

一、Druid介绍
Druid 是 MetaMarket 公司研发,专为海量数据集上的做高性能 OLAP (OnLine Analysis Processing)而设计的数据存储和分析系统,目前Druid 已经在Apache基金会下孵化。Druid的主要特性:
- 交互式查询( Interactive Query ): Druid 的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为 Druid 的查询延时通过只读取和扫描有必要的元素被优化。Druid 是列式存储,查询时读取必要的数据,查询的响应是亚秒级响应。
- 高可用性( High Available ):Druid 使用 HDFS/S3 作为 Deep Storage,Segment 会在2个 Historical 节点上进行加载;摄取数据时也可以多副本摄取,保证数据可用性和容错性。
- 可伸缩( Horizontal Scalable ):Druid 部署架构都可以水平扩展,增加大量服务器来加快数据摄取,以及保证亚秒级的查询服务
- 并行处理( Parallel Processing ): Druid 可以在整个集群中并行处理查询
- 丰富的查询能力( Rich Query ):Druid支持 Scan、 TopN、 GroupBy、 Approximate 等查询,同时提供了2种查询方式:API 和 SQL
Druid常见应用的领域:
- 网页点击流分析
- 网络流量分析
- 监控系统、APM
- 数据运营和营销
- BI分析/OLAP
二、为什么我们需要用 Druid
有赞作为一家 SaaS 公司,有很多的业务的场景和非常大量的实时数据和离线数据。在没有是使用 Druid 之前,一些 OLAP 场景的场景分析,开发的同学都是使用 SparkStreaming 或者 Storm 做的。用这类方案会除了需要写实时任务之外,还需要为了查询精心设计存储。带来问题是:开发的周期长;初期的存储设计很难满足需求的迭代发展;不可扩展。
