

什么是持续集成
Continuous integration,简称CI持续集成
开发人员会频繁的提交代码到主干,这些代码在提交到主线之前都要经过编译和自动化测试流进行验证。保障代码在合并主干之后的质量问题,对可能出现的一些问题进行预警。 和运维的同学一起部署。 CI通过——QA测试
Continuous Delivery,简称CD持续交付 意味着除了自动化测试,我们还需要有自动化的发布流,以及通过一 个按键就可以随时随地实现应用的部署上线。 只要CI,QA一过,就可以通过一个按键实现应用随时随地的部署上线。
Continuous deployment持续部署 没有人为干预(没有一键部署按钮),只有当一个修改在工作流中构建失败才能阻止它部署到产品线。
为什么需要持续集成
- 持续集成是通过平台串联各个开发环节,实现和沉 淀工作自动化的方法。
- 线上代码和代码仓库不同步,影响迭代和团队协 作。
- 静态资源发布依赖人工,浪费开发人力。
- 缺少自动化测试,产品质量得不到保障。
- 文案简单修改上线,需要技术介入。
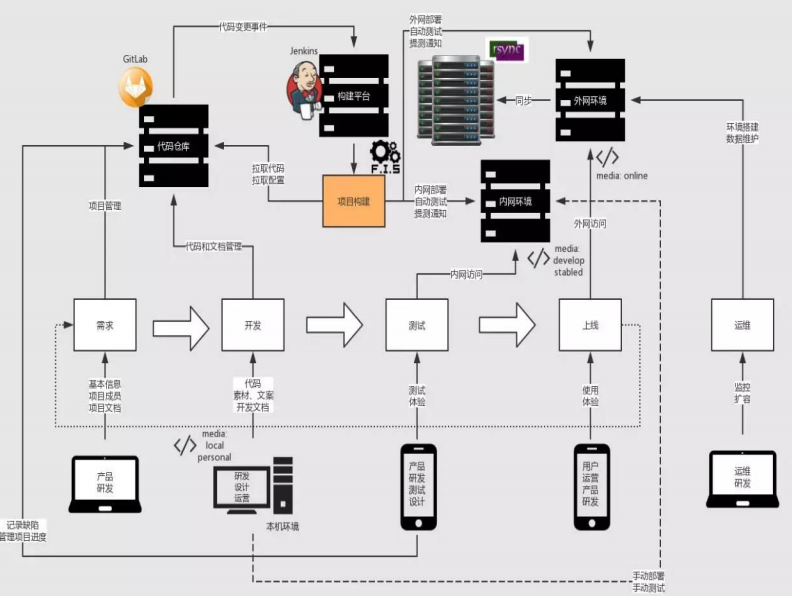
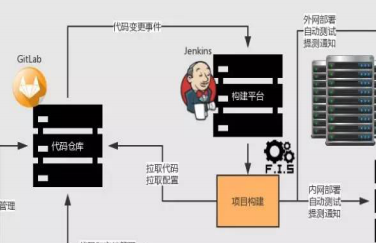
什么是统一代码仓库
svn merge的重要性 www.cnblogs.com/firstdream/…
大多数产品开发存在这样一个生命周期:编码、测试、发布,然后不断重复。通常是这样的开发步骤:
- 开发人员开发完毕某一版本(如版本A)功能后,提交测试;
- 测试人员对待发布版本A进行测试,同时开发人员继续开发新功能(如版本B);
- 测试人员提交bug,研发人员修复bug,同时继续开发新功能
- 重复第3步骤,直到待发布版本A测试通过测试后,发布第一版本
这样就会存在以下问题:
-
如何从代码库中(A+B)分离出待发布版本A,进行测试和发布;
-
若单独存放待发布版本A,那么开发组必须同时维护此版本库A以及当前最新代码库(A+B),操作冗余且容易出错。
那么有什么方法来解决这个问题呢?
