

环境安装
# Node Version Manager
$ curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.34.0/install.sh | bash
$ nvm ls
-> system
iojs -> N/A (default)
node -> stable (-> N/A) (default)
unstable -> N/A (default)
$ brew install expressjs
$ express --version
4.16.0
# npm命令提供更清晰直观的显示:
$ npm list
Hello world
$ mkdir lesson1 && cd lesson1
$ npm install express --registry=https://registry.npm.taobao.org
$ ls node_modules
$ touch app.js
Hello world 代码:
// 这句的意思就是引入 `express` 模块,并将它赋予 `express` 这个变量等待使用。
var express = require('express');
// 调用 express 实例,它是一个函数,不带参数调用时,会返回一个 express 实例,将这个变量赋予 app 变量。
var app = express();
// app 本身有很多方法,其中包括最常用的 get、post、put/patch、delete,在这里我们调用其中的 get 方法,为我们的 `/` 路径指定一个 handler 函数。
// 这个 handler 函数会接收 req 和 res 两个对象,他们分别是请求的 request 和 response。
// request 中包含了浏览器传来的各种信息,比如 query 啊,body 啊,headers 啊之类的,都可以通过 req 对象访问到。
// res 对象,我们一般不从里面取信息,而是通过它来定制我们向浏览器输出的信息,比如 header 信息,比如想要向浏览器输出的内容。这里我们调用了它的 #send 方法,向浏览器输出一个字符串。
app.get('/', function (req, res) {
res.send('Hello World');
});
// 定义好我们 app 的行为之后,让它监听本地的 3000 端口。这里的第二个函数是个回调函数,会在 listen 动作成功后执行,我们这里执行了一个命令行输出操作,告诉我们监听动作已完成。
app.listen(3000, function () {
console.log('app is listening at port 3000');
});
$ node app.js # 运行
req.query用法,package.json用法:
- 目标:访问 http://localhost:3000/?q=alsotang 时,输出 alsotang 的 sha1 值,即 e3c766d71667567e18f77869c65cd62f6a1b9ab9。
这个 package.json 文件就是定义了项目的各种元信息,包括项目的名称,git repo 的地址,作者等等。最重要的是,其中定义了我们项目的依赖,这样这个项目在部署时,我们就不必将 node_modules 目录也上传到服务器,服务器在拿到我们的项目时,只需要执行 npm install,则 npm 会自动读取 package.json 中的依赖并安装在项目的 node_modules 下面,然后程序就可以在服务器上跑起来了。
$ npm init
# 交互初始化一个package.json文件
$ npm install express utility --save
# 没有指定 registry 的情况下,默认从 npm 官方安装,上次我们是从淘宝的源安装的。多了个 --save 参数,这个参数的作用,就是会在你安装依赖的同时,自动把这些依赖写入 package.json。这时查看 node_modules 目录,会发现有两个文件夹,分别是 express 和 utility。
// 引入依赖
var express = require('express');
var utility = require('utility');
// 建立 express 实例
var app = express();
app.get('/', function (req, res) {
// 从 req.query 中取出我们的 q 参数。
// 如果是 post 传来的 body 数据,则是在 req.body 里面,不过 express 默认不处理 body 中的信息,需要引入 https://github.com/expressjs/body-parser 这个中间件才会处理,这个后面会讲到。
// 如果分不清什么是 query,什么是 body 的话,那就需要补一下 http 的知识了
var q = req.query.q;
// 调用 utility.md5 方法,得到 md5 之后的值
// 之所以使用 utility 这个库来生成 md5 值,其实只是习惯问题。每个人都有自己习惯的技术堆栈,
// 我刚入职阿里的时候跟着苏千和朴灵混,所以也混到了不少他们的技术堆栈,仅此而已。
// utility 的 github 地址:https://github.com/node-modules/utility
// 里面定义了很多常用且比较杂的辅助方法,可以去看看
var md5Value = utility.md5(q);
res.send(md5Value);
});
app.listen(3000, function (req, res) {
console.log('app is running at port 3000');
});
使用 superagent 抓取网页,使用 cheerio 分析网页
- 目标:当在浏览器中访问 http://localhost:3000/ 时,输出 CNode(cnodejs.org/ ) 社区首页的所有帖子标题和链接,以 json 的形式。
superagent(visionmedia.github.io/superagent/ ) 是个 http 方面的库,可以发起 get 或 post 请求。cheerio(github.com/cheeriojs/c… ) 大家可以理解成一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一样一样的。
const express = require('express');
const utility = require('utility');
const superagent = require('superagent');
const cheerio = require('cheerio');
const app = express();
app.get('/', function (req, res) {
superagent.get('https://cnodejs.org/').end(function (err, sres) {
if (err) { // 错误处理
return next(err);
}
var $ = cheerio.load(sres.text);
var items = [];
// // sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后
// 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$`
// 剩下就都是 jquery 的内容了
$('#topic_list .topic_title').each(function (idx, element) {
var $element = $(element);
items.push({
title: $element.attr('title'),
href: $element.attr('href')
});
});
res.send(items);
})
})
app.listen(3000, function () {
console.log('listen on port 3000...')
