

我们把爬虫已经写好了,而且在本地可以运行了。
这个不是最终的目的啊。
我们是要在服务器上运行爬虫。
真正的:云爬虫!云爬虫!云爬虫!
腾讯服务器,阿里云服务器都可以
就在这里再来一篇手把手的将爬虫部署到服务器上吧。
绝对从0教学。
一步一步的来,还有截图
让你从『倔强青铜』杀到『最强王者』
福利就要写在最前面:
过大年了,大家是不是又有了压岁钱了啊??啊哈哈哈哈,压岁钱买糖吃还不如投资到自己身上。比如用来买课程,或者用来买服务器,来学习编程,写爬虫。来买服务器啊买服务器啊!只在本地跑,根本没用的!恰巧,铲屎官这里就有上千元的阿里云和腾讯云的优惠券给你使用(每一款优惠只要点击优惠链接,进入即可领取):
阿里云部分:
【阿里云新人1888元云产品通用代金券】:
promotion.aliyun.com/ntms/yunpar…
【阿里云爆款云主机,2折优惠券】:
promotion.aliyun.com/ntms/act/qw…
【阿里云企业级服务器2折优惠券】:
promotion.aliyun.com/ntms/act/en…
腾讯云:
【新客户无门槛领取总价值高达2775元代金券,每种代金券限量500张,先到先得】:
cloud.tencent.com/redirect.ph…
【腾讯云服务器、云数据库特惠,3折优惠券】:
cloud.tencent.com/redirect.ph…
--接下来是正文--
大家好,我是铲屎官,为啥要写这篇文章,就是为了让你上『最强王者』! Scrapy的文章,好多好多,但是99%的文章都是,写完爬虫就完事儿了,至于后来怎么用?去哪里用?都没有交带。我这里就交代一种,可以把你的小虫子部署到服务器上!但是怎么部署,
