1. document数据路由原理
1.1 document路由到shard上是什么意思?
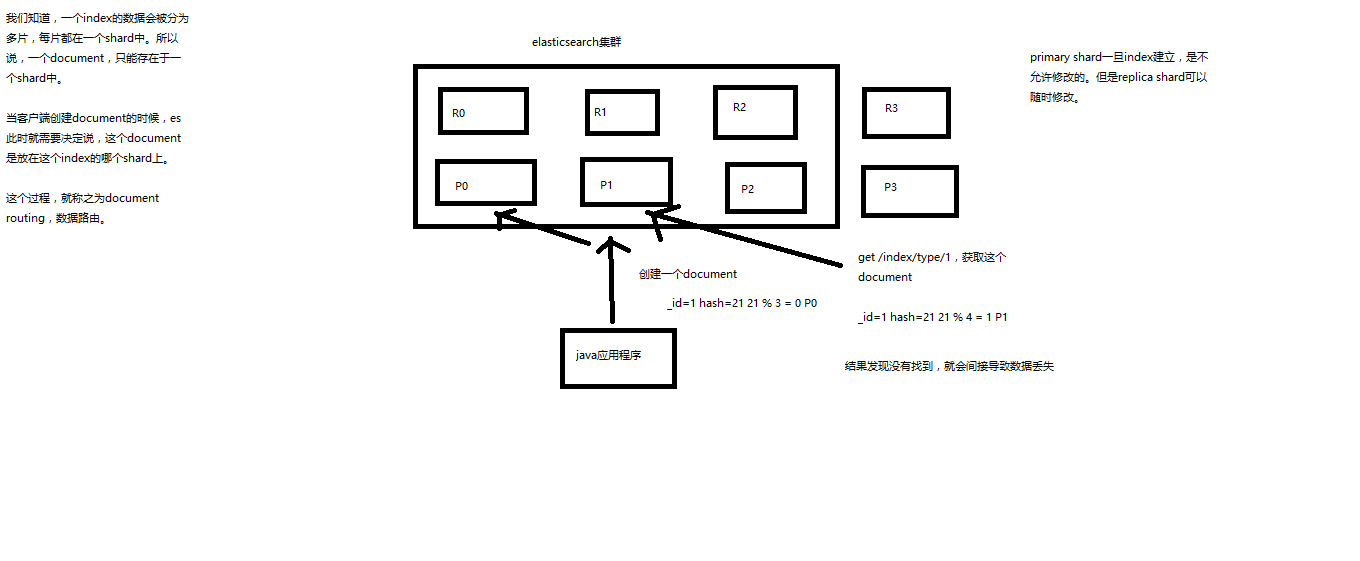
一个index的数据会被分为多片,每片都在一个shard中。所以说,一个document,只能存在于一个shard中。
当客户端创建document的时候,es此时就需要决定说,这个document是放在这个index的哪个shard上。
这个过程,就称之为document routing, 数据路由。
1.2. 路由算法
shard = hash(routing) % number_of_primary_shards
举例说明:
- 一个index有3个primary shard,P0,P1,P2
- 每次增删改查一个document的时候,都会带过来一个routing number,默认就是这个document的_id(可能是手动指定,也可能是自动生成)
routing = _id,假设_id=1 - 会将这个routing值,传入一个hash函数中,产出一个routing值的hash值,假设hash(routing) = 21 然后将hash函数产出的值对这个index的primary shard的数量求余数,21 % 3 = 0 就决定了,这个document就放在P0上。 - 决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的
无论hash值是几,无论是什么数字,对number_of_primary_shards求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的。0,1,2。
1.3 手动指定 routing id
- 默认的routing就是_id,也可以在发送请求的时候,手动指定一个routing value,比如说
put /index/type/id?routing=user_id - 手动指定routing value是很有用的,可以保证说,某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的
1.4 primary shard 数量不可变的原理
-
根据路由算法中的例子,当document的_id为1时,计算出的结果为0,就是在P0 shard 上。
-
如果增加一个primary shard,变为4个,_id=1, 则计算出来的结果为 21 % 4 = 1,就去P1 shard 上找这条数据,结果就会找不到,间接导致数据丢失。
2. document增删改内部实现原理
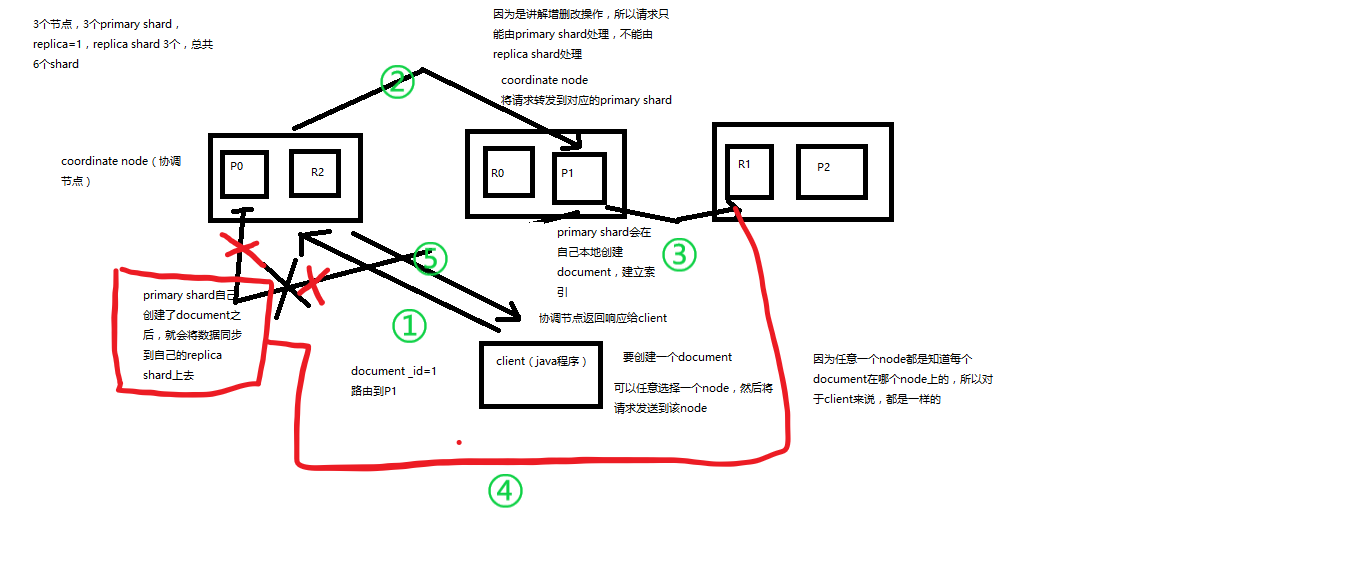
首先,增删改操作只能有 primary shard 处理,不能由 replica sahrd处理。
具体步骤:
-
客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
-
coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
