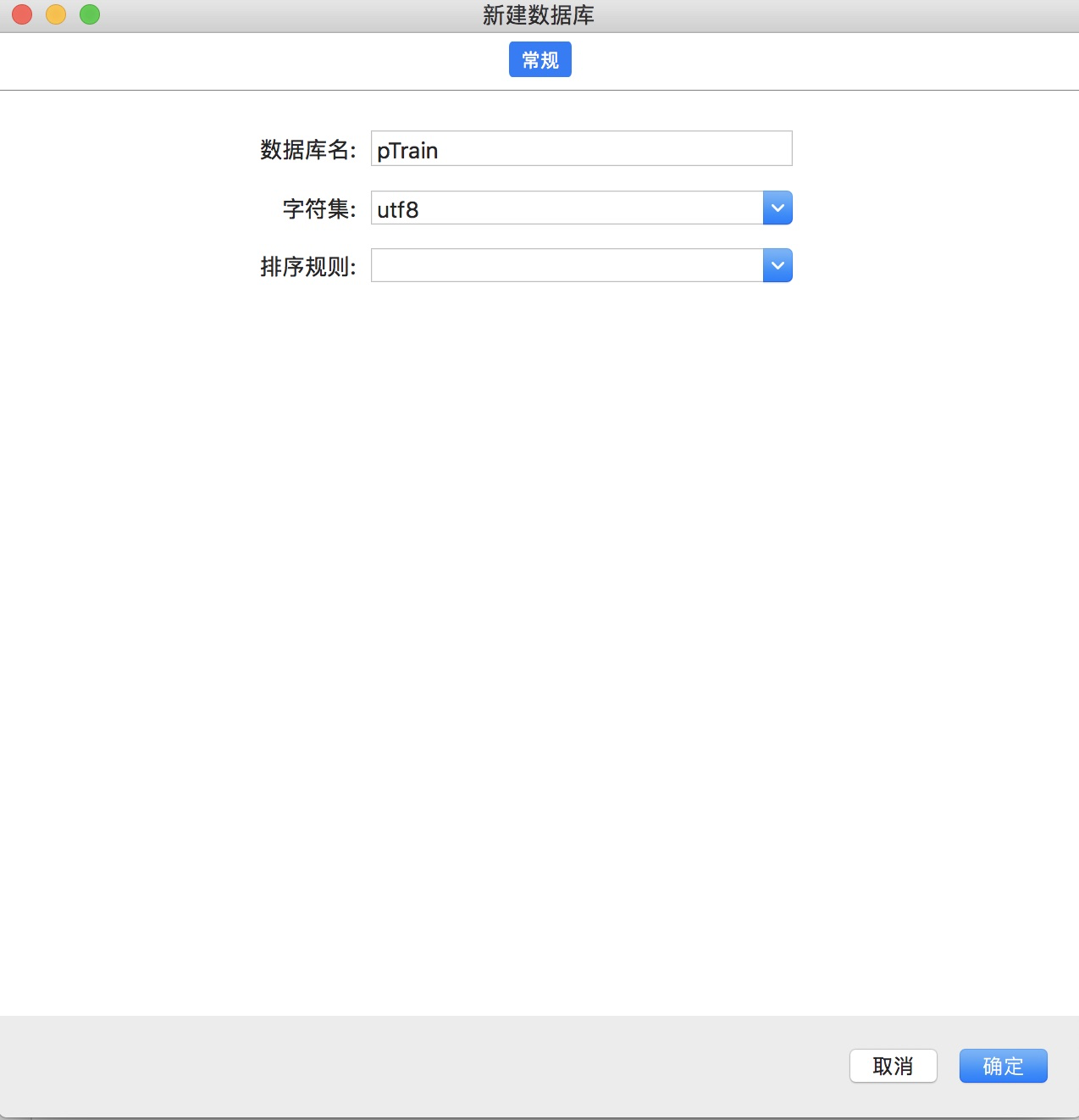
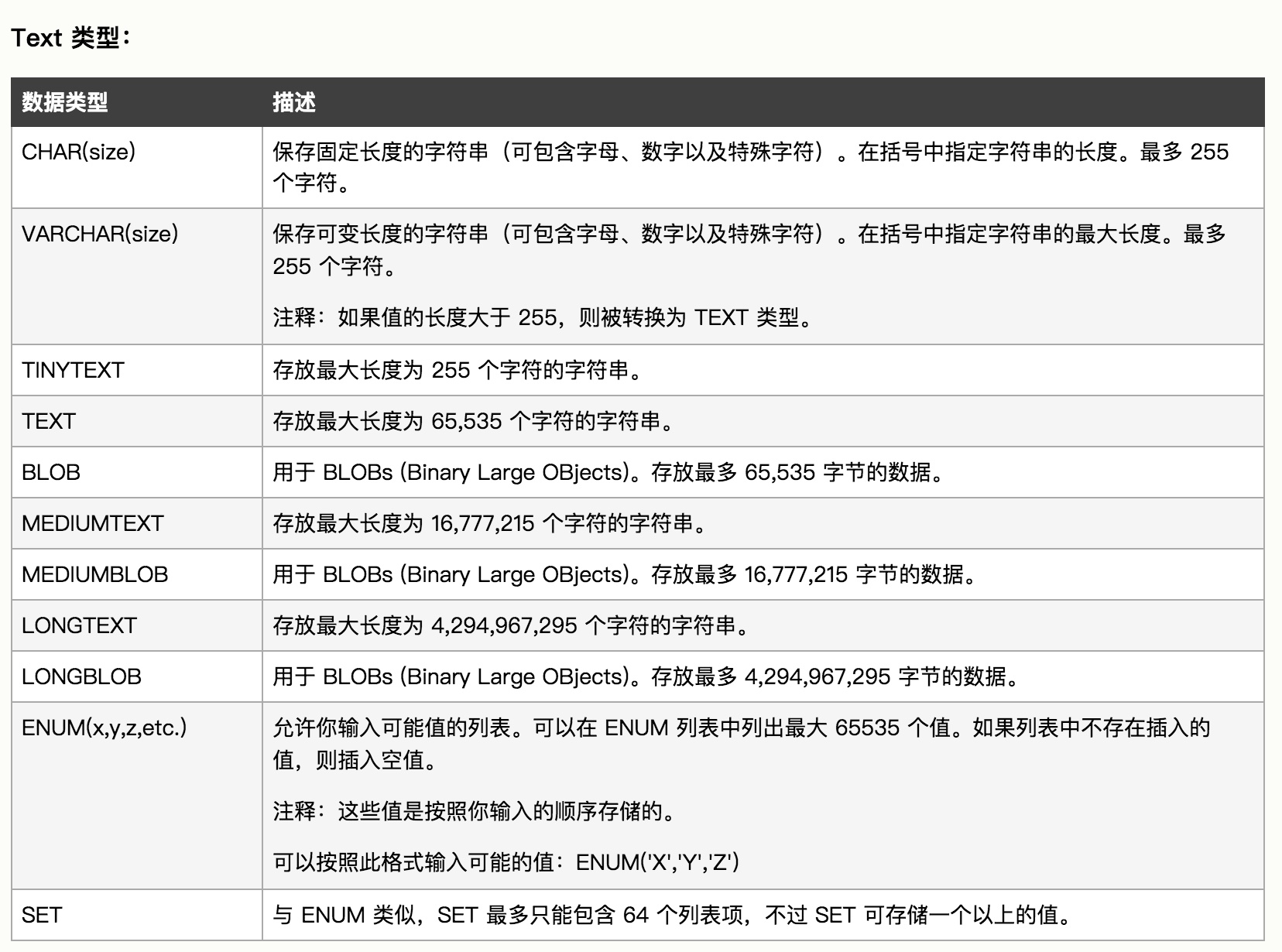
3、数据类型


二、操作合集
1、导入数据库
第一步 下载sql文件
第二步 创建数据库
mysql> CREATE DATABASE IF NOT EXISTS yiibaidb DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
第三步 执行导入
mysql> use yiibaidb;
Database changed