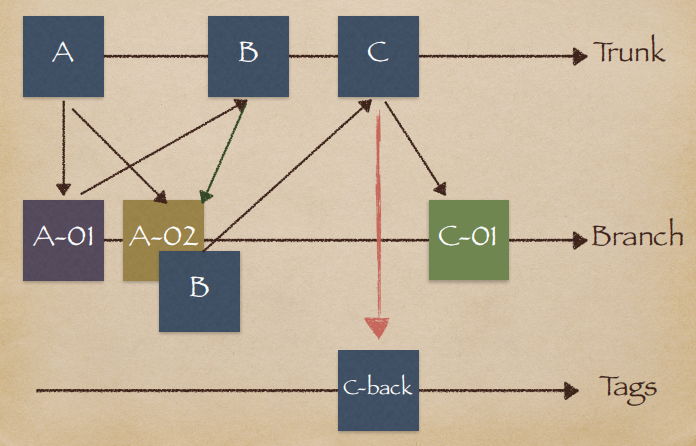
采用主干(trunk)与分支(branches)的方法。
-
具体是这样操作的:
-
在SVN中创建代码库时,通常会创建trunk、branches、tags三个子目录
-
trunk-主干,或称主线,顾名思义,是开发的主线
-
branches-分支,是从主线上分出来,独立于主线的另一条线。可以创建多个分支。一个分支总是从主干一个备份开始的,从那里开始,发展自己独有的历史(如下图所示)。在版本控制的系统中,我们经常需要对开发周期中的单独生命线作单独的修改,这条单独的开发生命线就可以称为Branches,即分支。分支经常用于添加新的功能以及产品发布后的bug修复等,这样可以不影响主要的产品开发线以及避免编译错误等。当我们添加的新功能完成后可以将其合并到主干中。
-
tags-标记,主要用于项目开发中的里程碑,比如开发到一定阶段可以单独一个版本作为发布等,它往往代表一个可以固定的完整的版本。即主干和分支都是用来进行开发,而标记是用来进行阶段发布的。(备份)
-
-
合成步骤
1.svn checkout svn地址 --username 用户名
2.svn branch 分支名(add/commit)。
3.svn merge 主干svn地址 分支svn地址。
4.Beyond Compare -> svn resolved。
5.svn copy 主干SVN地址 /tags/2017
什么是前端工程化
-
自动化编译。
-
-> 读入foo.es的文件内容,编译成js内容
-
-> 分析js内容,找到资源定位标记 'foo.scss'
-
-> 对foo.scss进行编译:
-
-> 读入foo.scss的文件内容,编译成css内容
-
-> 分析css内容,找到资源定位标记
url(foo.png) -
-> 对 foo.png 进行编译:
-
-> 读入foo.png的内容
-
-> 图片压缩
-
-> 返回图片内容
-
-
-> 根据foo.png的最终内容计算md5戳,替换url(foo.png)为url(/static/img/foo_2af0b.png)
-
-> 替换完毕所有资源定位标记,对css内容进行压缩
-
-> 返回css内容
-
-
-> 根据foo.css的最终内容计算md5戳,替换'foo.scss'为 '/static/scss/foo_bae39.css'
-
-> 替换完毕所有资源定位标记,对js内容进行压缩
-
-> 返回js内容
-
-> 根据最终的js内容计算md5戳,得到foo.coffee的资源url为 '/static/scripts/foo_3fc20.js
-
-
前端模块化。
每个文件就是一个模块,有自己的作用域。在一个文件里面定义的变量、函数、类,都是私有的,CMD和AMD都是CommonJS的一种规范的实现定义,RequireJS和SeaJS是对应的实践。
-
AMD=>requirejs(预加载) 提前读取并加载。
-
Amd推崇的是依赖前置。
define(['dep1','dep2'],function(dep1,dep2){ //内部只能使⽤指定的模块 return function(){}; });
-
Amd对加载的模块是提前读取并加载。
例如上面的代码就是将指定的依赖dep1,dep2在前面加载。
-
模块化原理
// 文件加载/文件运行 顺序: 1.js , 2.js , 3.js // 模块运行 顺序:3.js , 2.js , 1.js // 1.js 中(入口用require,其他用define) require(['2.js'], function(A) { // A得到的就是2.js模块的返回值 // 主要的执行代码 // 2.js,3.js都加载完,才执行1.js的这回调函数!!!!!!!!!!!!!!! }) // 2.js 中 define(['3.js', 'xxxx.js'], functionA(B, C) { // B得到的就是3.js模块的返回值,C是xxxx.js的 return 2; // 2.js 模块的返回值 }); // 3.js 中 define([], functionA() { retrun {} // 3.js 模块的返回值 })