在使用 Druid 之后,开发人员只需要填写一个数据摄取的配置,指定维度和指标,就可以完成数据的摄入;从上面描述的 Druid 特性中我们知道,Druid 支持 SQL,应用 APP 可以像使用普通 JDBC 一样来查询数据。通过有赞自研OLAP平台的帮助,数据的摄取配置变得更加简单方便,一个实时任务创建仅仅需要10来分钟,大大的提高了开发效率。
2.1、Druid 在有赞使用场景
- 系统监控和APM:有赞的监控系统(天网)和大量的APM系统都使用了 Druid 做数据分析
- 数据产品和BI分析:有赞 SaaS 服务为商家提供了有很多数据产品,例如:商家营销工具,各类 BI 报表
- 实时OLAP服务:Druid 为风控、数据产品等C端业务提供了实时 OLAP 服务
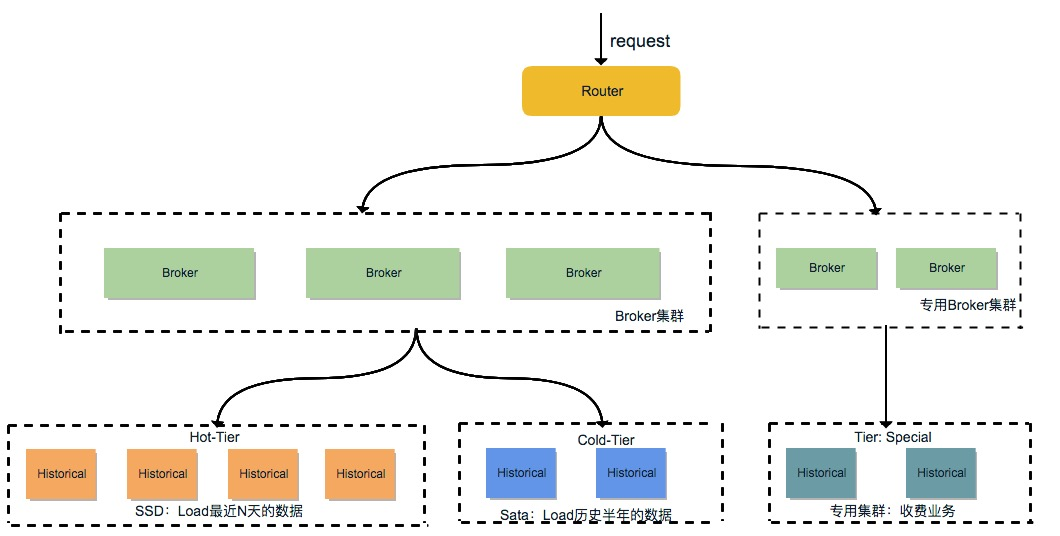
三、Druid的架构
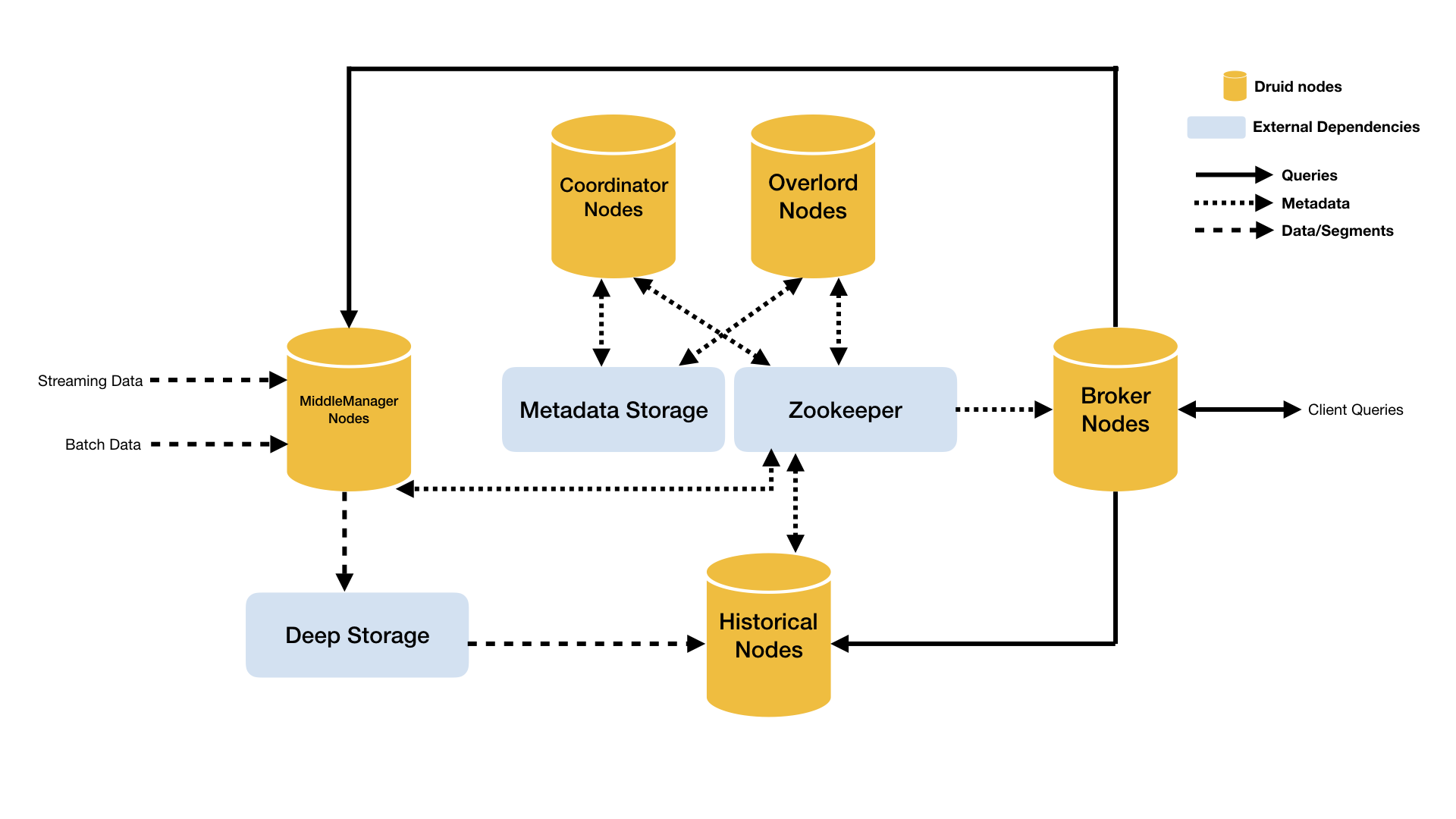
Druid 的架构是 Lambda 架构,分成实时层( Overlord、 MiddleManager )和批处理层( Broker 和 Historical )。主要的节点包括(PS: Druid 的所有功能都在同一个软件包中,通过不同的命令启动):
- Coordinator 节点:负责集群 Segment 的管理和发布,并确保 Segment 在 Historical 集群中的负载均衡
- Overlord 节点:Overlord 负责接受任务、协调任务的分配、创建任务锁以及收集、返回任务运行状态给客户端;在Coordinator 节点配置 asOverlord,让 Coordinator 具备 Overlord 功能,这样减少了一个组件的部署和运维
- MiddleManager 节点:负责接收 Overlord 分配的索引任务,创建新启动Peon实例来执行索引任务,一个MiddleManager可以运行多个 Peon 实例
- Broker 节点:负责从客户端接收查询请求,并将查询请求转发给 Historical 节点和 MiddleManager 节点。Broker 节点需要感知 Segment 信息在集群上的分布