})
异步并发
eventproxy 提供了不少其他场景所需的 API,但最最常用的用法就是以上的这种,即: 先 var ep = new eventproxy(); 得到一个 eventproxy 实例。 告诉它你要监听哪些事件,并给它一个回调函数。ep.all('event1', 'event2', function (result1, result2) {})。 在适当的时候 ep.emit('event_name', eventData)。 eventproxy 相关学习链接
var eventproxy = require('eventproxy');
var superagent = require('superagent');
var cheerio = require('cheerio');
var url = require('url');
var cnodeUrl = 'https://cnodejs.org/';
superagent.get(cnodeUrl).end((err, res) => {
if (err) {
console.error(err);
return
}
const topicUrl = [];
const $ = cheerio.load(res.text);
// console.log('toplist = ',$('#topic_list .topic_title'))
$('#topic_list .topic_title').each((id, element) => {
const $element = $(element);
// console.log($element);
const href = url.resolve(cnodeUrl, $element.attr('href'));
topicUrl.push(href);
});
const ep = new eventproxy();
//after方法适合重复的操作,比如读取10个文件,调用5次数据库等。将handler注册到N次相同事件的触发上。达到指定的触发数,handler将会被调用执行,每次触发的数据,将会按触发顺序,存为数组作为参数传入。
ep.after('topic_html', topicUrl.length, (topics) => {
topics = topics.map((pairs) => {
const topicUrl = pairs[0];
const topicHtml = pairs[1];
const $ = cheerio.load(topicHtml);
return ({
title: $('.topic_full_title').text().trim(),
href: topicUrl,
comment: $('.reply_content').eq(0).text().trim()
});
});
console.log('topics = ', topics);
});
topicUrl.map((url) => {
superagent.get(url).end((err, res) => {
ep.emit('topic_html', [url, res.text]);
});
});
});
使用 async 来控制并发连接数。
async demo。什么时候用 eventproxy,什么时候使用 async 呢?它们不都是用来做异步流程控制的吗? 我的答案是: 当你需要去多个源(一般是小于 10 个)汇总数据的时候,用 eventproxy 方便;当你需要用到队列,需要控制并发数,或者你喜欢函数式编程思维时,使用 async。大部分场景是前者,所以我个人大部分时间是用 eventproxy 的。
除了async 的 mapLimit(arr, limit, iterator, callback) 接口,还有个常用的控制并发连接数的接口是 queue(worker, concurrency),大家可以去 github.com/caolan/asyn… 看看说明。
const async = require('async');
const baiduurl = 'https://www.baidu.com/';
var concurrencyCount = 0;
fetchUrl = (url, callback) => {
const delay = parseInt((Math.random() * 10000000) % 2000, 10);
concurrencyCount++;
console.log('现在并发数', concurrencyCount, ', 正抓取', url, ', 耗时 ', delay, '毫秒');
setTimeout(() => {
concurrencyCount--;
callback(null, url + ' html content'); // 第一个项是错误,第二个是对象
}, delay);
};
const urls = [];
for (var i = 0; i < 20; i++) {
urls.push(baiduurl + '_' + i);
}
/**
* mapLimit(coll, limit, iteratee, callback opt)
* coll: 要迭代的集合
* limit: 一次异步操作最大数量
* iteratee:对于coll中每一个item,迭代执行该函数,用(item,callback)调用,callback可选 。
* callback:所有iteratee 函数完成后或发生错误时触发的回调函数。用(err, results)调用。results可以是iteratee 函数完成后触发callback时传递的项。
*/
async.mapLimit(urls, 5, (url, callback) => {
fetchUrl(url, callback)
}, (err, result) => { // 所有都执行完才会执行
console.log('result = ', result);
})
《测试用例:mocha,should,istanbul》
- 学习使用测试框架 mocha : mochajs.org/
- 学习使用断言库 should : github.com/tj/should.j…
- 学习使用测试率覆盖工具 istanbul : github.com/gotwarlost/…
- 简单 Makefile 的编写 : blog.csdn.net/haoel/artic…