貌似大家对爬虫还是很跟兴趣的。之前铲屎官写的几篇爬虫文章,大家可以自行在网上搜索。都反响不错,充分的激起了大家学习Python,运用Python的热情。感觉Python不在是那么的死板,不再是像教科书上的说明,是实实在在的可以在平时运用,编写的程序语言。所以,这篇我们就稍微进阶一下:
将我们的爬虫部署到腾讯云服务器上面(阿里云服务器同理)。废话不多说,我们就来实战操作吧。
这里选择什么云服务都是可以的,阿里云,AWS,腾讯云,其他云都是没有问题的。部署方法基本一样,这里为了方便,所以笔者选择了腾讯云来做讲解。
既然我们选择了腾讯云,首先去腾讯云的官网,注册登录一下。
https://cloud.tencent.com/
当你看到这篇文章的时候,我不知道腾讯云的优惠是怎样的,反正我当时,给我了7天的云服务器体验。我就准备拿这个试试手。腾讯云界面长这个样子:
登录之后,买完服务器之后,在云服务器界面,就会看到你的服务器实例了:
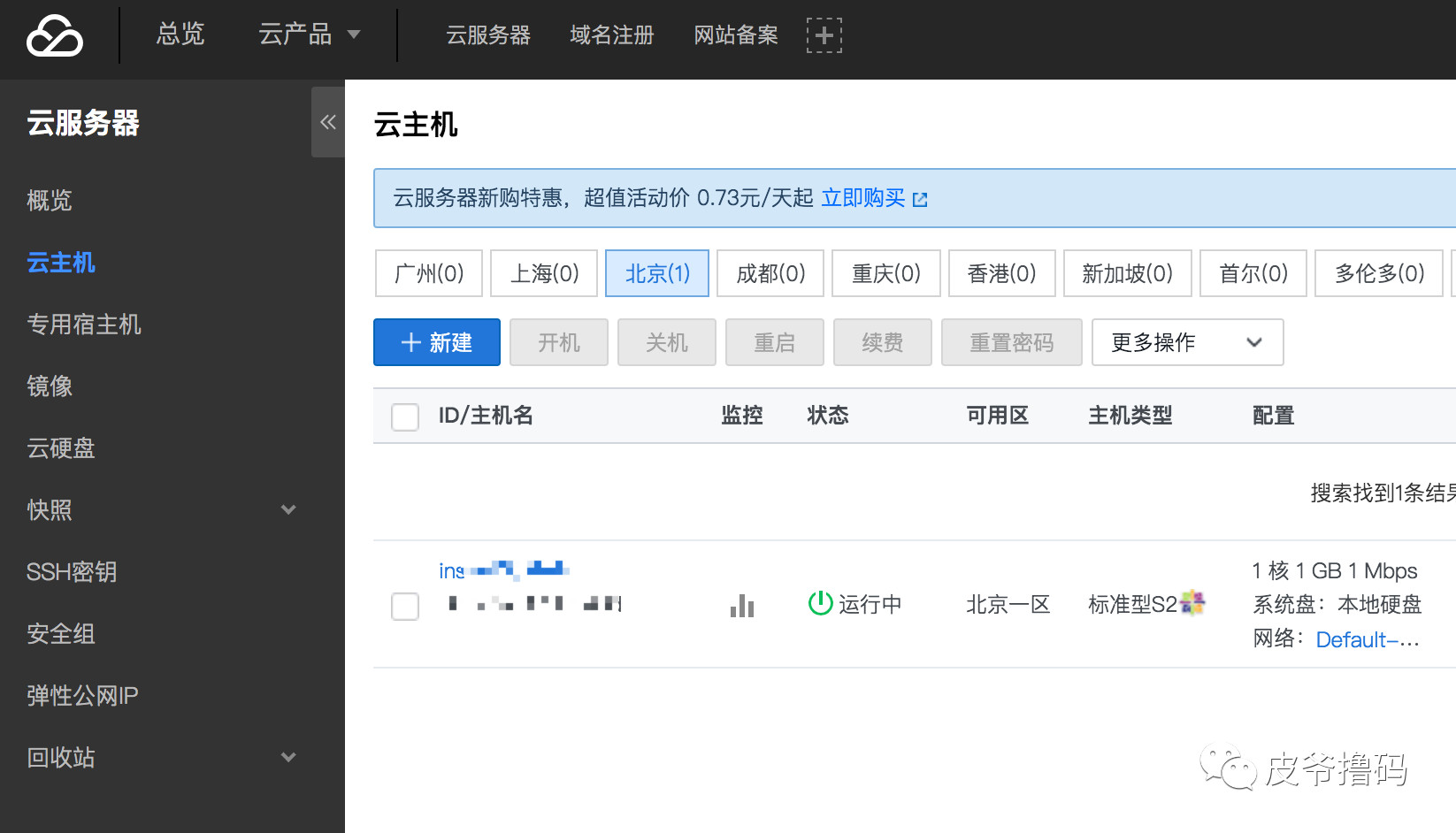
界面上面有你服务器的ip地址,我们远程登录,就需要知道服务器的公网ip地址:

本地我用Mac的terminal的ssh登录,输入指令就是:
$ ssh root@1XX.XXX.XXX.XXX
然后输入密码,登录成功,就会显示如下界面:
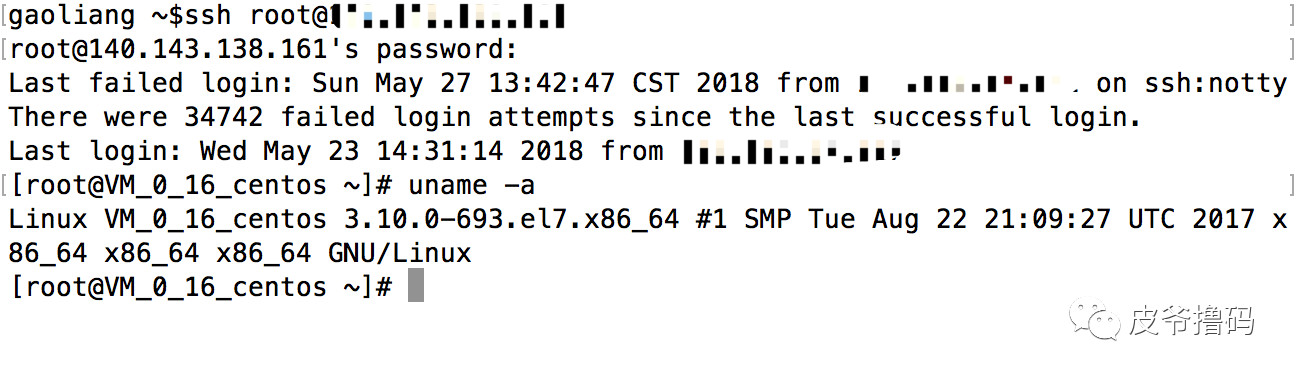
卧槽,可以看到,有3万多次的尝试登录,看来服务器的权限如果设置的不够安全的话,是很容易被别人攻破的。
OK,服务器的东西我们就先暂时放到一边。输入
$ exit
退出登录。我们先来说说爬虫的事儿。
这里,我们待部署的爬虫,是用
这里我们部署的爬虫只是我日后项目的一个简单的版本,你可以看『1024种子吞噬』。。。的Scrapy版本。
工程目录还是很简单的,和标准的Scrapy创建目录一样:
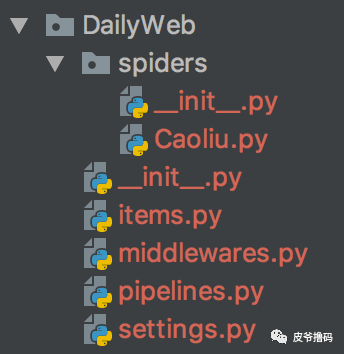