mysql> source /meilsweb/interview/Mysql/素材/yiibaidb.sql;
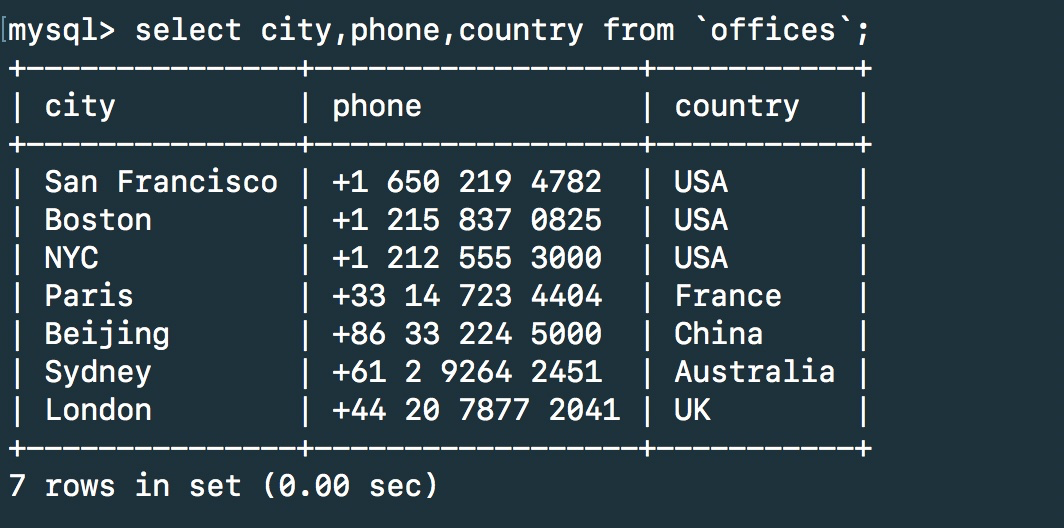
第四步 测试一下
2、MySQL插入数据
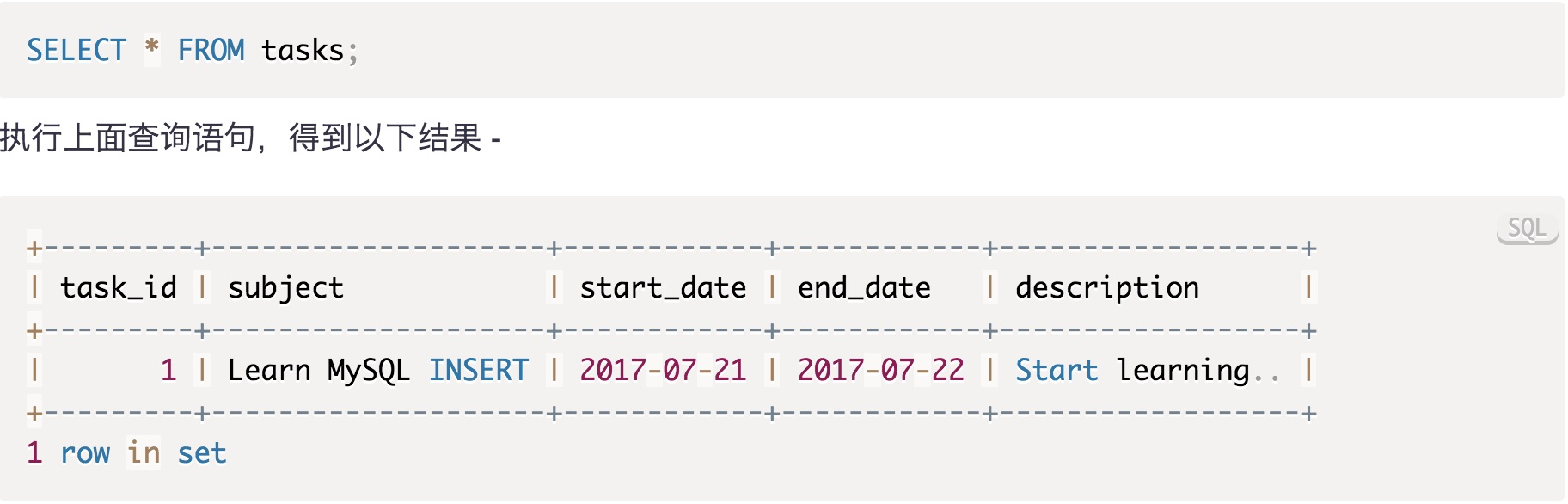
插入一行
INSERT INTO tasks(subject,start_date,end_date,description)
VALUES('Learn MySQL INSERT','2017-07-21','2017-07-22','Start learning..');
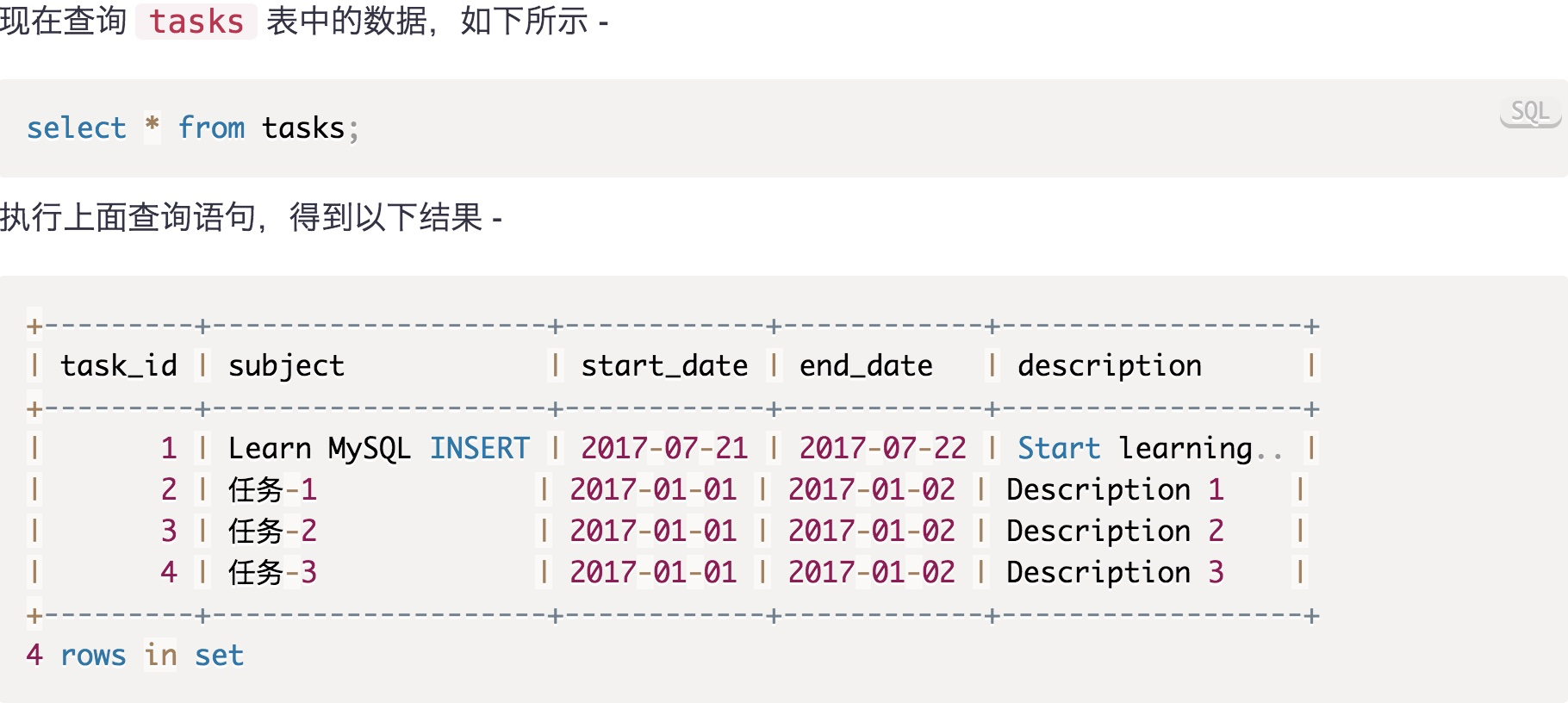
插入多行
INSERT INTO tasks(subject,start_date,end_date,description)
VALUES ('任务-1','2017-01-01','2017-01-02','Description 1'),
('任务-2','2017-01-01','2017-01-02','Description 2'),
('任务-3','2017-01-01','2017-01-02','Description 3');
Query OK, 3 rows affected
Records: 3 Duplicates: 0 Warnings: 0
具有SELECT子句的MySQL INSERT
将查询出来的数据插入到拷贝的数据表中

3、MySQL删除表数据
基本的删除操作

DELETE FROM employees
WHERE
officeCode = 4;
DELETE和LIMIT子句
如果要限制要删除的行数,则使用LIMIT子句,如下所示:
DELETE FROM table
LIMIT row_count;
SQL请注意,表中的行顺序未指定,因此,当您使用LIMIT子句时,应始终使用ORDER BY子句,不然删除的记录可能不是你所预期的那样
DELETE FROM table_name
ORDER BY c1, c2, ...