# 装个全局的 mocha:
$ npm install mocha -g。
# -g 与 非-g 的区别,就是安装位置的区别,g 是 global 的意思。如果不加的话,则安装 mocha 在你的项目目录下面;如果加了,则这个 mocha 是安装在全局的,如果 mocha 有可执行命令的话,那么这个命令也会自动加入到你系统 $PATH 中的某个地方(在我的系统中,是这里 /Users/alsotang/.nvm/v0.10.29/bin)
// app.js
fibonacci = (n) => {
if (n === 0) return 0;
if (n === 1) return 1;
return this.fibonacci(n - 1) + this.fibonacci(n - 2);
};
if (require.main === module) {
var n = Number(process.argv(2));
console.log('fibonacci(', n, ') is ', fibonacci(n));
}
exports.fibonacci = fibonacci
// test/main.test.js
var main = require('../app');
var should = require('should');
describe('test/main.test.js', () => {
it('should equal 55 when n === 10', () => {
main.fibonacci(10).should.equal(55);
});
it('show equal 1 when n === 1', () => {
main.fibonacci(1).should.equal(1);
});
it('show equal 0 when n ===0 ', () => {
main.fibonacci(0).should.equal(0);
});
it('should throw then n is not a number', () => {
(() => { main.fibonacci('哎呀') }).should.throw('n should be a Number');
});
});
# 进入到项目根目录
$ mocha
test/main.test.js
✓ should equal 55 when n === 10
✓ show equal 1 when n === 1
✓ show equal 0 when n ===0
1) should throw then n is not a number
前端脚本单元测试
运行环境应当在浏览器中,可以操纵浏览器的DOM对象,且可以随意定义执行时的 html 上下文。 测试结果应当可以直接反馈给 mocha,判断测试是否通过。
《正则表达式》
var web_development = "python php ruby javascript jsonp perhapsphpisoutdated";
找出其中 包含 p 但不包含 ph 的所有单词,即
[ 'python', 'javascript', 'jsonp' ]
知识点
- 正则表达式的使用
- js 中的正则表达式与 pcre(en.wikipedia.org/wiki/Perl_C… ) 的区别
课程内容
开始这门课之前,大家先去看两篇文章。
《正则表达式30分钟入门教程》:www.cnblogs.com/deerchao/ar…
上面这篇介绍了正则表达式的基础知识,但是对于零宽断言没有展开来讲,零宽断言看下面这篇:
《正则表达式之:零宽断言不『消费』》:fxck.it/post/505582… 好了。
在很久很久以前,有一门语言一度是字符串处理领域的王者,叫 perl。 伴随着 perl,有一个类似正则表达式的标准被实现了出来,叫 pcre:Perl Compatible Regular Expressions.不过遗憾的是,js 里面的正则与 pcre 不是兼容的。很多语言都这样。如果需要测试你自己写的正则表达式,建议上这里:refiddle.com/ ,可以所见即所得地调试 。接下来我们主要讲讲 js 中需要注意的地方,至于正则表达式的内容,上面那两篇文章足够学习了。
第一,js 中,对于四种零宽断言,只支持 零宽度正预测先行断言 和 零宽度负预测先行断言 这两种。
第二,js 中,正则表达式后面可以跟三个 flag,比如 /something/igm。他们的意义分别是,
- i 的意义是不区分大小写
- g 的意义是,匹配多个
- m 的意义是,是
^和$可以匹配每一行的开头。
分别举个例子:
/a/.test('A') // => false
/a/i.test('A') // => true
'hello hell hoo'.match(/h.*?\b/) // => [ 'hello', index: 0, input: 'hello hell hoo' ]
'hello hell hoo'.match(/h.*?\b/g) // => [ 'hello', 'hell', 'hoo' ]
'aaa\nbbb\nccc'.match(/^[\s\S]*?$/g) // => [ 'aaa\nbbb\nccc' ]
'aaa\nbbb\nccc'.match(/^[\s\S]*?$/gm) // => [ 'aaa', 'bbb', 'ccc' ]
与 m 意义相关的,还有 \A, \Z 和 \z。他们的意义分别是:
\A 字符串开头(类似^,但不受处理多行选项的影响)
\Z 字符串结尾或行尾(不受处理多行选项的影响)
\z 字符串结尾(类似$,但不受处理多行选项的影响)
在 js 中,g flag 会影响 String.prototype.match() 和 RegExp.prototype.exec() 的行为
String.prototype.match() 中,返回数据的格式会不一样,加 g 会返回数组,不加 g 则返回比较详细的信息
> 'hello hell'.match(/h(.*?)\b/g)
[ 'hello', 'hell' ]
> 'hello hell'.match(/h(.*?)\b/)
[ 'hello',
'ello',
index: 0,
input: 'hello hell' ]
RegExp.prototype.exec() 中,加 g 之后,如果你的正则不是字面量的正则,而是存储在变量中的话,特么的这个变量就会变得有记忆!!
