

以前尝试着去理解编码这个方面的内容,但是一直理不清楚,今天看廖雪峰老师的python教程看到了字符串和编码这一章,感觉终于看懂了许多,然后重新回去找以前的内容再看一次,两个内容结合在一起,发现以前那篇少了一部分的内容,导致我不懂,把这些记录下来以加深印象。
我们知道计算机世界一直是0,1来存储和传输的,然后靠着各种规则来发送,接收,编码,解码,达到了存储和传输的目的,就可以知道其表达的内容是什么意思了。各种字符编码,协议基本上就是这里说到的规则。
首先从位和字节说起,位(bit)就是用来存放二进制值的,只存放0,1。8个位即可以组成一个字节(Byte),一个位串,因为有8个bit,所以这个位串的取值有2^8 = 256种值(00000000 - 11111111),从0 - 255,0x00 - 0xFF。
由于计算机的世界最初并没有我们现在看到的各种字符,都是0和1,所以定义一种对应关系,用一个字节来表示一个字符,如 0100 0001 来代表 ‘A’ 这个字符,这样子当需要展示 0100 0001 这个内容的时候,就可以在界面上显示 A 这个形状,就达到了对应的效果了。最初制定规则时的美国人只考虑了英文大小写和数字,标点符号,所以能看到ACSII编码仅仅只包含了这些可打印字符和一些控制字符,这里的ACSII只使用了128位,最高位始终是0.
然而当计算机发展到除了美国以外的其他地方的时候,出现了更多的字符需要表示,各种字符,如日本语言,中国汉字中的内容,这时各个国家纷纷制定自己国家语言的编码,中文编码则有GB2312,GBK最为常见,由于中国汉字数量比较庞大,所以单个字节自然是无法把汉字表示完的,就增加到了用2个字节来表示,GB2312本身兼容ACSII编码,即00-7F的范围是ACSII的内容。
当不同语言采用不同编码的时候,就有可能出现了冲突和不兼容的情况,如果我完成一份文件,以中文编码的方式存储在硬盘,当这份文件传到了另一部电脑,用日文编码去读取的时候,就会发现语义是错误的,显示为日文的时候也必然是没有任何语意的一段文字,根本看不出我最开始的记录是什么内容。所以需要一个统一的编码规则,这时候便有了Unicode了,为了可以表示完全世界各种语言各种字符,Unicode采用了4个字节来表示,所以其实Unicode可以表达 2^31 21亿左右的字符,对于全世界来说是已经够用的了。Unicode的汉字例子,晴 这个字,为 \u6674 ,所以存储到下来应该是 00000000 00000000 01100110 01110100 。
Unicode是有了,但是字节数太多了,如果只使用英文的话,那么对存储空间或者网络是极大的浪费,Unicode兼容ACSII,所以当只使用英文的时候,将浪费很多的空间,其实中文也是有这样的问题。而如果使用变长,那么将导致一个4字节的串,将表示成一个Unicode字符还是4个Unicode字符。于是便有了UTF-8这种对Unicode的实现。
UTF-8的的规则有两条:
规则1:对于单字节字符,字节的第一位为0,后7位为这个符号的Unicode码,所以对于拉丁字母,UTF-8与ASCII码是一致的。
规则2:对于n字节(n>1)的字符,第一个字节前n位都设为1,第n+1位为0,后面字节的前两位一律设为10,剩下没有提及的位,全部为这个符号的Unicode编码。
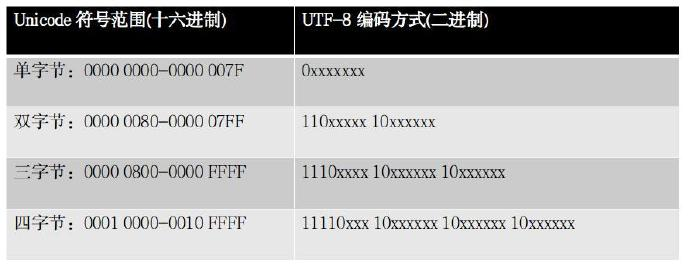
于是上述的 晴 字,由于在三字节的范围中,所以其UTF-8编码为 11100110 10011001 10110100。
理清楚了Unicode,UTF-8,ACSII各种编码之间的关系,描述一下在计算机系统中字符编码的工作方式能更好地去理解这些内容,在内存中,是统一使用Unicode编码的,当需要存储下来或者需要传输的时候,就将这些内容转换成其他的编码方式,目前最常用的是UTF-8。我们打开一个空白的文件,往里面写入内容的时候,便是使用的Unicode,当我们将它保存的时候,如果指定了UTF-8,那么就转换成UTF-8的编码存储,下次打开的时候就以UTF-8的方式打开,而不能使用其他的不兼容的方式,否则将导致乱码。网络传输也是相同的道理。
以上的内容大部分来自于这个地方(可惜了,原文看不到了),然而我看完了之后却有种似懂非懂的感觉,但是也没办法找到更好的文章,于是暂时放弃了,直到后来看到了廖雪峰老师python教程中的一节, 当初没理解的点也就在于没法和实际结合起来,廖老师算是解了我这个困惑了,在此膜拜一下。
