

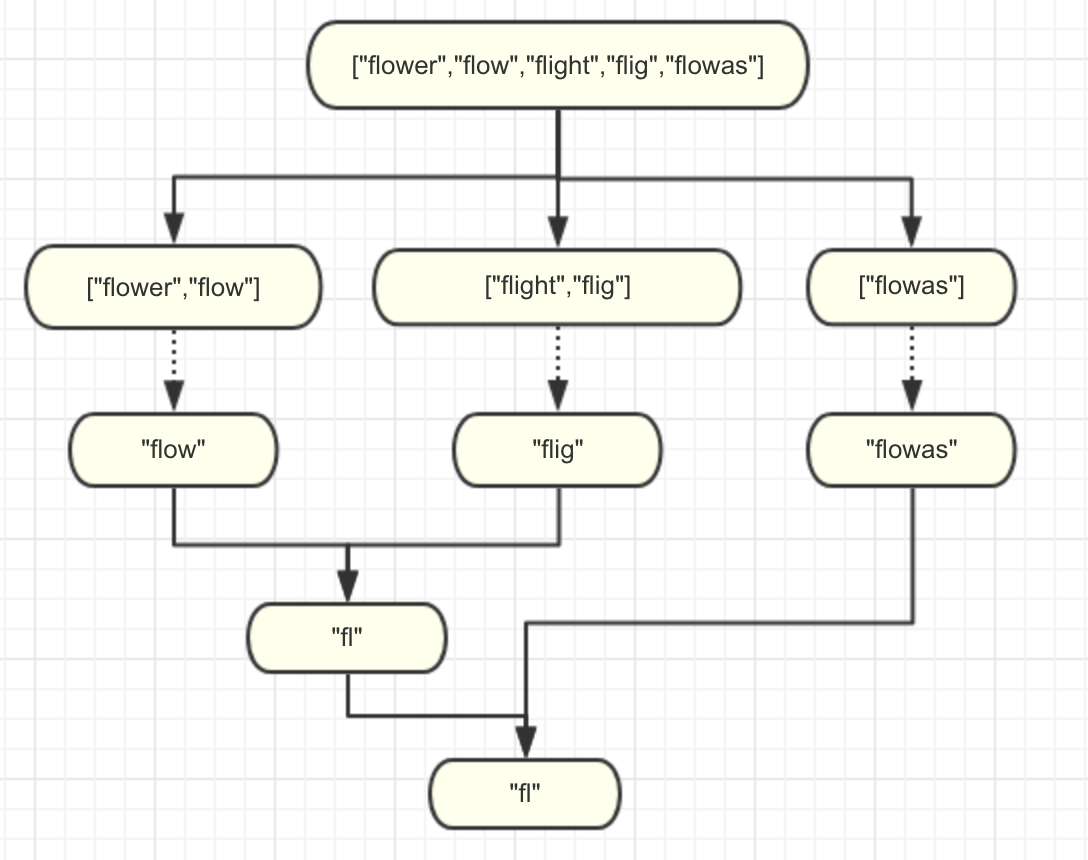
分治法图示
class Solution:
# 水平扫描法
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
if len(strs) == 1:
return strs.first
reult = ""
minLength = 10000
charIndex = 0
tempChar = ""
while True:
flag = False
for index in range(len(strs)):
tempStr = strs[index]
if charIndex == 0:
minLength = min(len(tempStr), minLength)
if index == 0:
tempChar = tempStr[charIndex:charIndex+1]
else:
if tempStr[charIndex:charIndex+1] == tempChar:
if index+1 == len(strs):
reult += tempChar
else:
flag = True
break
charIndex += 1
if flag or charIndex > minLength:
break
return reult
# 分治法,空间开销变大了
# def longestCommonPrefix(self, strs):
# l = len(strs)
# # print(strs, str(l))
# if l > 2:
# return self.getCommonPrefix(self.getCommonPrefix(strs[0], strs[1]),self.longestCommonPrefix(strs[2:]))
# else:
# if l == 1:
# return strs[0]
# elif l == 2:
# return self.getCommonPrefix(strs[0], strs[1])
# else:
# return ""
# def getCommonPrefix(self, strs0, strs1):
# ret = ""
# charIndex = 0
# minLen = min(len(strs0), len(strs1))
# while charIndex < minLen:
# if strs0[charIndex] == strs1[charIndex]:
# ret += strs0[charIndex]
# charIndex += 1
# else:
# break
# # print(strs0, strs1, ret)
# return ret
test = Solution()
# print([0,1,2,3,4,5,6][:3])
# print([0,1,2,3,4,5,6][3:])
# print("123"[2:3])
print(test.longestCommonPrefix(
["flower0", "flow1", "flower2", "flow3", "flower4", "flow5", "flight6", "flight7"]))
经过证明,分治法确实要比同步遍历索引慢一些,而且消耗的内存空间更多。