至于工程怎么写,请参考[『“手把手”教你用爬虫爬达盖尔。。。。』]()文章。
我们这期的爬虫项目叫DailyWeb,里面的虫子叫Caolu。爬虫『Caolu』的主要功能,就是从不同的主题区里面,读取当天发布的帖子,然后将这些帖子的url,title,发布时间和id都保存下来,存入数据库中。
想要爬虫源码的同学,请关注『皮爷撸码』,里面有很多爬虫的文章哦。如果有什么疑问,也可以在公众号里面留言,我会一一查看的。
爬虫就是这样,我们部署的任务,目前有两个部分,远端的服务器和我们本地的电脑。我们要把本地电脑的爬虫部署到远端的服务器上,上文中我们提到了两个东西Scrayd和Scrapyd-client这两个东西,分别安装的位置就是远端服务器安Scrapyd,本地需要上传的机器安装Scrapy-client。那么,我们本地机器安装scrapy-client。
$ pip isntall scrapy-client
安装完成之后,我们需要进入到你Scrapy工程目录下,执行
$ scrapyd-deploy -l
就会生成一个scrapy.cfg文件。这个文件就是项目的配置文件,里面大概长这个样子:
[settings]
default = DailyWeb.settings
[deploy]
#url = http://localhost:6800/
project = DailyWeb
这里,我们需要改一些东西,将url的注释取消掉,同时,改成你服务器的地址,再在deploy后面加上一个远端地址的名字。
[settings]
default = DailyWeb.settings
[deploy:TencentCloud]
url = http://119.75.216.20:6800/
project = DailyWeb
OK,本地的配置到这里就结束了。我们接着之前的教程来登录你远端的服务器,登录成功之后,我们需要安装Python3.6,以及Scrapyd等东西。