- Historical 节点:负责按照规则加载非实时窗口的Segment
- Router 节点:可选节点,在 Broker 集群之上的API网关,有了 Router 节点 Broker 不在是单点服务了,提高了并发查询的能力
四、有赞 OLAP 平台的架构和功能解析
4.1 有赞 OLAP 平台的主要目标:
- 最大程度的降低实时任务开发成本:从开发实时任务需要写实时任务、设计存储,到只需填写配置即可完成实时任务的创建
- 提供数据补偿服务,保证数据的安全:解决因为实时窗口关闭,迟到数据的丢失问题
- 提供稳定可靠的监控服务:OLAP 平台为每一个 DataSource 提供了从数据摄入、Segment 落盘,到数据查询的全方位的监控服务
4.2 有赞 OLAP 平台架构
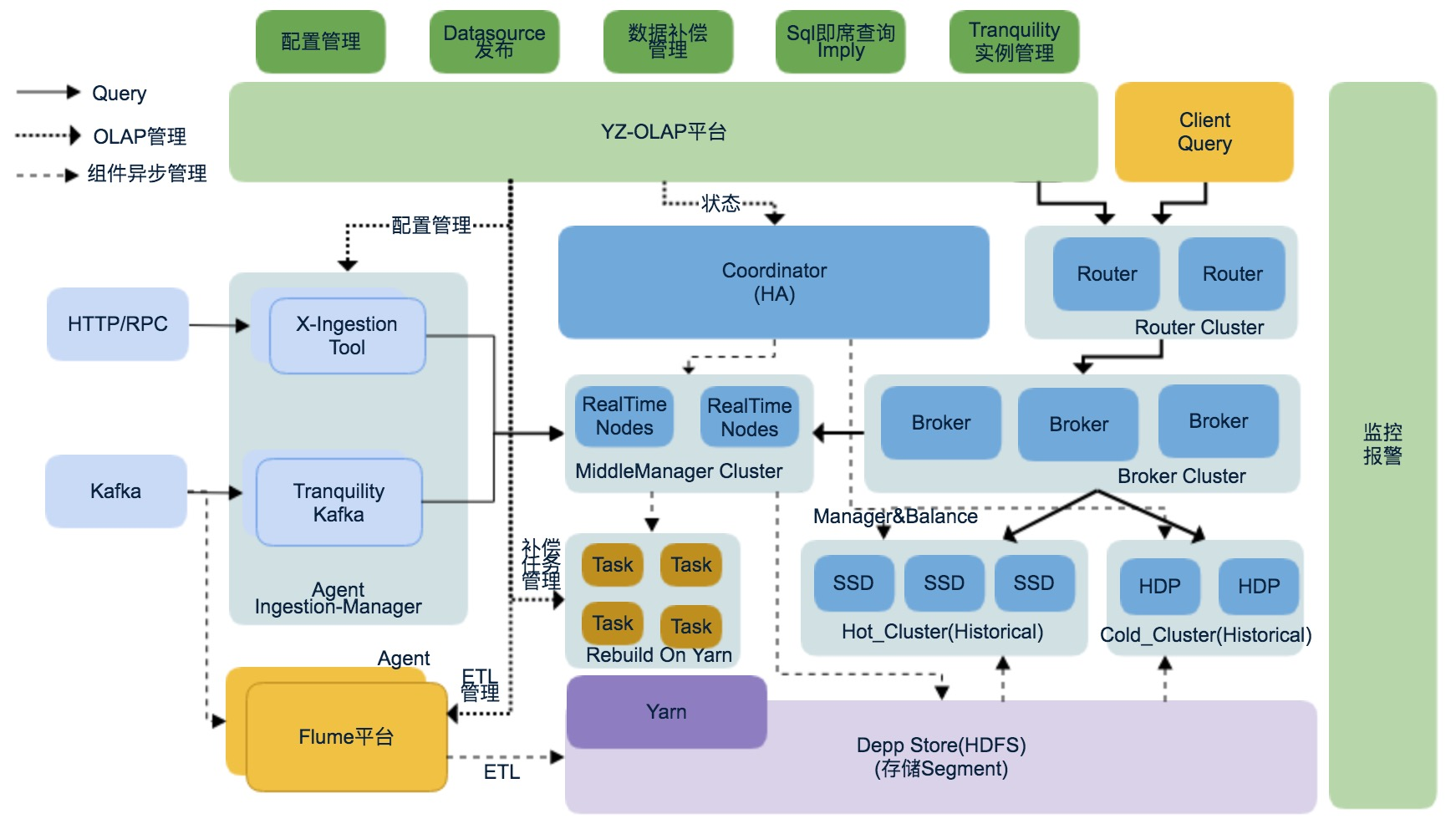
有赞 OLAP 平台是用来管理 Druid 和周围组件管理系统,OLAP平台主要的功能:
- Datasource 管理
- Tranquility 配置和实例管理:OLAP 平台可以通过配置管理各个机器上 Tranquility 实例,扩容和缩容
- 数据补偿管理:为了解决数据迟延的问题,OLAP 平台可以手动触发和自动触发补偿任务
- Druid SQL查询: 为了帮助开发的同学调试 SQL,OLAP 平台集成了 SQL 查询功能
- 监控报警
4.2 Tranquility 实例管理
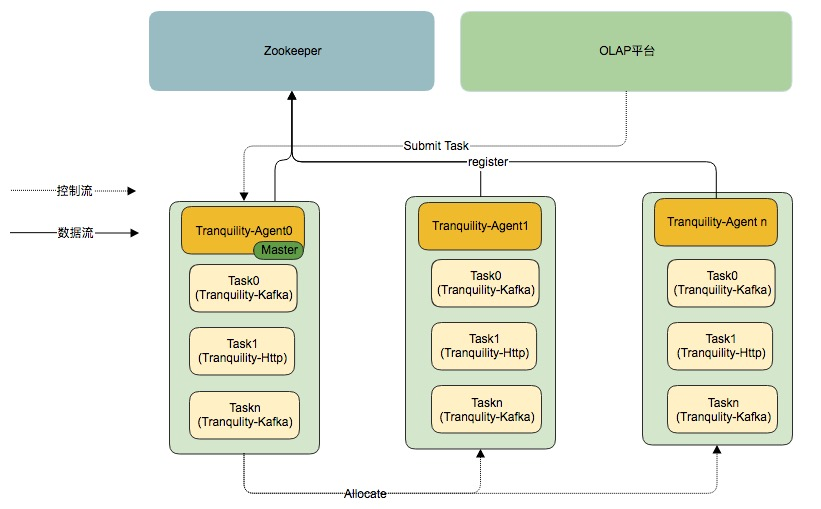
OLAP 平台采用的数据摄取方式是 Tranquility工具,根据流量大小对每个 DataSource 分配不同 Tranquility 实例数量; DataSource 的配置会被推送到 Agent-Master 上,Agent-Master 会收集每台服务器的资源使用情况,选择资源丰富的机器启动 Tranquility 实例,目前只要考虑服务器的内存资源。同时 OLAP 平台还支持 Tranquility 实例的启停,扩容和缩容等功能。
4.3 解决数据迟延问题——离线数据补偿功能