执行顺序应该是3.js,2.js,1.js,即如果模块以及该模块的依赖都加载 完了,那么就执行。 比如 3.js 加载完后,发现自己也没有需要加载的依赖, 那么直接执行3.js的回调了,2.js加载完后探查到依赖的3.js也加载 完了,那么2.js就执行自己的回调了。主模块一定在最后执行。
-
优缺点
-
AMD的依赖是提前声明。这种优势的好处就是依赖无需通过静态分析,无论是加载器还是自动化工具都可以很直接的获取到依赖。
-
AMD依赖提前声明在代码书写上不是那么友好。
-
AMD模块内部与 NodeJS 的 Modules 有一定的差异
var onload = function () { clearTimeout(tid); }; if ('onload' in script) { script.onload = onload; } else { script.onreadystatechange = function () { if (this.readyState === 'loaded' || this.readyState === 'complete') { onload(); } }; } })(script, id);
通过onload判断是否加载完成,如果没有onload属性,那么就通过onreadystatechange来判断。加载完成之后就可以执行了。
-
-
-
CMD=>SeaJs(懒加载) 提前读取文件,但在需要再加载
-
Cmd推崇的是就近依赖。
-
Cmd对加载的模块是提前读取并不加载,而是在需要时加载
对于依赖的模块CMD 是延迟执行。as lazy as possible 不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)
-
加载原理
//CMD defin(function(require,exports,module){ //此处如果需要加载某XX模块,可以引⼊,也就是在需要的时候进行加载 var xx=require(‘XX’); }); -
模块化原理
// 只有define,没有require // 和AMD那个例子一样,还是1依赖2, 2依赖3 //1.js中 define(function() { var a = require('2.js') console.log(33333) var b = require('4.js') }) //2.js 中 define(function() { var b = require('3.js') }) //3.js 中 define(function() { // xxx })先把require那一部分用正则解析出来,需要什么模块就加载什么模块(先把所有需要用到的包下载过来)。全都加载完了之后就执行。 先执行主模块1.js,碰到require('2.js')就执行2.js,2.js中碰到require('3.js')就执行3.js。
-
优缺点
-
CMD 依赖是就近声明,通过内部require方法进行声明。但是因 为是异步模块,加载器需要提前加载这些模块,所以模块真正使用 前需要提取模块里面所有的依赖。
-
不能直接压缩,require局部变量如果替换无法加载资源
-
CMD路径参数不能进行字符串运算(用正则分析)。
-
-
-
为什么要使用webpack?
- Webpack执行CommonJS标准,解决了依赖配置和请求流量。
- 对于Webpack来讲万物都可以是模块,所有文件都被合并到JS中,最终在浏览器。
- 兼容AMD与CMD。
- JS模块化不仅仅为了提高代码复用性,更是为了让资源文件更合理地进行缓
- 定位静态资源。
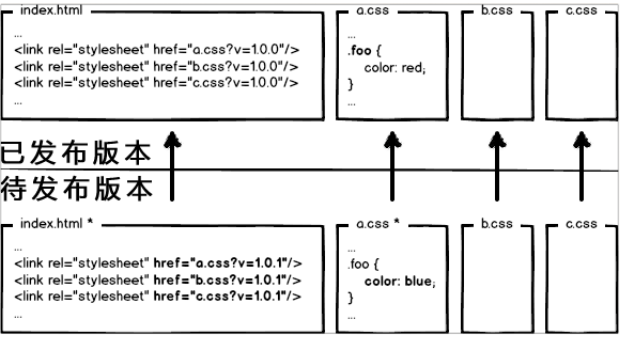
因为浏览器的缓存机制,当代码版本更新的时候用户也不会重新加载新的版本,为了解决这个问题,更新之后在请求的资源后面加上v=XX表示不同的版本,这样子用户会请求更新后的资源
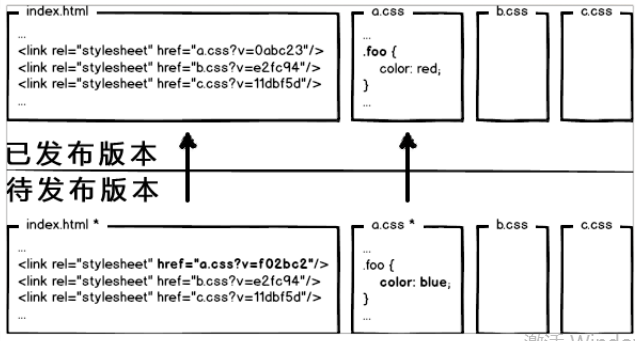
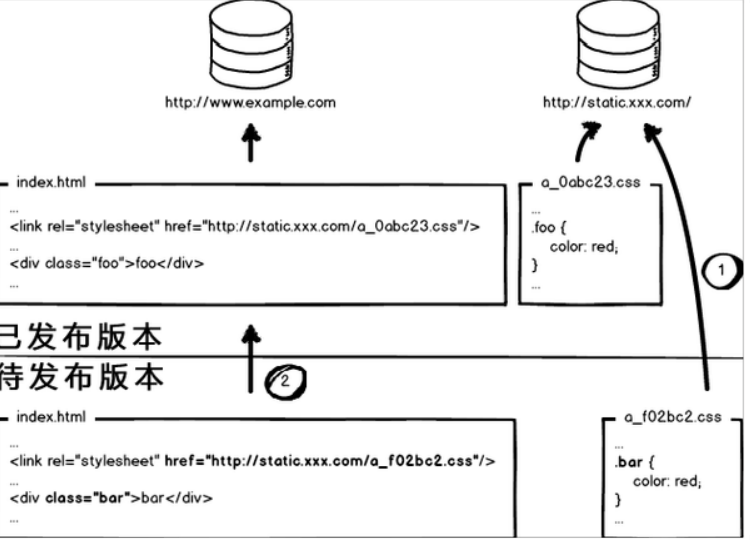
- 自动化部署测试配合版本库。
什么是自动构建
前端开发组件化
-
每一个前端模块都是一个小项目,配合mock.j可以进行本地的开发测试,package.json是标配产物。经过webpack的环境配置统一进行本 地环境、上线环境的编译过程。
-