// 安装依赖包
# yum -y groupinstall "Development tools"
# yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
// 下载 Python 3.6.2
# wget https://www.python.org/ftp/python/3.6.2/Python-3.6.2.tar.xz
// 创建安装目录
# mkdir /usr/local/python3
// 安装 gcc
# yum -y install gcc
// 安装 Python 3.6.2
# tar -xvJf Python-3.6.2.tar.xz
# cd Python-3.6.2
# ./configure --prefix=/usr/local/python3
# make && make install
// 安装scrapyd
# pip3 install scrapyd
// 安装scrapy
# pip3 install scrapy
// 安装scrapyd-client
# pip3 install scrapyd-client
// 安装BeautifulSoup4,因为爬虫中用到了,所以这里得安装一下
# pip3 install bs4
安装好之后,运行命令
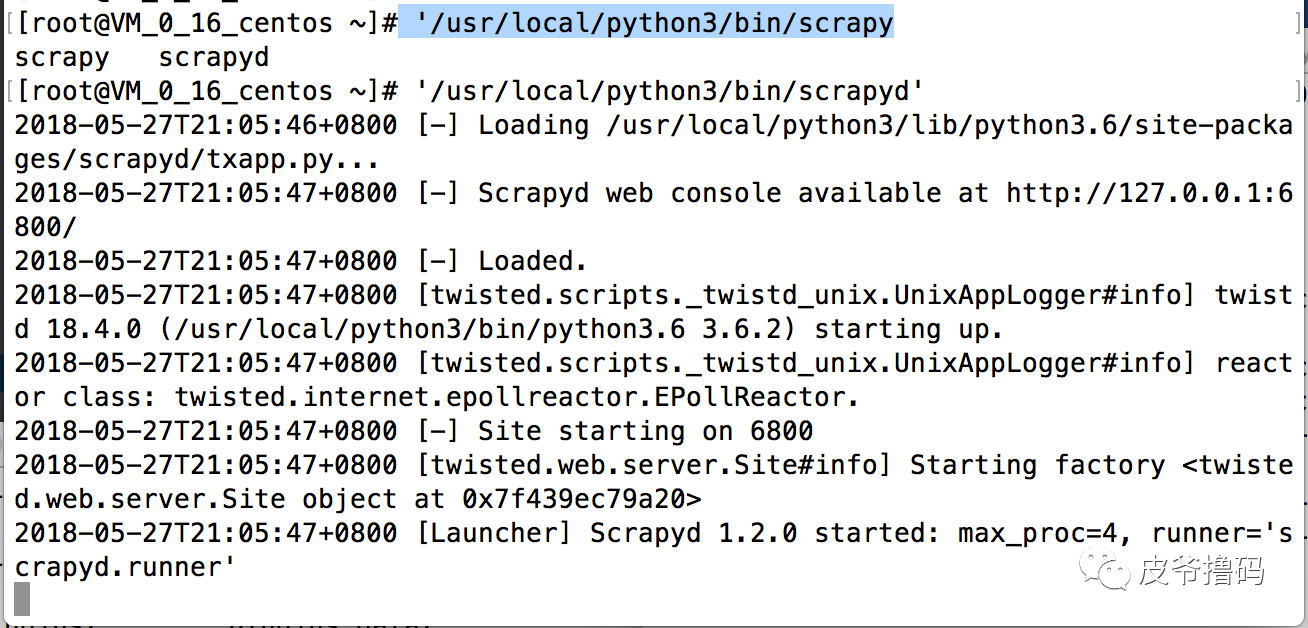
# '/usr/local/python3/bin/scrapyd' &
会启动scrapyd,如下图:
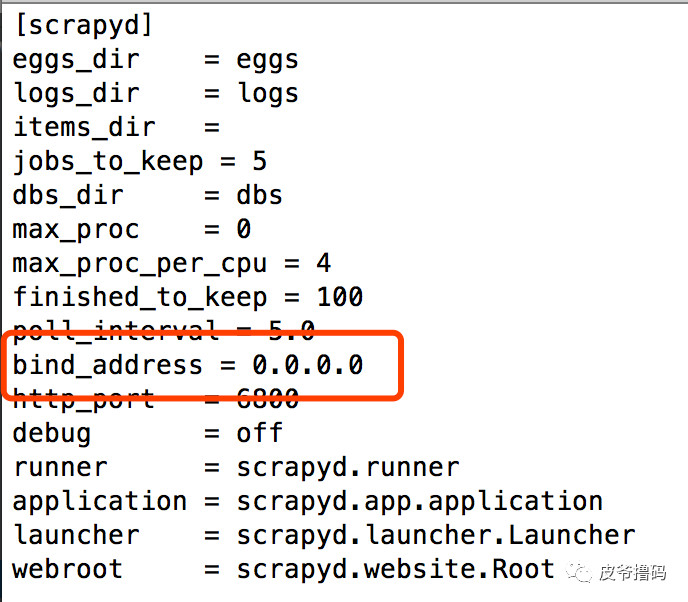
首先,我们得修改default_scrapyd.conf文件。这个问题件的路径在下面:

我们需要将 bind_address = 127.0.0.1 改为 bind_address = 0.0.0.0,这样,就可以通过外部访问本地的ip了:
接着,我们还需要给我们的云服务器配置一下安全组,要把6800的接口权限开通,这样才能够通过外网访问到服务器的网页。
腾讯云的控制台页面,左侧选择安全组,
选择新建按钮,我们这里选择常用的端口暴露,即第二个。
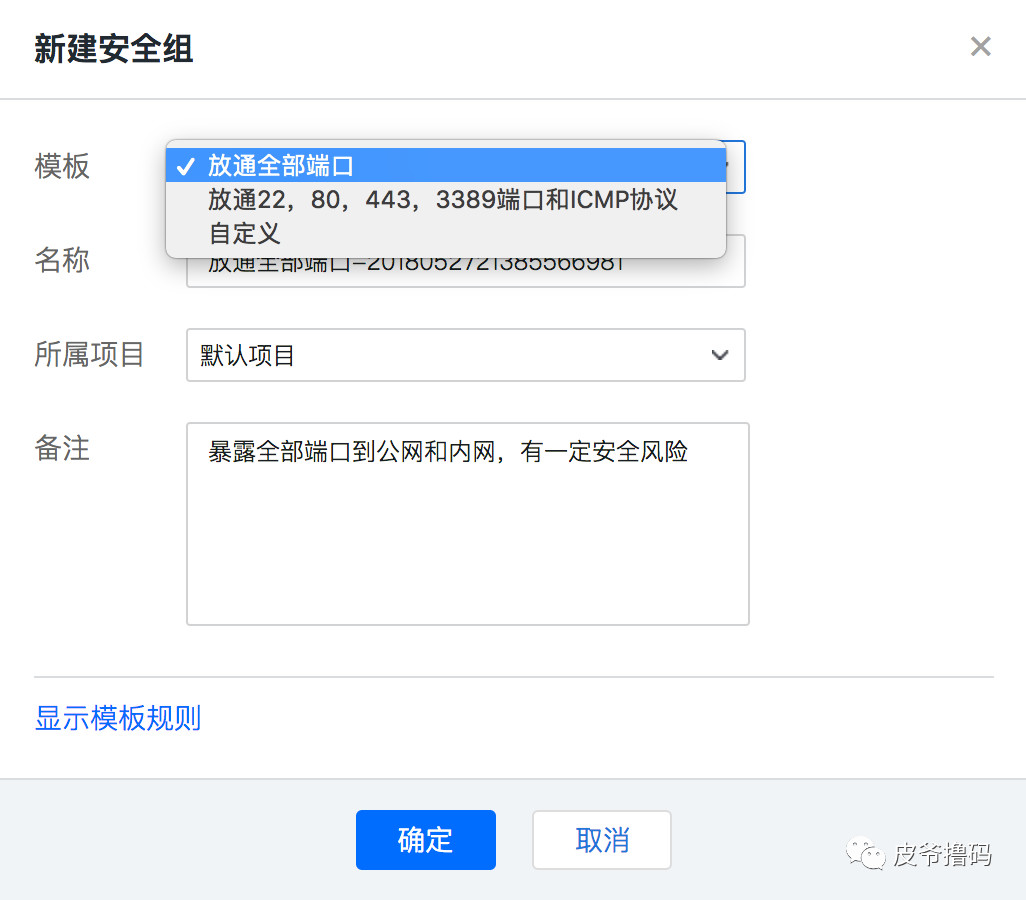
然后选择修改规则,因为我们要把6800加进去。

选择添加规则,将ip设置成 0.0.0.0/0 即全网ip,端口写 tcp:6800,选择允许,然后点击确定。
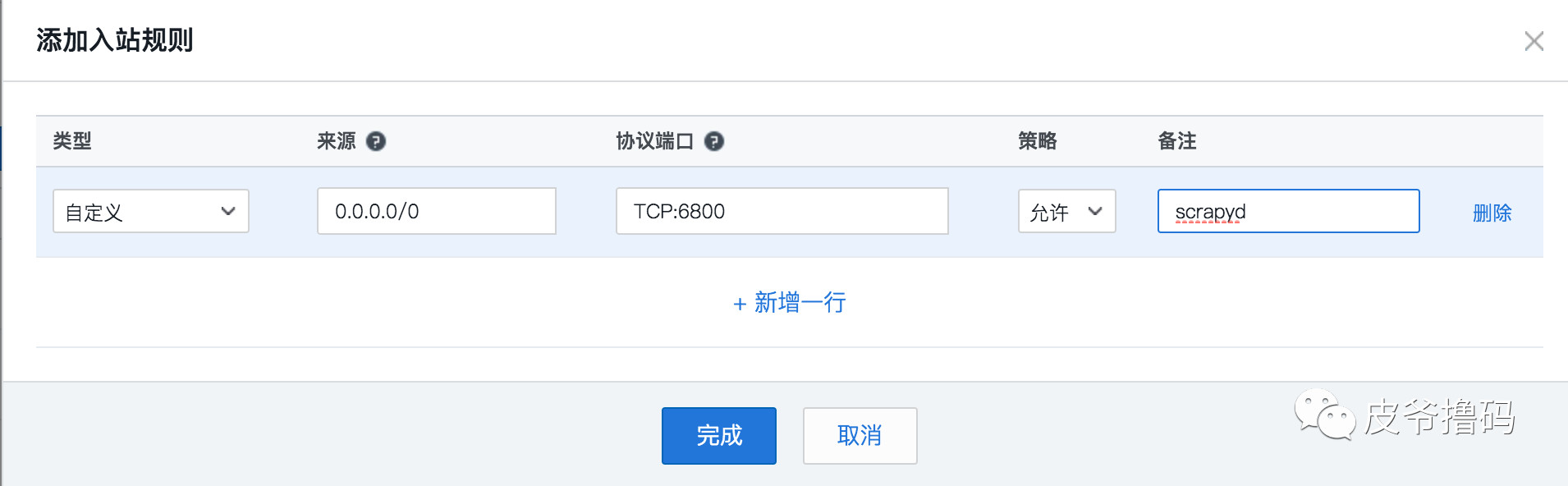
安全组添加好了,那么我们回到服务器实例页面,在更多里面选择配置安全组:
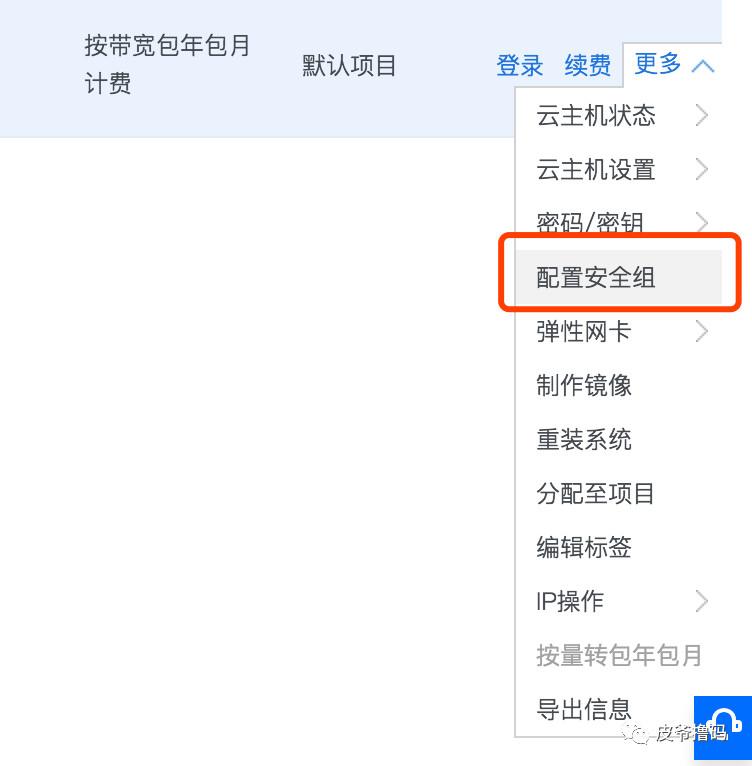
选择我们刚才添加的那个安全组,点击确定。
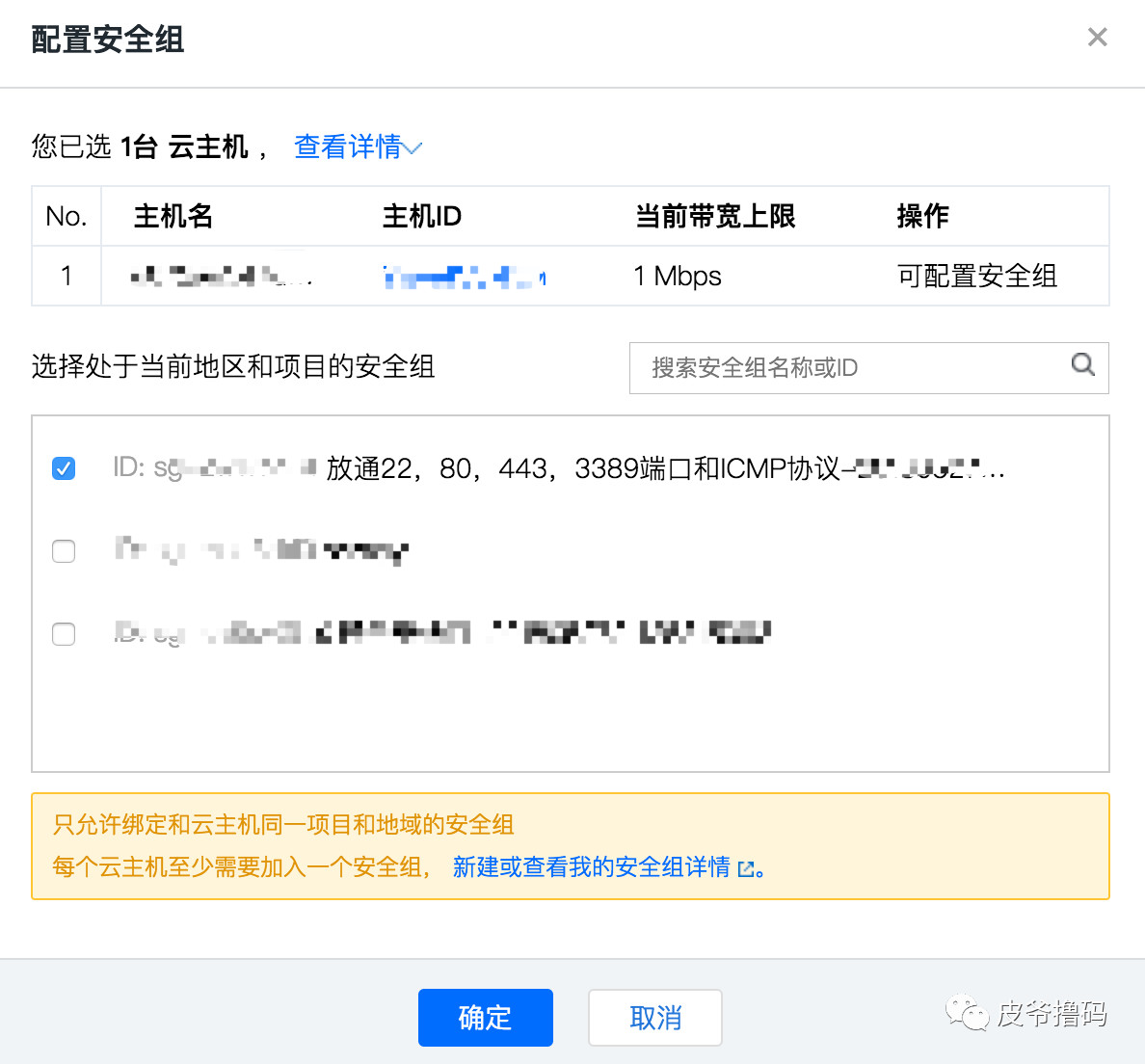
OK,
119.75.216.20:6800。这样,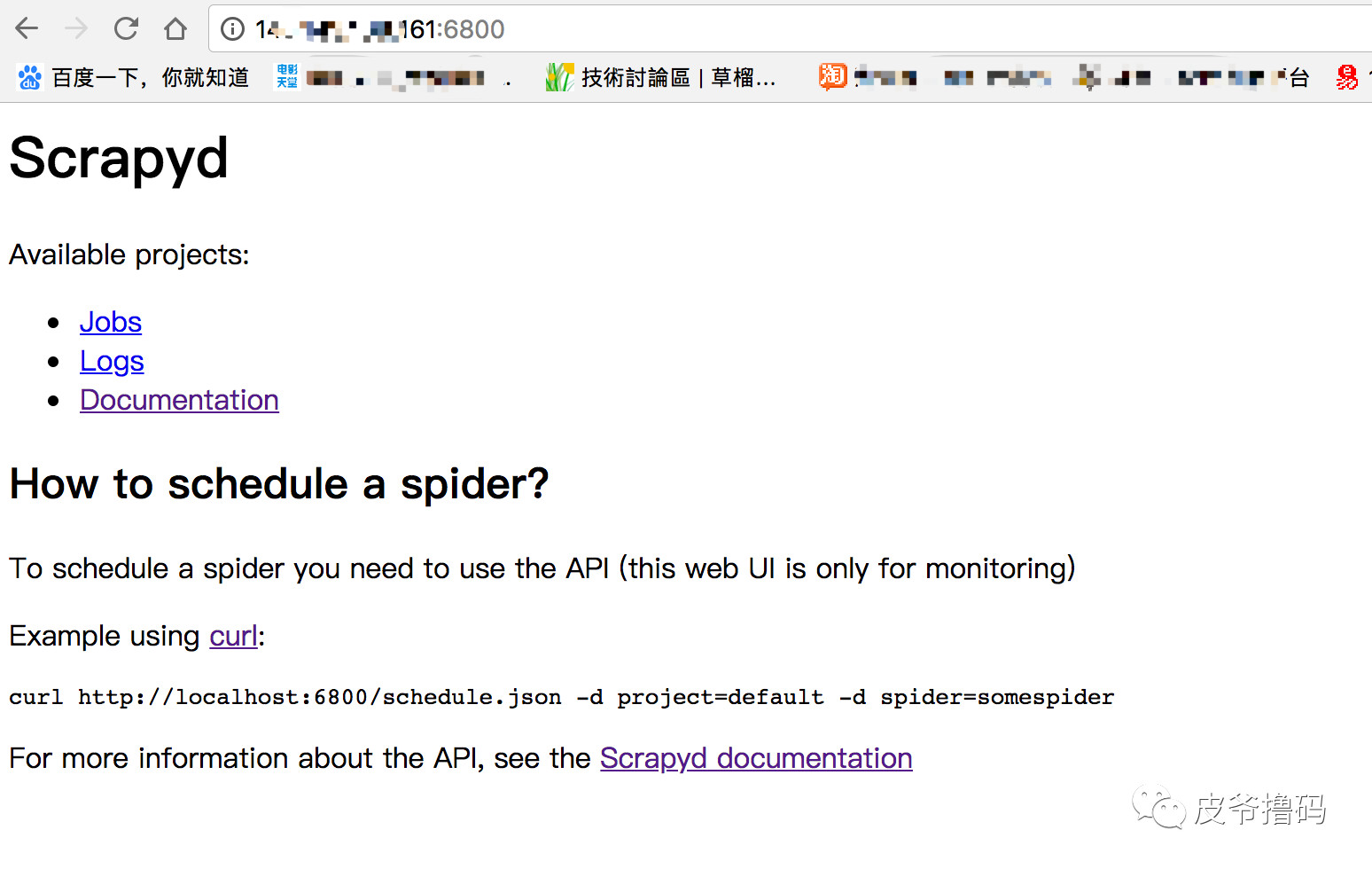
由于我们还没有部署爬虫,所以,点击Jobs和Logs链接进去之后,都是空页面。
啊,我的快捷标签大家就别关注了。看到这个页面就说明你的Scrapyd在远端的服务器上面已经跑成功了。
当然,这些端口6800什么的,都是可以配置的,配置文件就是在上面所说的那个default_scrapyd.conf文件。最关键的就是要给服务器配置安全组,将对应的端口开放,否则访问不成功。
好了,接下来,我们就该关注本地了,将我们的爬虫部署到服务器上。