> /h(.*?)\b/g.exec('hello hell')
[ 'hello',
'ello',
index: 0,
input: 'hello hell' ]
> /h(.*?)\b/g.exec('hello hell')
[ 'hello',
'ello',
index: 0,
input: 'hello hell' ]
> var re = /h(.*?)\b/g;
undefined
> re.exec('hello hell')
[ 'hello',
'ello',
index: 0,
input: 'hello hell' ]
> re.exec('hello hell')
[ 'hell',
'ell',
index: 6,
input: 'hello hell' ]
>
第三,大家知道,. 是不可以匹配 \n 的。如果我们想匹配的数据涉及到了跨行,比如下面这样的。
var multiline = require('multiline');
var text = multiline.stripIndent(function () {
/*
head
```
code code2 .code3```
```
foot
*/
});
如果我们想把两个 ``` 中包含的内容取出来,应该怎么办?直接用 . 匹配不到 \n,所以我们需要找到一个原子,能匹配包括 \n 在内的所有字符。这个原子的惯用写法就是 [\s\S]
var match1 = text.match(/^```[\s\S]+?^```/gm);
console.log(match1) // => [ '```\ncode code2 code3```\n```' ]
// 这里有一种很骚的写法,[^] 与 [\s\S] 等价
var match2 = text.match(/^```[^]+?^```/gm)
console.log(match2) // => [ '```\ncode code2 .code3```\n```' ]
var let
内部函数可以访问外部函数的变量,外部函数不能访问内部函数变量。
如果不用var来声明,则默认为全局变量了,如下面value值。let 为es6的块级作用域。
var parent = function () {
var name = "parent_name";
var age = 13;
var child = function () {
var name = "child_name";
var childAge = 0.3;
// => child_name 13 0.3
console.log(name, age, childAge);
};
child();
// will throw Error
// ReferenceError: childAge is not defined
console.log(name, age, childAge);
};
parent();
function foo() {
value = "hello";
}
foo();
console.log(value); // 输出hello
console.log(global.value) // 输出hello
// js 中,函数中声明的变量在整个函数中都有定义。比如如下代码段,变量 i 和 value 虽然是在 for 循环代码块中被定义,但在代码块外仍可以访问 i 和 value。
function foo() {
for (var i = 0; i < 10; i++) {
var value = "hello world";
}
console.log(i); //输出10
console.log(value);//输出hello world
}
foo();
闭包
闭包这个概念,在函数式编程里很常见,简单的说,就是使内部函数可以访问定义在外部函数中的变量。
var adder = (x) => {
let base = x;
return (n) => {
return base + n;
};
};
var add10 = adder(10);
console.log(add10(5));
// 每次调用 adder 时,adder 都会返回一个函数给我们。我们传给 adder 的值,会保存在一个名为 base 的变量中。由于返回的函数在其中引用了 base 的值,于是 base 的引用计数被 +1。当返回函数不被垃圾回收时,则 base 也会一直存在。如果想深入理解这块,可以看看这篇 http://coolshell.cn/articles/6731.html
