1. 数据库
1.1 数据库的概念
数据库是一种特殊的文件,比一般的文件增删改查速度快的多。
1.2 MySQL核心元素
- 记录(行)
- 字段(列)
- 数据表(字段、记录的集合)
- 数据库(数据表的集合)
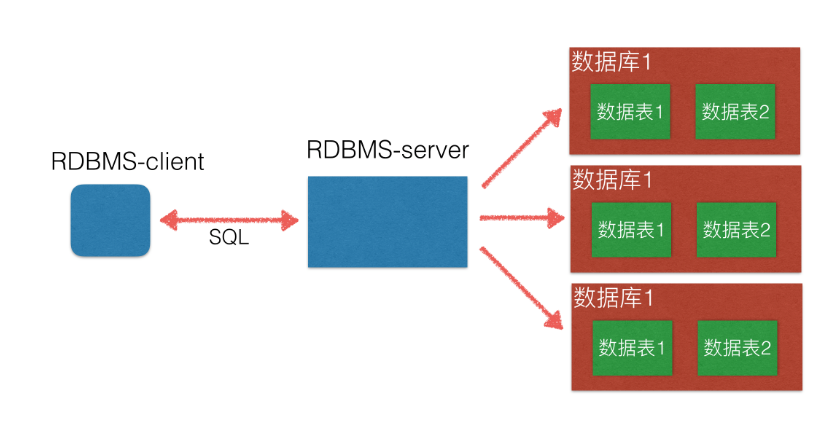
1.3 RDBMS(关系型数据库)
常见的关系型数据库(RDBMS):
- oracle:在以前的大型项目中使用,银行,电信等项目(收费)
- mysql:web时代使用最广泛的关系型数据库(开源)
- ms sql server:在微软的项目中使用
- sqlite:轻量级数据库,主要应用在移动平台
常见的非关系型数据库:
- Redis
- MongoDB
1.4 RDBMS和数据库的关系
有一款图形化界面的软件Navicat,是封装SQL语言的一款软件,可以通过图形化界面手动操作数据库创建等所有操作
2. MySQL数据类型
2.1 常用的数据类型
使用数据类型的原则是:够用就行,尽量使用取值范围小的,而不用大的,这样可以更多的节省存储空间
- 整数:int,bit
- 小数:decimal
- 字符串:varchar,char
- 枚举类型:enum
- 日期时间: date, time, datetime
- 数值类型常用
| 类型 | 字节大小 | 有符号范围(Signed) | 无符号范围(Unsigned) |
|---|---|---|---|
| bit | 2个比特 | 默认表示0 | 只有0和1 |
| tinyint | 1 | -128 ~ 127 | 0 ~ 255 |
| smallint | 2 | -32768 ~ 32767 | 0 ~ 65535 |
| mediumint | 3 | -8388608 ~ 8388607 | 0 ~ 16777215 |
| int/integer | 4 | -2147483648 ~2147483647 | 0 ~ 4294967295 |
| bigint | 8 | -9223372036854775808 ~ 9223372036854775807 | 0 ~ 18446744073709551615 |
- 字符串常用
| 类型 | 字节大小 | 示例 |
|---|---|---|
| char | 0-255 | 类型:char(3) 输入 'ab', 实际存储为'ab ', 输入'abcd' 实际存储为 'abc' |
| varchar | 0-255 | 类型:varchar(3) 输 'ab',实际存储为'ab', 输入'abcd',实际存储为'abc' |
| text | 0-65535 | 大文本 |
- 日期时间类型
| 类型 | 字节大小 | 示例 |
|---|---|---|
| date | 4 | '2020-01-01' |
| time | 3 | '12:29:59' |
| datetime | 8 | '2020-01-01 12:29:59' |
| year | 1 | '2017' |
| timestamp | 4 | '1970-01-01 00:00:01' UTC ~ '2038-01-01 00:00:01' UTC |
2.2 约束条件
- primary key(主键):物理上存储的顺序
- not null(非空):此字段不允许填写空值
- unique(唯一):此字段的值不允许重复
- default(默认):当不填写此值时会使用默认值,如果填写时以填写为准
- foreign key(外键):对关系字段进行约束,当为关系字段填写值时,会到关联的表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并抛出异常
说明:虽然外键约束可以保证数据的有效性,但是在进行数据的crud(增加、修改、删除、查询)时,都会降低数据库的性能,所以不推荐使用,那么数据的有效性怎么保证呢?答:可以在逻辑层进行控制 数值类型(常用)
3. 命令SQL
3.1 基本操作
说明:一切操作基于安装好MySQL之后,且不分大小写
- 连接MySQL:mysql -uroot -p密码
- 退出数据库:exit/quit/Ctrl+d
- 显示数据库版本:select version();
- 显示时间:select now();
- 查看所有数据库:show databases;
- 创建数据库:create database 数据库名 charset=utf8;
- 查看创建数据库所使用的所有语句:show crate database 数据库名;
- 删除数据库:drop database 数据库名;(工作中慎用)
- 使用数据库:use 数据库名;
- 查看当前使用的数据库:select database();
使用数据库后数据表的操作:
- 查看当前数据库中所有表:show tables;
- 创建表:create table 数据表名(字段1 字段类型 字段约束条件,字段2 类型 约束...);
- 查看表结构:desc 数据表名;
- 向表里添加数据:insert into 数据表名 values(0, xx, xxx,...);
- 查看数据表内所有数据(少数据类型):select * from 数据表名;