本地进入到爬虫工程的目录。因为刚才输入了$ scrapyd-deploy -l生成了一个scrapy.cfg文件,我们需要对这个文件修改一些东西。将文件修改成一下样式:
[settings]
default = DailyWeb.settings
[deploy:TencentCloud]
url = http://119.75.216.20:6800/
project = DailyWeb
然后本地按照scrapyd-deploy <host> -p <project>输入指令:
$ scrapyd-deploy TencentCloud -p DailyWeb
若是在这期间有错误,根据错误提示来自行安装Python库就好。等到部署成功,会出现如下画面:
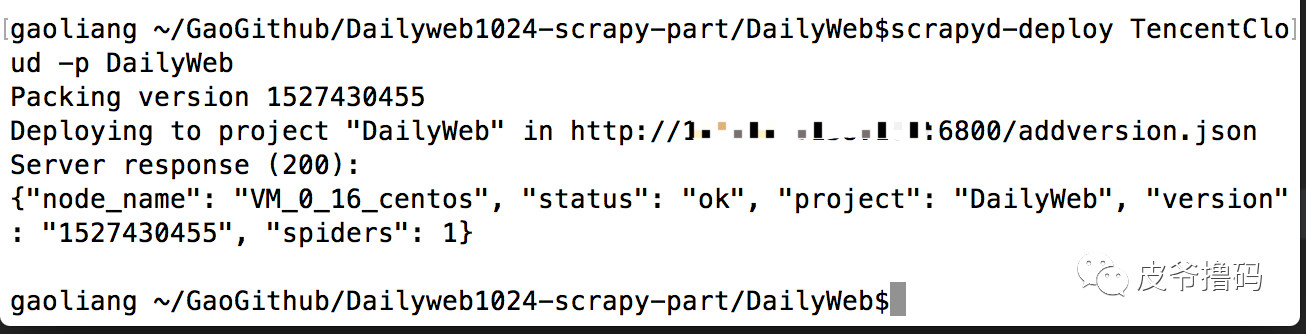
看到,服务器给我们返回了一个json格式的结果。这个就是Scrapyd的最大特点,通过json来控制操作。上面显示的是部署成功。
我们如果想检查部署的工程,按照scrapyd-deploy -L <host>,在本地输入命令:
$ scrapyd-deploy -L TencentCloud
结果如下:

看到我们的DailyWeb爬虫已经成功部署到了腾讯云服务器上了。
我们可以通命令:
curl http://119.75.216.20:6800/listprojects.json
可以看到远端服务器上的爬虫:

OK,我们现在如果想要爬虫启动,那么只需要输入命令:
$ curl http://119.75.216.20:6800/schedule.json -d project=<project name> -d spider=<spider name>
我们这里输入的命令则是:
$ curl http://119.75.216.20:6800/schedule.json -d project=DailyWeb -d spider=Caoliu