由page组装widget,由widget组装Web Components(X-TAG)。
-
能够根据路由快速抉择配置SPA或者直出
Web Components
-
Custom Elements
提供⼀种⽅式让开发者可以⾃定义 HTML 元素,包括特定 的组成,样式和⾏为。
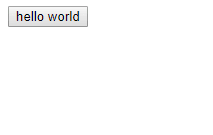
<body> <script> class ButtonHelloElement extends HTMLButtonElement { constructor() { super() this.addEventListener('click', () => { alert('hello world') }) } } customElements.define('button-hello', ButtonHelloElement, { extends: 'button' }) </script> <button is="button-hello">hello world</button> </body>
-
HTML Imports
HTML Imports 是⼀种在 HTMLs 中引⽤以及复⽤其他的 HTML ⽂档的⽅式。这个 Import 很漂亮,可以简单理解为 我们常⻅的模板中的 include 之类的作⽤。
-
HTML Templates HTML Templates提供了⼀个 template 标签来存放以后需要但是暂时不渲染的 HTML 代码。
<body> <template id="template"><p>Smile!</p></template> <script> let num = 2; const fragment = document.getElementById('template').content.cloneNode(true); while (num-- > 1) { fragment.firstChild.before(fragment.firstChild.cloneNode(true)); fragment.firstChild.textContent += fragment.lastChild.textContent; } document.body.appendChild(fragment); </script> </body> -
Shadow DOM
developer.mozilla.org/zh-CN/docs/…
Shadow DOM 最本质的需求是需要⼀个隔离组件代码作⽤域的 东⻄,例如我组件代码的 CSS 不能影响其他组件之类的,⽽ iframe ⼜太重并且可能有各种奇怪问题。旨在提供⼀种更好地 组织⻚⾯元素的⽅式,来为⽇趋复杂的⻚⾯应⽤提供强⼤⽀持, 避免代码间的相互影响。
Shadow DOM 必须附加在一个元素上,可以是HTML文件中的一个元素,也可以是脚本中创建的元素;可以是原生的元素,如
、;也可以是自定义元素如
<my-element>。如下例所示,使用Element.attachShadow()来附加影子DOM:影子DOM由下列部分组成:
Element.attachShadow()Element.getDestinationInsertionPoints()Element.shadowRoot- 元素
- 元素
- 这些元素已从规范中移除: , 和
- 相关API接口:
ShadowRoot,HTMLTemplateElementandHTMLSlotElement - CSS 选择器:
- 伪类:
:host,:host(),:host-context() - 伪元素:
::shadowand::content - 组合器:
>>>(formerly/deep/)*
- 伪类:
shadow dom不受外界的干扰。
<div id="test">你好</div>
<script>
const div = document.getElementById('test')
const shadowRoot = div.createShadowRoot()
const span = document.createElement('span')
span.textContent = 'hello world'
shadowRoot.appendChild(span)
</script>
以上代码我们可以看到这样的页面结构