流式数据处理框架都会有时间窗口,迟于窗口期到达的数据会被丢弃。如何保证迟到的数据能被构建到 Segment 中,又避免实时任务窗口长期不能关闭。我们研发了 Druid 数据补偿功能,通过 OLAP 平台配置流式 ETL 将原始的数据存储在 HDFS 上,基于 Flume 的流式 ETL 可以保证按照 Event 的时间,同一小时的数据都在同一个文件路径下。再通过 OLAP 平台手动或者自动触发 Hadoop-Batch 任务,从离线构建 Segment。
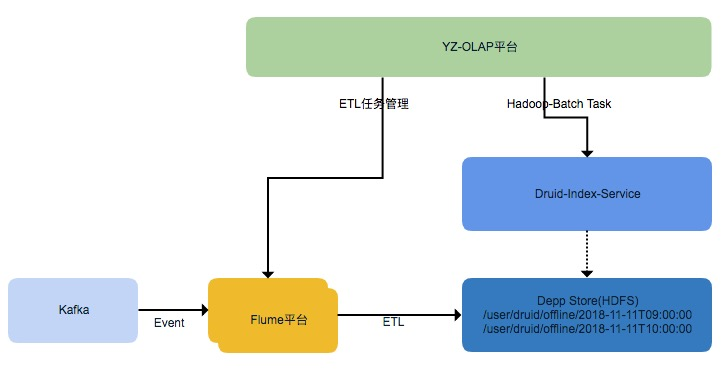
基于 Flume 的 ETL 采用了 HDFS Sink 同步数据,实现了 Timestamp 的 Interceptor,按照 Event 的时间戳字段来创建文件(每小时创建一个文件夹),延迟的数据能正确归档到相应小时的文件中。
4.4 冷热数据分离
随着接入的业务增加和长期的运行时间,数据规模也越来越大。Historical 节点加载了大量 Segment 数据,观察发现大部分查询都集中在最近几天,换句话说最近几天的热数据很容易被查询到,因此数据冷热分离对提高查询效率很重要。Druid 提供了Historical 的 Tier 分组机制与数据加载 Rule 机制,通过配置能很好的将数据进行冷热分离。 首先将 Historical 群进行分组,默认的分组是"_default_tier",规划少量的 Historical 节点,使用 SATA 盘;把大量的 Historical 节点规划到 "hot" 分组,使用 SSD 盘。然后为每个 DataSource 配置加载 Rule :
- rule1: 加载1份最近30天的 Segment 到 "hot" 分组;
- rule2: 加载2份最近6个月的 Segment 到 "_default_tier" 分组;
- rule3: Drop 掉之前的所有 Segment(注:Drop 只影响 Historical 加载 Segment,Drop 掉的 Segment 在 HDFS 上仍有备份)