- 查看表的创建语句:show create table 数据表名;
3.2 修改数据表
- 添加字段:alter table 表名 add 字段名(列) 类型 约束等;
- 修改字段中类型/约束:alter table 表名 modify 字段名(列) 要修改的类型/约束;
- 修改字段名及类型/约束:alter table 表名 change 原名 新名 类型/约束;
- 删除字段(基本不用):alter table 表名 drop 字段(列)名
- 删除表(工作中慎用):drop table 表名;
3.3 增加表内数据
- 全列插入:insert into 表名 values(...);
- 部分插入:insert into 表名(列1,...) values(值1,...)
- 多行插入:insert into 表名 values(...), (...), ...;
3.4 修改表内数据
- 修改:updata 表名 set 列1=值1,列2=值2... where 判断条件;(不加where全部修改为列1=值1...,加上where修改满足判断条件的列1=值1...)
3.5 删除
- 物理删除(不推荐):delete from 表名 where 判断条件;(删除满足判断条件的数据,其它主键不变,删除的主键消失)
- 逻辑删除(推荐):alter table 表名 add 字段名 bit;(添加一个bit类型的字段,表示已经不能再使用了)
3.6 查询的基本使用
- 查询所有列:select * from 表名;
- 条件查询:select * from 表名 where 判断条件;(多行、某行或某个数据)
- 查询指定列:select 列1,列2... from 表名;
- 为列或表指定别名:select 字段名1 as 别名1,字段名1 as 别名1... from 数据表 as 别名;(数据显示按书写顺序显示,可调换前后位置,显示的数据也会调换)
4. 查询的所有常用用法
4.1 条件查询
- 消除重复行:select distinct 字段名 from 表名;
- 比较运算符:select * from 表名 where >、<、<=、>=、=、!=;
- 逻辑运算符:select * from 表名 where 条件1 and、or、not 条件2;
4.2 模糊查询
- select 列1 from 表名 where 列1 like "_表示一个、%表示0个或多个、中文表示满足该位置出现那个中文的数据";
- select 列1 from 表名 where 列1 rlike "正则表达式";
4.3 范围查询
- 查询在in(条件)非连续的条件中的数据:select 列1 from 表名 where 列1 in(...);
- 查询不在not in(条件)非连续的条件中的数据:select 列1 from 表名 where 列1 not in(...);
- 查询在一个连续范围内的数据:select 列1 from 表名 where 列1 between x and y;
- 查询在一个连续范围之外的数据:select 列1 from 表名 where 列1 not between x and y;
4.4 空判断
- 判空:select * from 表名 where 判断对象 is null;
- 判非空:select * from 表名 where 判断对象 is not null; 注意:Python中None不等于""、[]、()、{}等,此处也是。
4.5 排序
- 默认从小到大排训asc:select 列1 from 表名 where 判断条件 order by 列1 (asc可省略);
- 从大到小排desc:select * from 表名 where 判断条件 order by 列1 desc;
例:给定一个students表,查询年龄在18-34岁之间的女性,身高从高到矮排序,如果身高相同的情况下按照年龄从小到大排序,如果年龄也相同按照id从大到小排序。
select * from students where (age between 18 and 34) and gender=2 order by height desc, age asc, id desc;
4.6 聚合函数
- 查总数:select count(*) from 表名;
- 查最大值:select max(*) from 表名;
- 查最小值:select min(*) from 表名;
- 求和:select sum(*) from 表名;
- 求平均值:select avg(*) from 表名;等同于:select sum()/count() from 表名;
- 四舍五入,保留2位小数:select round(avg(*), 2) from 表名;
4.7 分组
- 按照性别分组,查询所有性别:select gender from 表名 group by gender;
- 查询同种性别的姓名:select gender,group_concat(name) from 表名 where gender="男" group by gender;
- having和where:查询出的数据判断用having,未查出的数据判断用where.