输入完,本地的terminal会呈现:
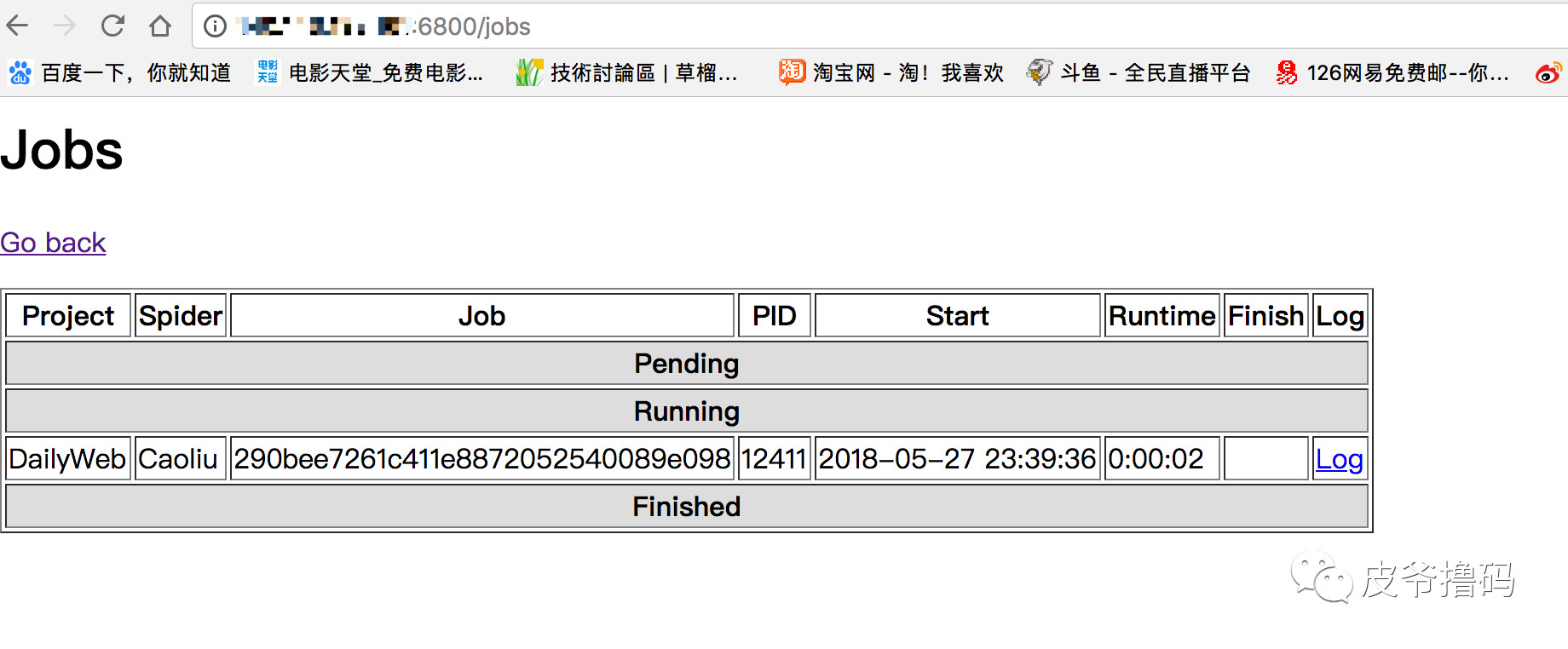
我们在浏览器里,访问服务器的6800端口,就能够在网页的Jobs里面看到爬虫工作状态了:
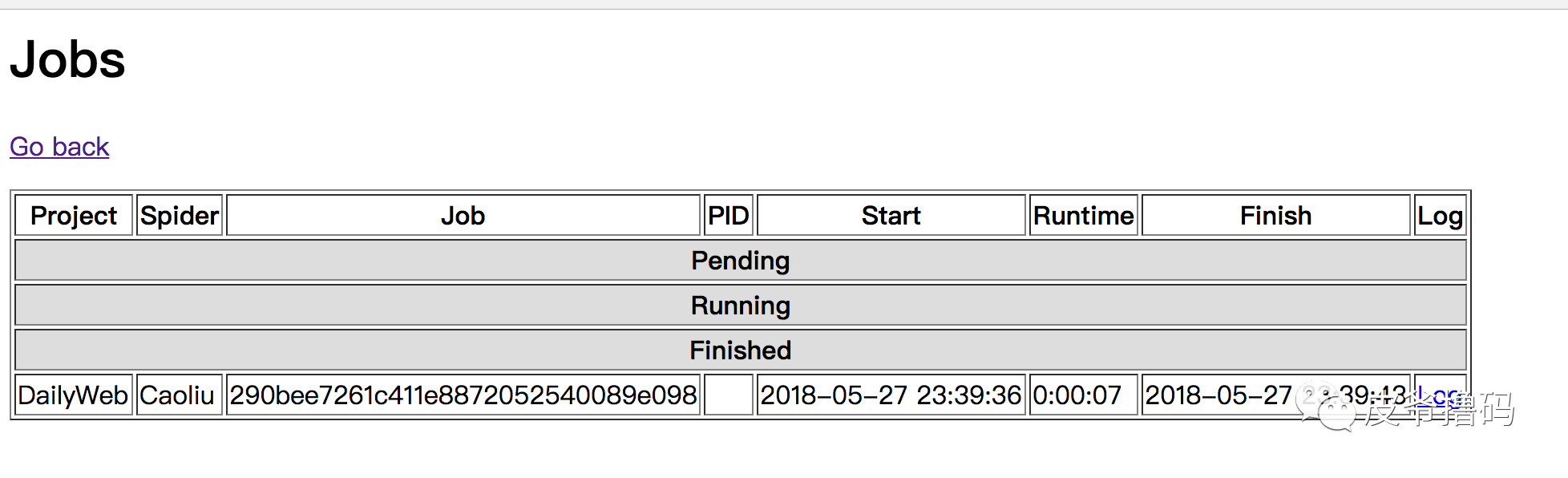
可以看到,爬虫的进度在Running里面,当爬虫爬完了,会在这个里面:
我们退到上级页面,从Log里面看,就发现有一条log文件。
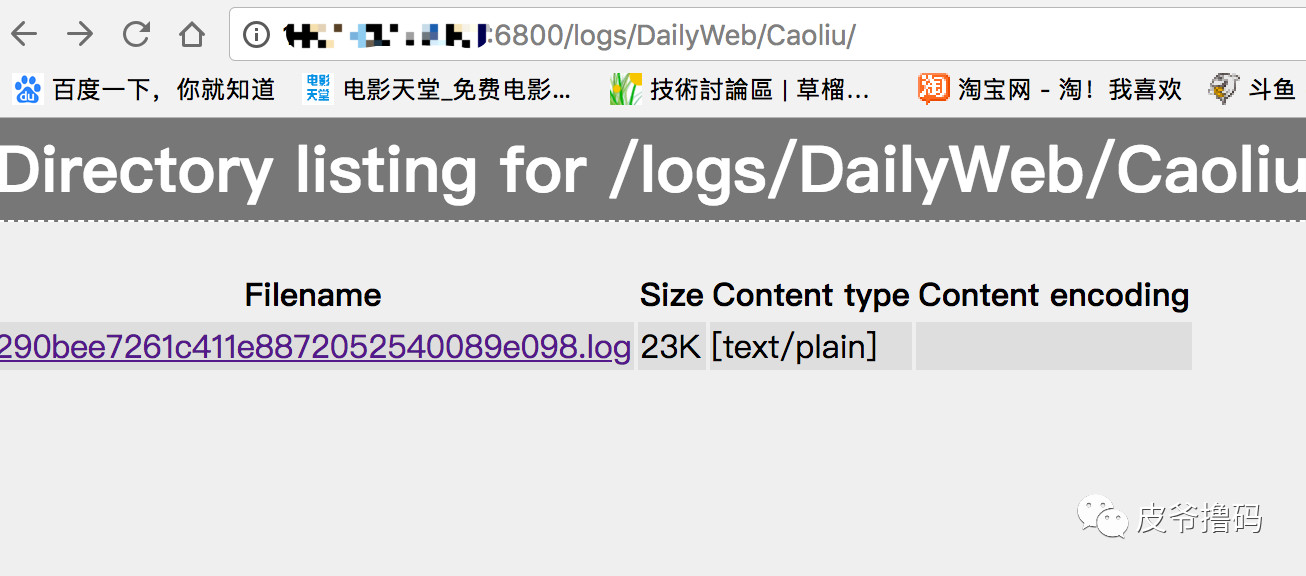
23K的log文件,

文件的目录在:
./logs/DailyWeb/Caoliu/290bee7261c411e8872052540089e098.log
打开之后,就能看到刚才爬虫运行时候留下来的Log了。关于Log怎么打或者打什么,这个是Scrapy框架里自己写好的,非常方便,直接导入python的logging库,按照标准方法打印就可以。
那么,我们应该如何取消一个Job呢?输入命令:
curl http://119.75.216.20:6800/cancel.json -d project=<project name> -d job=<job id>
上面的job id,就是在Jobs页面里面看到的。
如果要移除一个工程,命令则是:
curl http://119.75.216.20:6800/delproject.json -d project=<project>
这里说一个奇淫巧技,由于服务器的scrapyd需要后台运行,这里我采用了# setsid scrapyd命令来后台开启服务,这样关闭窗口后仍能进行连接。需要结束scrapyd进程时,利用# ps -ef | grep -i scrapyd 查看PID号,再# kill -9 PID结束进程。