{"type":"loadByPeriod","tieredReplicants":{"hot":1}, "period":"P30D"}
{"type":"loadByPeriod","tieredReplicants":{"_default_tier":2}, "period":"P6M"}
{"type":"dropForever"}
提高 "hot"分组集群的 druid.server.priority 值(默认是0),热数据的查询都会落到 "hot" 分组。
4.5 监控与报警
Druid 架构中的各个组件都有很好的容错性,单点故障时集群依然能对外提供服务:Coordinator 和 Overlord 有 HA 保障;Segment 是多副本存储在HDFS/S3上;同时 Historical 加载的 Segment 和 Peon 节点摄取的实时部分数据可以设置多副本提供服务。同时为了能在节点/集群进入不良状态或者达到容量极限时,尽快的发出报警信息。和其他的大数据框架一样,我们也对 Druid 做了详细的监控和报警项,分成了2个级别:
- 基础监控
包括各个组件的服务监控、集群水位和状态监控、机器信息监控 - 业务监控
业务监控包括:实时任务创建、数据摄取 TPS、消费迟延、持久化相关、查询 RT/QPS 等的关键指标,有单个 DataSource 和全局的2种不同视图;同时这些监控项都有设置报警项,超过阈值触发报警提醒。业务指标的采集是大部分是通过 Druid 框架自身提供的 Metrics 和 Alerts 信息,然后流入到 Kafka / OpenTSDB 等组件,通过流数据分析获得我们想要的指标。
4.6 部署架构
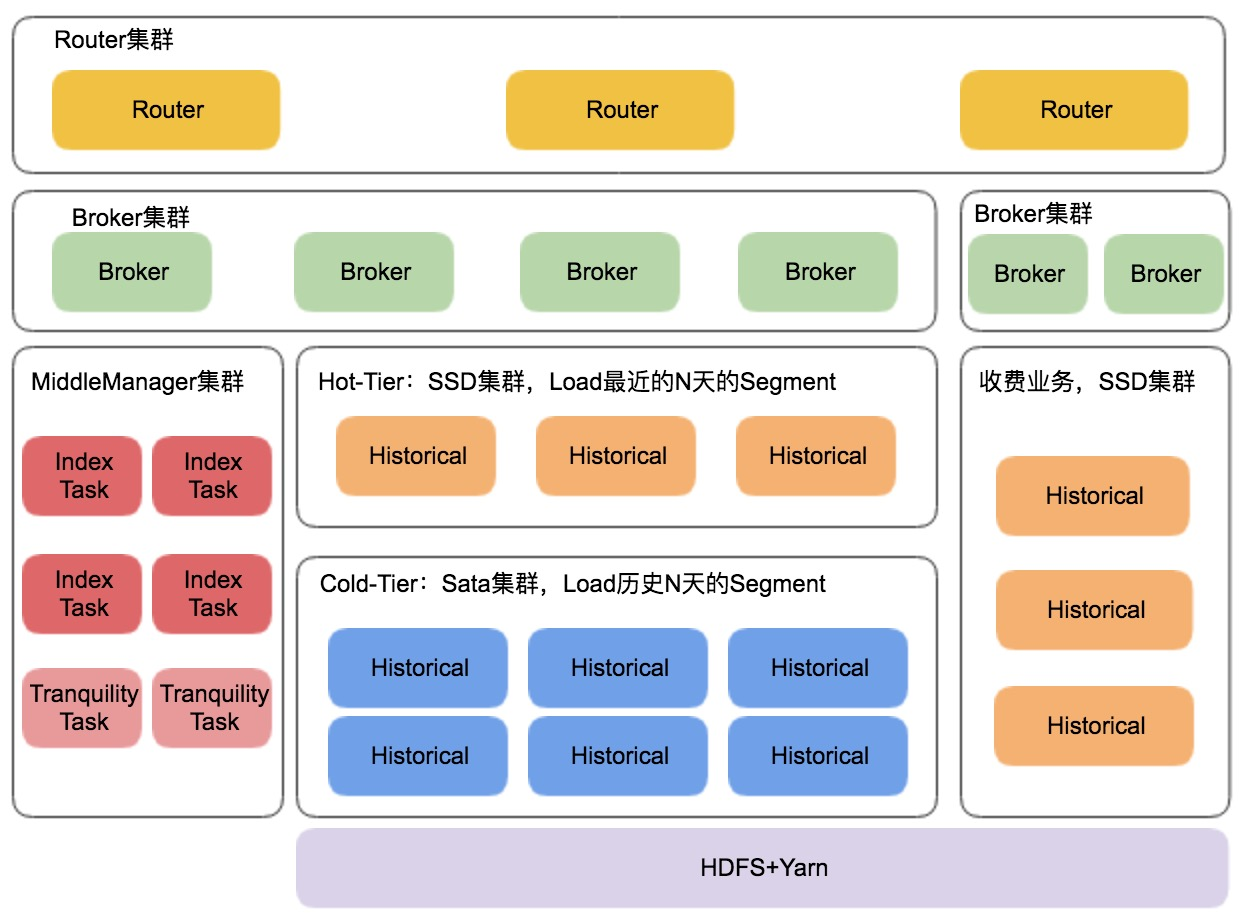
Historical 集群的部署和4.4节中描述的数据冷热分离相对应,用 SSD 集群存储最近的N天的热数据(可调节 Load 的天数),用相对廉价的 Sata 机型存储更长时间的历史冷数据,同时充分利用 Sata 的 IO 能力,把 Segment Load到不同磁盘上;在有赞有很多的收费业务,我们在硬件层面做隔离,保证这些业务在查询端有足够的资源;在接入层,使用 