// 闭包的一个坑
for (var i = 0; i < 5; i++) {
setTimeout(function () {
console.log(i);
}, 5);
}
// 上面这个代码块会打印五个 5 出来,而我们预想的结果是打印 0 1 2 3 4. 之所以会这样,是因为 setTimeout 中的 i 是对外层 i 的引用。当 setTimeout 的代码被解释的时候,运行时只是记录了 i 的引用,而不是值。而当 setTimeout 被触发时,五个 setTimeout 中的 i 同时被取值,由于它们都指向了外层的同一个 i,而那个 i 的值在迭代完成时为 5,所以打印了五次 5。 为了得到我们预想的结果,我们可以把 i 赋值成一个局部的变量,从而摆脱外层迭代的影响。
for (var i = 0; i < 5; i++) {
(function (idx) {
setTimeout(function () {
console.log(idx);
}, 5);
})(i);
}
this
在函数执行时,this 总是指向调用该函数的对象。要判断 this 的指向,其实就是判断 this 所在的函数属于谁。
在《javaScript语言精粹》这本书中,把 this 出现的场景分为四类,简单的说就是:
- 有对象就指向调用对象
- 没调用对象就指向全局对象
- 用new构造就指向新对象
- 通过 apply 或 call 或 bind 来改变 this 的所指。
1)函数有所属对象时:指向所属对象
函数有所属对象时,通常通过 . 表达式调用,这时 this 自然指向所属对象。比如下面的例子:
var myObject = {value: 100};
myObject.getValue = function () {
console.log(this.value); // 输出 100
// 输出 { value: 100, getValue: [Function] },
// 其实就是 myObject 对象本身
console.log(this);
return this.value;
};
console.log(myObject.getValue()); // => 100
getValue() 属于对象 myObject,并由 myOjbect 进行 . 调用,因此 this 指向对象 myObject。
- 函数没有所属对象:指向全局对象
var myObject = {value: 100};
myObject.getValue = function () {
var foo = function () {
console.log(this.value) // => undefined
console.log(this);// 输出全局对象 global
};
foo();
return this.value;
};
console.log(myObject.getValue()); // => 100
在上述代码块中,foo 函数虽然定义在 getValue 的函数体内,但实际上它既不属于 getValue 也不属于 myObject。foo 并没有被绑定在任何对象上,所以当调用时,它的 this 指针指向了全局对象 global。
据说这是个设计错误。
3)构造器中的 this:指向新对象
js 中,我们通过 new 关键词来调用构造函数,此时 this 会绑定在该新对象上。
var SomeClass = function(){
this.value = 100;
}
var myCreate = new SomeClass();
console.log(myCreate.value); // 输出100
顺便说一句,在 js 中,构造函数、普通函数、对象方法、闭包,这四者没有明确界线。界线都在人的心中。
- apply 和 call 调用以及 bind 绑定:指向绑定的对象
apply() 方法接受两个参数第一个是函数运行的作用域,另外一个是一个参数数组(arguments)。
call() 方法第一个参数的意义与 apply() 方法相同,只是其他的参数需要一个个列举出来。
简单来说,call 的方式更接近我们平时调用函数,而 apply 需要我们传递 Array 形式的数组给它。它们是可以互相转换的。
var myObject = {value: 100};
var foo = function(){