LIMIT row_count;
如: 类似地,以下DELETE语句选择法国(France)的客户,按升序按信用额度(creditLimit)进行排序,并删除前5个客户:
DELETE FROM customers
WHERE country = 'France'
ORDER BY creditLimit
LIMIT 5;
4、MySQL更新表数据


UPDATE一个单列示例
UPDATE employees
SET
email = 'mary.new@yiibai.com'
WHERE
employeeNumber = 1056;
UPDATE多个单列示例
UPDATE customers
SET
salesRepEmployeeNumber = (SELECT
employeeNumber
FROM
employees
WHERE
jobtitle = 'Sales Rep'
LIMIT 1)
WHERE
salesRepEmployeeNumber IS NULL; // 会返回多个行
5、MySQL查询表数据

(1)基本查询
SELECT * FROM work;
SELECT workerid,workername FROM work;
(2)查询经过计算的列
SELECT workerid, money+1000 FROM work;
// 请从表EMP中查找工种是办事员或经理雇员姓名、总工资(包括薪金和佣金)。
select ename,sal+ifnull(comm,0) from emp where job='办事员' or job='经理'
// ifnull判断是否为空
(3)为无名列指定名字
SELECT workerid AS 主键, '我是常量内容' AS 常量 , money+1000 AS 总金额 FROM work;
(4)去除掉重复的行,使用了关键字DISTINCT
去除掉取值相同的行
(5)WHERE 用法
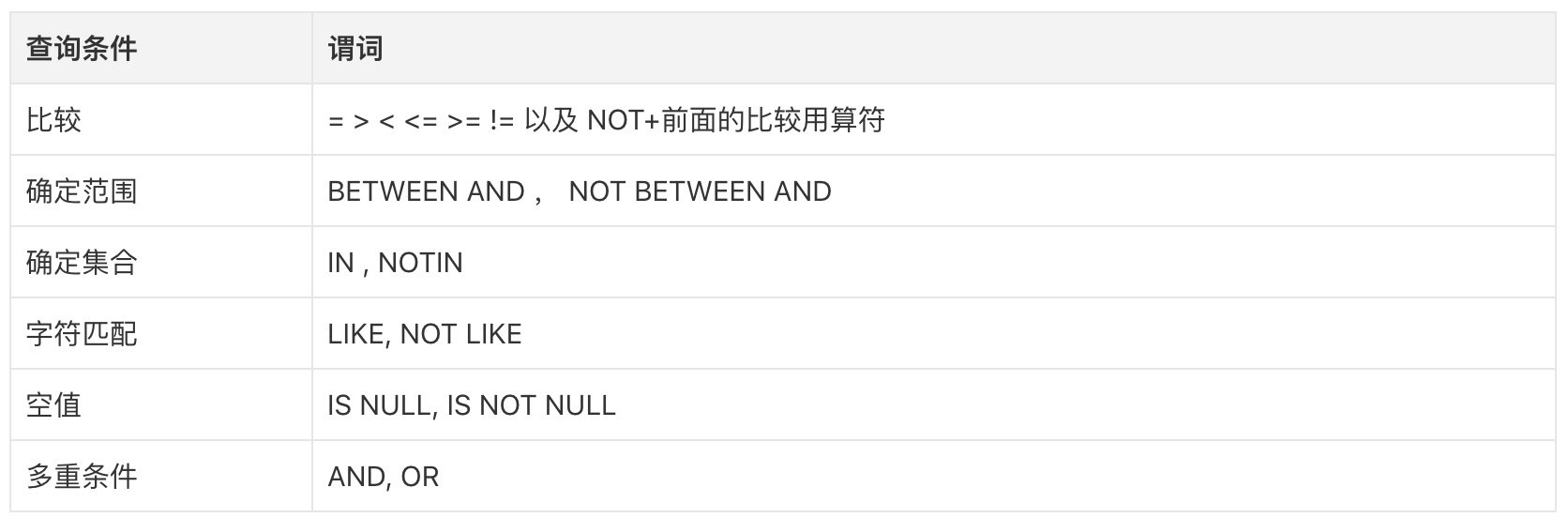
(6)比较大小
SELECT * FROM work WHERE money=1400;
// 请从表EMP中查找总工资低于2000的雇员的姓名、工作、工资,并按工资降序排列。
select ename,job,sal from emp where (sal+(ifnull(comm,0)))<2000 order by sal desc
(7)确定范围
SELECT * FROM work WHERE money BETWEEN 1200 AND 1700;
// BETWEEN 1200 AND 1700; 相当于是 同时满足 >=1200 <=1700
SELECT * FROM work WHERE money NOT BETWEEN 1200 AND 1700;
// 相反操作
(8)对于日期的比较
SELECT * FROM books WHERE time BETWEEN '2009/3/12' AND '2010/4/23';
(9)确定集合
SELECT * FROM work WHERE money IN ('1400','1500','1700');
(10)字符串匹配
_ 下划线, 匹配任意一个字符
% 匹配0或者多个字符
[] 匹配[]中的任意一个字符
[^] 不匹配[]中的任意一个字符
// 匹配姓张的人
1> SELECT * FROM work WHERE workername LIKE '张%';
//匹配姓张、李、撒的人
1> SELECT * FROM work WHERE workername LIKE '[张李撒]%';
// 不姓张也不姓王的
SELECT * FROM work WHERE workername NOT LIKE '[张王]%';
SELECT * FROM work WHERE workername LIKE '[^张王]%';
SELECT * FROM work WHERE workername LIKE '[张_]'; // 姓张且是两个字
// 去掉指定列的尾随的空格
1> SELECT * FROM work WHERE workername LIKE '[张__]';
2> go
workeridDworkernameDworknum Dmoney Dphone
--------D----------D--------D-----------D-----------