4.8 分页
- 限制查询出来的数据个数:select * from 表名 limit 2;限制只显示2个
- 分页显示:select * from 表名 limit (第n页-1【不能为计算式,只能是数字或参数】),数据个数;
4.9 连接查询
- 查询的信息有表A和表B的数据:select ... from 表A inner join 表B on 表A.关联字段=表B.关联字段;
- 查询表A对应的表B:select * from 表A left join 表B on 表A.关联字段=表B.关联字段;(无论如何都会显示完表A,right join on 表名位置相反)
4.10 自关联
例:省级联动 url:demo.lanrenzhijia.com/2014/city06…
- 查询所有省份(省份最大上级是null):select * from areas where pid is null;
- 查询陕西省有哪些市:select * from areas as province inner join areas as city on city.pid=province.aid having province.atitle="陕西省";或者 select province.atitle, city.atitle from areas as province inner join areas as city on city.pid=province.aid having province.atitle="山东省";
- 查询西安市有哪些县城(区):select province.atitle, city.atitle from areas as province inner join areas as city on city.pid=province.aid having province.atitle="青岛市"; 或者 select * from areas where pid=(select aid from areas where atitle="青岛市")
- 子查询:在一个查询信息中查询
例:查出最高的男生信息 select * from students where height=(select max(height) from students);
5. 视图
5.1 视图的概念
通俗的讲,视图就是一条select语句执行后返回的结果集。也是对若干基本表的引用,一张虚表,指向各个表的内存地址(不可操作,只可查,基本表数据发生了改变,视图也会跟着改变)
5.2 视图的定义
建议以v_开头
create view 视图名称 as select语句;
5.3 查看视图
查看表会将所有的视图也列出来
show tables;