console.log(this);
};
foo(); // 全局变量 global
foo.apply(myObject); // { value: 100 }
foo.call(myObject); // { value: 100 }
var newFoo = foo.bind(myObject);
newFoo(); // { value: 100 }
线上部署:heroku
将 github.com/Ricardo-Li/… (这个项目已经被删了。参照 github.com/alsotang/no… 的代码自己操作一下吧。)这个项目部署上 heroku,成为一个线上项目
我部署的在这里 serene-falls-9294.herokuapp.com
- 学习 heroku 的线上部署
什么是 heroku
heroku 是弄 ruby 的 paas 起家,现在支持多种语言环境,更甚的是它强大的 add-on 服务。 paas 平台相信大家都不陌生。Google 有 gae,国内新浪有 sae。paas 平台相对 vps 来说,不需要你配置服务器,不需要装数据库,也不需要理会负载均衡。这一切都可以在平台上直接获取。你只要专注自己的业务,把应用的逻辑写好,然后发布上去,应用自然就上线了。数据库方面,如果你用 mysql,那么你可以从平台商那里得到一个 mysql 的地址、账号和密码,直接连接就能用。如果应用的流量增大,需要横向拓展,则只用去到 paas 平台的管理页面,增大服务器实例的数量即可,负载均衡会自动帮你完成。
说起来,我之所以对于 web 开发产生兴趣也是因为当年 gae 的关系。那时候除了 gae 之外,没有别的 paas 平台,gae 是横空出世的。有款翻墙的软件,叫 gappproxy(code.google.com/p/gappproxy… )——可以认为是 goagent 的前身——就是搭建在 gae 上面的,不仅快,而且免费。于是我就很想弄懂这样一个程序是如何开发的。好在 gappproxy 是开源的,于是我下了源码来看,那时候才大一,只学过 c,看到那些 python 代码就凌乱了。于是转头也去学 python,后来渐渐发现了 web 开发的乐趣,于是 ruby 和 node.js 也碰碰。后来 goagent 火起来了,我又去看了看它的代码,发现非常难看,就自己写了个 github.com/alsotang/ke… 。不过现在回想起来,还是 goagent 的实现比较稳定以及效率高。
heroku 的免费额度还是足够的,对于 demo 应用来说,放上去是绰绰有余的。各位搞 web 开发的大学生朋友,一定要试着让你开发的项目尽可能早地去线上跑,这样你的项目可以被其他人看到,能够促使你更有热情地进行进一步开发。这回我们放的是 cnode 社区的爬虫上去,你其实可以试着为你们学院或者学校的新闻站点写个爬虫,提供 json api,然后去申请个微信公共平台,每天推送学院网站的新闻。这东西辅导员是有需求的,可以做个给他们用。
好了,我们先 clone github.com/Ricardo-Li/… 这个项目。由于我们这回讲部署,所以代码就用现成的了,代码的内容就是 lesson 3(github.com/alsotang/no… ) 里面的那个爬虫。

clone 下来以后,我们去看看代码。代码中有两个特殊的地方,
一个是一个叫 Procfile 的文件,内容是:
web: node app.js
一个是 app.js 里面,
app.listen(process.env.PORT || 5000);
这两者都是为了部署 heroku 所做的。
大家有没有想过,当部署一个应用上 paas 平台以后,paas 要为我们干些什么?
首先,平台要有我们语言的运行时;
然后,对于 node.js 来说,它要帮我们安装 package.json 里面的依赖;
然后呢?然后需要启动我们的项目;
然后把外界的流量导入我们的项目,让我们的项目提供服务。
上面那两处特殊的地方,一个是启动项目的,一个是导流量的。
heroku 虽然能推测出你的应用是 node.js 应用,但它不懂你的主程序是哪个,所以我们提供了 Procfile 来指导它启动我们的程序。
而我们的程序,本来是监听 5000 端口的,但是 heroku 并不知道。当然,你也可以在 Procfile 中告诉 heroku,可如果大家都监听 5000 端口,这时候不就有冲突了吗?所以这个地方,heroku 使用了主动的策略,主动提供一个环境变量 process.env.PORT 来供我们监听。