(0 行受影响)
// 为什么是无呢?
// 因为我们实际数据库的时候,给workername是char定长类型的,因此,如果不够定长,就用空格填充了,这就使得匹配无法成功。
如何解决呢?
SQL Server 提供了 rtrim(列名) 来去掉尾随的空格
1> SELECT * FROM work WHERE rtrim(workername) LIKE '[张_]%';
2> go
workeridDworkernameDworknum Dmoney Dphone
--------D----------D--------D-----------D-----------
1 D张锦杰 D1 D 1400D13752127826
6 D张爱爱 D1 D 1100D1324977734
(2 行受影响)
// 查询最后一位不是 2.3.5
1> SELECT * FROM work WHERE workername LIKE '%[^235]';
2> go
// 转义字符
ESCAPE 关键字
1> SELECT * FROM work WHERE workername LIKE '%30!%%' ESCAPE '!';
2> go
// 以!转义% 意思是查找包含30%的字符串
1> SELECT * FROM work WHERE workername LIKE '%!_%' ESCAPE '!';
2> go
// 以!转义_ 意思是查找包含30%的字符串
(11)涉及空值
SELECT * FROM SC WHERE grade IS NOT NULL;
SELECT * FROM SC WHERE grade IS NULL;
select * from emp where comm is null or ifnull(comm,0)<100
(12)多重条件查找
SELECT Sname FROM Student
WHERE Sdep = '计算机' AND Sage < 20
// AND 的 优先级比 OR 高,因此需要使用括号
SELECT Sname FROM Student
WHERE ( Sdep = '计算机' OR Sdep = '信息') AND Sage < 20
(13)排序
SELECT * FROM work ORDER BY money ASC;
SELECT * FROM work ORDER BY money DESC;
(14)使用聚合函数来汇总数据
COUNT(*) 统计表中元组的个数
COUNT (DISTINCT sno) 统计本列非空值个数
SUM (列名) 计算列的总和
AVG (列名) 计算列的平均值
MAX (列名) 列的最大值
MIN (列名) 列的最小值
// 元组总个数
1> SELECT COUNT(*) FROM work;
// 统计本列非空值个数
1> SELECT COUNT(DISTINCT money) FROM work;
// 设置列名
1> SELECT COUNT(*) AS 工人数 , AVG(money) AS 平均收入 FROM work;
// 使用MAX 和 MIN
1> SELECT MAX(money) AS '最高收入' , MIN(money) AS '最低收入' FROM work;
(15)对查询结果进行分组统计
// 首先对员工表进行按照职位分组,分为两组,然后统计每组的数据
SELECT COUNT(*) AS 职位员工数 ,AVG(money) 平均收入
FROM work GROUP BY worknum;
// 选择每个系的女生的人数
// 再来一个小李子
SELECT Sdept, Count(*) 女生人数 FROM student
WHERE Sex = '女'
GROUP BY Sdep;
(16)使用HAVING子句进行筛选
HAVING 语句对分组后的数据在进行筛选,可以使用统计函数,但是在WHERE 语句中是无法使用统计函数的。
// 拿书上的例子来说
SELECT Sno , COUNT(*) AS 选课门数 FROM SC
GROUP BY Sno
HAVING COUNT(*) >3;
// 查询选修了三门以上的学生的学号和选课数
首先进行分组,然后进行聚合计算,得到的新的表,进行筛选,得到最后的结果集。
(17)多表连接查询
连接查询包括内连接、外连接、交叉连接,在这里我们只涉及内连接、 和外连接