若是想要固定的去执行爬虫,这里可以使用Linux自带的crontab。这个我还没研究,应该不难,等下一步了可以放出来给大家。
OK,到此为止,如果你能跟着我的步骤一步一步做到这里,首先恭喜你,说明你很优秀,很有毅力,绝对是个编程的料,而且还有可能成为
最后感言一下,为什么要写这种手把手,一步一步来操作的文章,是因为,好多同学都听说过Python,而且对Pyton抱有期待,想去学。但是,好多同学非科班出身,或者之前就从来没学习过编程,哪像我们这种编程的老油条,拿到一门语言都有自己独特的学习方法能够快速掌握。这些同学就很困惑,因为大家都说Python好,Python好学,Python容易,Python简单,Python能干很多事情事情。。。但是当自己面对Python的时候,Python确是一座大山。没有人给他指引道路,没有人告诉他,那片丛林第几棵树和第几棵树之间有通往下一关的道路,导致他们很苦恼,很困惑,从而就会打击学习编程的积极性,就会产生“Python这么简单我都不会,看来我不是学习编程的料”这种负能量的想法。同学!这样想是不对的!学习编程,你要坚持啊!罗马并非一日建成的,任何看似熟练的技能,都是背后日日夜夜反复打磨出来的结果。你如果对Python感兴趣,喜欢学Python,我可以给你带路,我写这种手把手的文章,就是为了给你们引路,让更多的同学来投入到他们热爱的编程学习中,体验编程的快乐。若是你想学习,想改变自己,或者周围有同学想学习编程,请你手动把这篇文章分享出去,我希望,通过有趣的实战Python项目,能够让Python编程不再那么空洞,而且,新手来了可以根据我的步骤一步一步来,感受程序运行起来的快乐。您的分享,就是对我最大的支持。
OK,以上就是这期手把手一步一步将Scrapy爬虫部署到服务器上的教程。
关注这个神奇的公众号,里面会有神奇代码哦