这样的话,一个简单 app 的配置就完成了。
我们去 www.heroku.com/ 申请个账号,然后下载它的工具包 toolbelt.heroku.com/ ,然后再在命令行里面,通过 heroku login 来登录。
上述步骤完成后,我们进入 node-practice-2 的目录,执行 heroku create。这时候,heroku 会为我们随机取一个应用名字,并提供一个 git 仓库给我们。
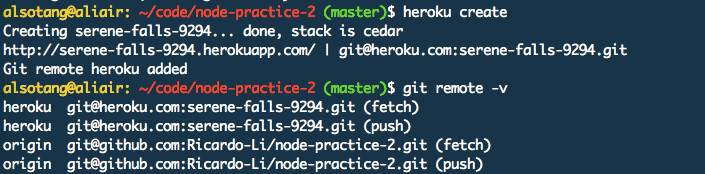
接着,往 heroku 这个远端地址推送我们的 master 分支:
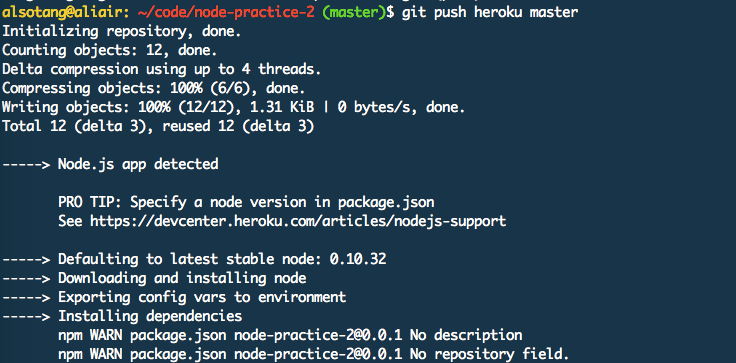
heroku 会自动检测出我们是 node.js 程序,并安装依赖,然后按照 Procfile 进行启动。
push 完成后,在命令键入 heroku open,则 heroku 会自动打开浏览器带我们去到相应的网址:
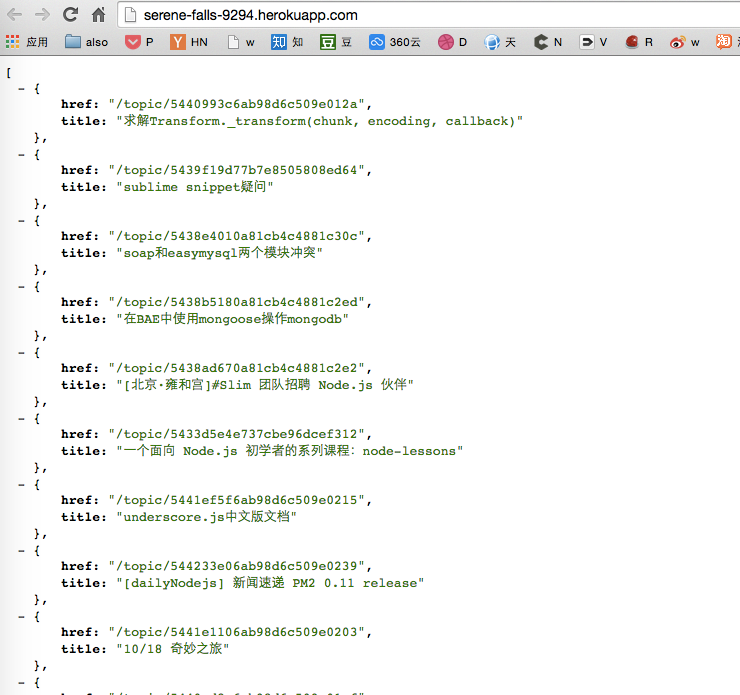
到此课程也就结束了。
随便聊聊 heroku 的 addon 吧。这个 addon 确实是个神奇的东西,反正在 heroku 之外我还没怎么见到这类概念。这些 addon 提供商,有些提供 redis 的服务,有些提供 mongodb,有些提供 mysql。你可以直接在 heroku 上面进行购买,然后 heroku 就会提供一段相应服务的地址和账号密码给你用来连接。
大家可以去 addons.heroku.com/ 这个页面看看,玲琅满目各种应用可以方便接入。之所以这类服务有市场,也是因为亚马逊的 aws 非常牛逼。为什么这么说呢,因为网络速度啊。如果现在在国内,你在 ucloud 买个主机,然后用个阿里云的 rds,那么应用的响应速度会因为 mysql 连接的问题卡得动不了。但在 heroku 这里,提供商们,包括 heroku 自己,都是构建在 aws 上面,这样一来,各种服务的互通其实走的是内网,速度很可以接受,于是各种 addon 提供商就做起来了。
国内的话,其实在阿里云上面也可以考虑这么搞一搞。
$ brew tap heroku/brew && brew install heroku
$ heroku login -i
heroku: Enter your login credentials
Email: me@example.com
Password: ***************
Two-factor code: ********
Logged in as me@heroku.com
# CLI会保存您的电子邮件地址和API令牌以~/.netrc供将来使用
$ cd ~/myapp
$ heroku create
Creating app... done, ⬢ arcane-gorge-86957
https://arcane-gorge-86957.herokuapp.com/ | https://git.heroku.com/arcane-gorge-86957.git
# 初始化并关联
$ cd lesson
$ git init
$ heroku login # 加 -i 就不打开web登陆了
$ heroku git:remote -a arcane-gorge-86957
$ git add .
$ git commit -am 'first commit'
$ git push heroku master
$ heroku open
# 本地clone修改
$ heroku login
$ heroku git:clone -a arcane-gorge-86957
$ cd arcane-gorge-86957
$ git add .
$ git commit -am "make it better"
$ git push heroku master
mongo 添加用户
$ mongo
$ db.createUser({
user:"admin",
pwd:"admin",
roles:[{
role:"userAdminAnyDatabase",
db:"admin"
}]
});
导入数据:
$ mongoimport --db blog --collotion blog --file ~/Download/blog/aa.json
$ mongorestore -d blog ~/Downloads/blog/