// 这里我们需要创建三张表
// 学生表
1> CREATE TABLE student(
2> Sno varchar(8) PRIMARY KEY,
3> Sname varchar(10) NOT NULL,
4> Sage tinyint,
5> Ssex char(2),
6> Sdept char(20)
7> );
8> go
1>var
// 课程表
1> CREATE TABLE course(
2> Cno varchar(6) PRIMARY KEY,
3> Cname varchar(10) NOT NULL,
4> Credit tinyint,
5> Semester tinyint,
6> );
7> go
// 选课表
1> CREATE TABLE SC(
2> Sno varchar(8) NOT NULL,
3> Cno varchar(6) NOT NULL,
4> grade tinyint ,
5> PRIMARY KEY(Sno, Cno),
6> FOREIGN KEY(Sno) REFERENCES student (Sno),
7> FOREIGN KEY(Cno) REFERENCES course (Cno)
8> );
9> go
1>
// 然后小编在数据库中添加了几条数据
内连接
// 将student 和 SC 连接
SELECT * FROM student INNER JOIN SC
ON student.Sno = SC.Sno;
// 查询计算机系的学生的选修情况
SELECT Sname, Cno, grade FROM student INNER JOIN SC
ON student.Sno = SC.Sno
WHERE Sdept = "计算机系";
// 统计每个系的学生考试平均成绩
SELECT Sdept , AVG(grade) as "平均成绩"
FROM student JOIN SC ON student.Sno = SC.Sno
GROUP BY Sdept;
自连接
// 自连接
// 选择跟李勇是一个系的其余同学
1> SELECT s2.Sname, s2.Sdept FROM student s1 JOIN student s2
2> ON s1.Sdept = s2.Sdept
3> WHERE s1.Sname ="李勇"
4> AND s2.Sname!= "李勇";
外连接
只限制一张表符合连接条件就行,不一定两张表都满足
// 查询学生的选课情况,包括选课的和没有选的(左外连接)
1> SELECT student.Sno, Sname, Cno, grade
2> FROM student LEFT OUTER JOIN SC
3> ON student.Sno = SC.Sno;
4> go
// 查询那些课程没有被选
1> SELECT Cname FROM course C LEFT JOIN SC
2> ON c.Cno = SC.Cno
3> WHERE SC.Cno IS NULL;
4> GO
(18)、使用TOP限制结果集
// 倒叙显示 前三个
1> SELECT TOP 3 Sname , Sage, Sdept
2> FROM student
3> ORDER BY Sage DESC;
4> GO
Sname DSageDSdept
----------D----D--------------------
张海 D 22D数学系
吴斌 D 22D信息系
王大力 D 21D数学系
// 包含并列
1> SELECT TOP 3 WITH TIES Sname, Sdept
2> FROM student
3> ORDER BY Sage DESC;
4> go
Sname DSdept
----------D--------------------
张海 D数学系
吴斌 D信息系
王明 D信息系
王大力 D数学系
(4 行受影响)
// TOP 谓词最好是于ORDER BY 配合使用
查询选课人数最少的两门课程(不包含没有选课的人)
1> SELECT TOP 2 WITH TIES Cno, COUNT(*) 选课人数
2> FROM SC
3> GROUP BY Cno
4> ORDER BY COUNT(*) ASC;
5> GO
Cno D选课人数
------D-----------
c05 D 1
c04 D 2