Router 做路由,避免了 Broker 单点问题,也能很大的程度集群查询吞吐量;在 MiddleManager 集群,除了部署有 Index 任务(内存型任务)外,我们还混合部署了部分流量高 Tranquility 任务(CPU型任务),提高了 MiddleManager 集群的资源利用率。
4.7 贡献开源社区
在有赞业务查询方式一般是 SQL On Broker/Router,我们发现一旦有少量慢查询的情况,客户端会出现查询不响应的情况,而且连接越来越难获取到。登录到Broker 的服务端后发现,可用连接数量急剧减少至被耗尽,同时出现了大量的 TCP Close_Wait。用 jstack 工具排查之后发现有 deadlock 的情况,具体的 Stack 请查看 ISSUE-6867。
经过源码排查之后发现,DruidConnection为每个 Statement 注册了回调。在正常的情况下 Statement 结束之后,执行回调函数从 DruidConnection 的 statements 中 remove 掉自己的状态;如果有慢查询的情况(超过最长连接时间或者来自客户端的Kill),connection 会被强制关闭,同时关闭其下的所有 statements ,2个线程(关闭connection的线程和正在退出 statement 的线程)各自拥有一把锁,等待对方释放锁,就会产生死锁现象,连接就会被马上耗尽。
// statement线程退出时执行的回调函数
final DruidStatement statement = new DruidStatement(
connectionId,
statementId,
ImmutableSortedMap.copyOf(sanitizedContext),
() -> {
// onClose function for the statement
synchronized (statements) {
log.debug("Connection[%s] closed statement[%s].", connectionId, statementId);