-
实际的node上的primary shard处理请求,然后将数据同步到replica node
-
coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
3. document写一致性原理及quorum机制
3.1 consistency,one(primary shard),all(all shard),quorum(default)
我们在发送任何一个增删改操作的时候,比如说put /index/type/id,都可以带上一个consistency参数,指明我们想要的写一致性是什么? put /index/type/id?consistency=quorum
- one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行
- all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
- quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
3.2 quorum机制
-
quorum机制,写之前必须确保大多数shard都可用,int( (primary + number_of_replicas) / 2 ) + 1,当number_of_replicas>1时才生效
quroum = int( (primary + number_of_replicas) / 2 ) + 1
举个例子,3个primary shard,number_of_replicas=1,总共有3 + 3 * 1 = 6个shard, quorum = int( (3 + 1) / 2 ) + 1 = 3 所以,要求6个shard中至少有3个shard是active状态的,才可以执行这个写操作
-
如果节点数少于quorum数量,可能导致quorum不齐全,进而导致无法执行任何写操作
此处有一个问题:
es提供了一种特殊的处理场景,就是说当number_of_replicas>1时才生效,因为假如说,你就一个primary shard,replica=1,此时就2个shard (1 + 1)/2 + 1 = 2,要求必须有2个shard是活跃的,但是可能就1个node,此时就1个shard是活跃的,如果你不特殊处理的话,导致我们的单节点集群就无法工作
我在自己的机器上启动了一个节点,新建索引如下:
PUT /quorum_test { "settings": { "number_of_shards": 1, "number_of_replicas": 1 } }增加一条数据,成功了:
PUT /quorum_test/type/1 { "field1": "test" } 返回: { "_index": "quorum_test", "_type": "type", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "created": true }按照上面说的应该失败才对,不知道为什么?