statements.remove(statementId);
}
}
);
// 超过最长连接时间的自动kill
return connection.sync(
exec.schedule(
() -> {
log.debug("Connection[%s] timed out.", connectionId);
closeConnection(new ConnectionHandle(connectionId));
},
new Interval(DateTimes.nowUtc(), config.getConnectionIdleTimeout()).toDurationMillis(),
TimeUnit.MILLISECONDS
)
);
在排查清楚问题之后,我们也向社区提了 PR-6868 。目前已经成功合并到 Master 分支中,将会 0.14.0 版本中发布。如果读者们也遇到这个问题,可以直接把该PR cherry-pick 到自己的分支中进行修复。
五、挑战和未来的展望
5.1 数据摄取系统
目前比较常用的数据摄取方案是:KafkaIndex 和 Tranquility 。我们采用的是 Tranquility 的方案,目前 Tranquility 支持了 Kafka 和 Http 方式摄取数据,摄取方式并不丰富;Tranquility 也是 MetaMarket 公司开源的项目,更新速度比较缓慢,不少功能缺失,最关键的是监控功能缺失,我们不能监控到实例的运行状态,摄取速率、积压、丢失等信息。 目前我们对 Tranquility 的实例管理支持启停,扩容缩容等操作,实现的方式和 Druid 的 MiddleManager 管理 Peon 节点是一样的。把 Tranquility 或者自研摄取工具转换成 Yarn 应用或者 Docker 应用,就能把资源调度和实例管理交给更可靠的调度器来做。
5.2 Druid 的维表 JOIN 查询
Druid 目前并不没有支持 JOIN查询,所有的聚合查询都被限制在单 DataSource 内进行。但是实际的使用场景中,我们经常需要几个 DataSource 做 JOIN 查询才能得到所需的结果。这是我们面临的难题,也是 Druid 开发团队遇到的难题。
5.3 整点查询RT毛刺问题
对于 C 端的 OLAP 查询场景,RT 要求比较高。由于 Druid 会在整点创建当前小时的 Index 任务,如果查询正好落到新建的 Index 任务上,查询的毛刺很大,如下图所示:
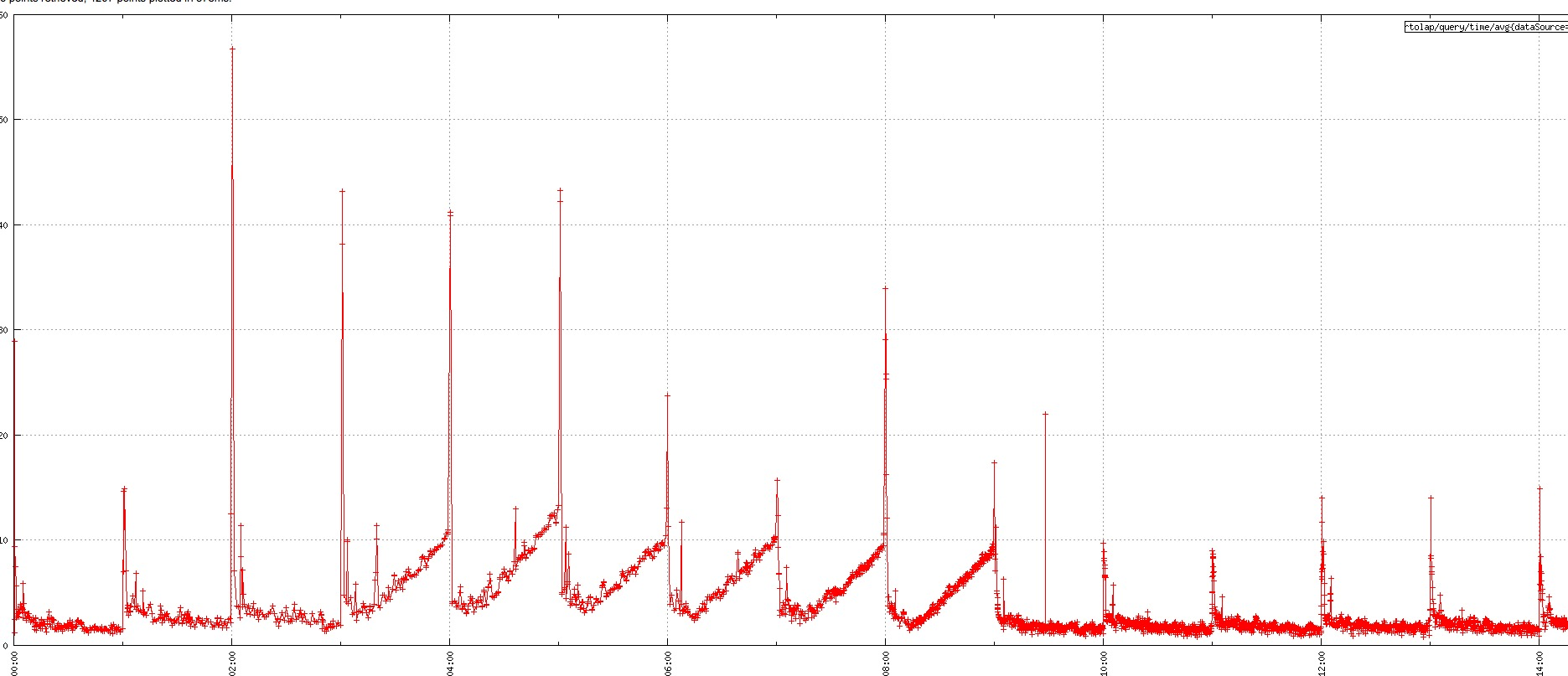
我们已经进行了一些优化和调整,首先调整 warmingPeriod 参数,整点前启动 Druid 的 Index 任务;对于一些 TPS 低,但是 QPS 很高的 DataSource ,调大 SegmentGranularity,大部分 Query 都是查询最近24小时的数据,保证查询的数据都在内存中,减少新建 Index 任务的,查询毛刺有了很大的改善。尽管如此,离我们想要的目标还是一定的差距,接下去我们去优化一下源码。
5.4 历史数据自动Rull-Up
现在大部分 DataSource 的 Segment 粒度( SegmentGranularity )都是小时级的,存储在 HDFS 上就是每小时一个Segment。当需要查询时间跨度比较大的时候,会导致Query很慢,占用大量的 Historical 资源,甚至出现 Broker OOM 的情况。如果创建一个 Hadoop-Batch 任务,把一周前(举例)的数据按照天粒度 Rull-Up 并且 重新构建 Index,应该会在压缩存储和提升查询性能方面有很好的效果。关于历史数据 Rull-Up 我们已经处于实践阶段了,之后会专门博文来介绍。
最后打个小广告,有赞大数据团队基础设施团队,主要负责有赞的数据平台 (DP), 实时计算 (Storm, Spark Streaming, Flink),离线计算 (HDFS, YARN, HIVE, SPARK SQL),在线存储(HBase),实时 OLAP (Druid) 等数个技术产品,欢迎感兴趣的小伙伴联系 zhaojiandong@youzan.com