-
quorum不齐全时,wait,默认1分钟,timeout,100,30s
等待期间,期望活跃的shard数量可以增加,最后实在不行,就会timeout 我们其实可以在写操作的时候,加一个timeout参数,比如说
put /index/type/id?timeout=30,这个就是说自己去设定quorum不齐全的时候,es的timeout时长,可以缩短,也可以增长
4. document 查询原理
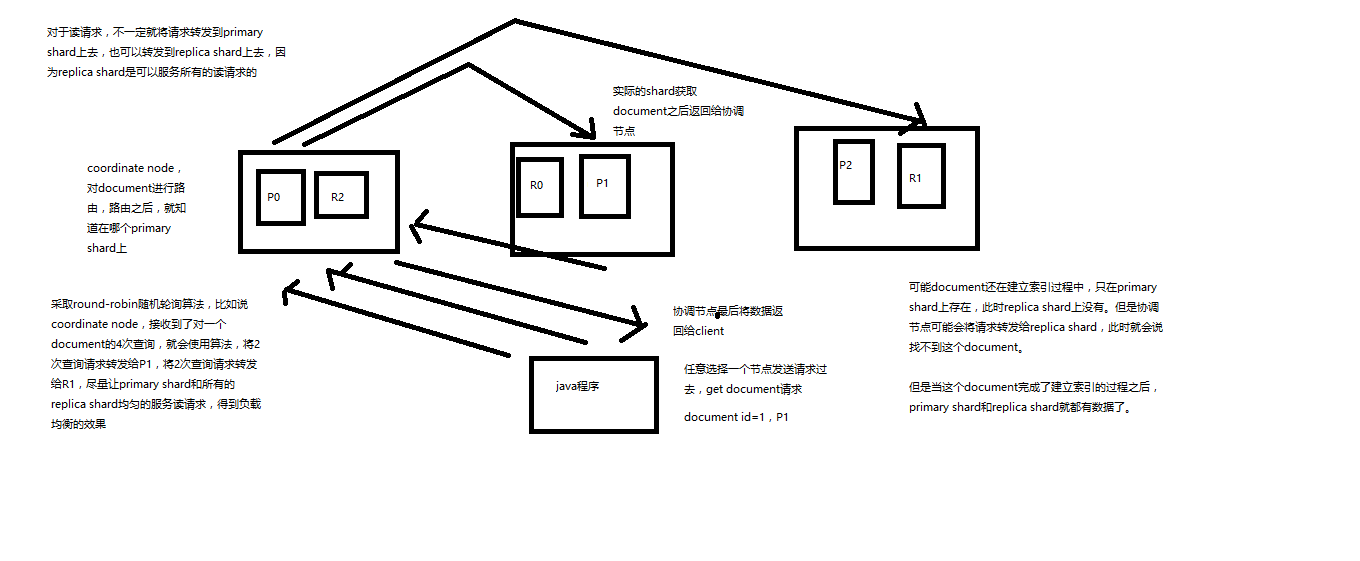
对于读请求,不一定将请求转发到primary shard上,也可以转发到replica shard上去。
具体步骤:
-
客户端发送请求到任意一个node,成为coordinate node
-
coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
-
接收请求的node返回document给coordinate node
-
coordinate node返回document给客户端
-
特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了.