5.4 使用视图
视图的用途就是方便查询
select * from v_stu_score;
5.5 删除视图
drop view 视图名称;
例:
drop view v_stu_sco;
例:视图demo
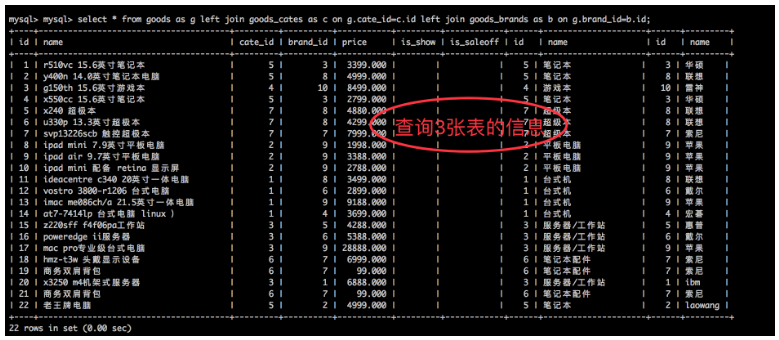
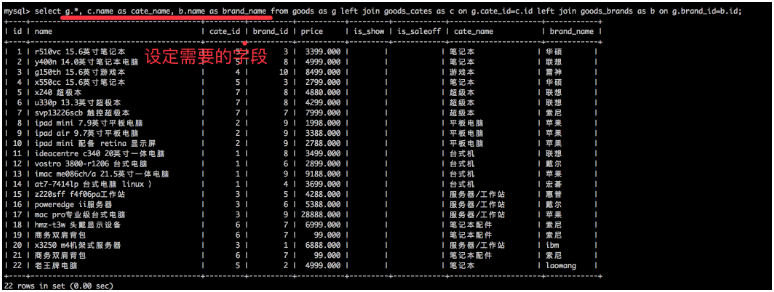
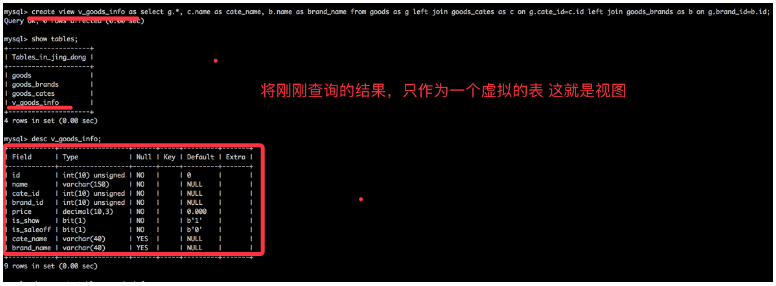
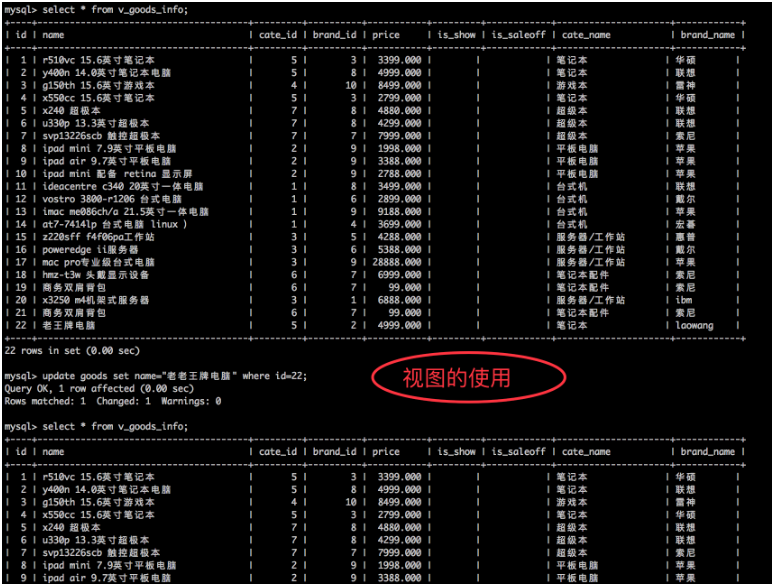
5.6 视图的作用
- 提高了重用性
- 对数据库重构,却不影响程序的运行
- 提高了安全性能,可以对不同的用户开放
- 让数据更加清晰
6. 事务
6.1 为什么要有事务
- 事务广泛的运用于订单系统、银行系统等多种场景。
- 如果A给B转账,A账户扣钱之后,系统出了故障,B没有收到钱,而A也白白损失了钱,这种情况是不被允许发生的
- 所谓事务,它就是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
例:要么转账成功,要么转账失败,不存在转账过程中流失的问题。
6.2 事务的四大特性(简称ACID)
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability) 可以用start transaction语句开始一个事务,然后要么使用commit提交将修改的数据持久保存,要么使用rollback回滚所有的修改,事务SQL的样本如下:
start transaction;
select balance from checking where customer_id = 10233276;
update checking set balance = balance - 200.00 where customer_id = 10233276;
update savings set balance = balance + 200.00 where customer_id = 10233276;
commit;
一个好的事务应该满足上述4大特性
6.3 事务命令
表的引擎类型必须是innodb类型才可以使用事务,这是mysql表的默认引擎
查看表的创建语句,可以看到engine = innodb
- 开启事务:begin、start transaction;
- 完成后提交:commit;
- 误操作后后退回滚操作:rollback;
7. 索引
数据量很大时,查询数据会很慢,可以添加索引来优化查询。
7.1 索引的概念
索引是一种特殊的文件,它们包含着对数据表里所有记录的引用指针。
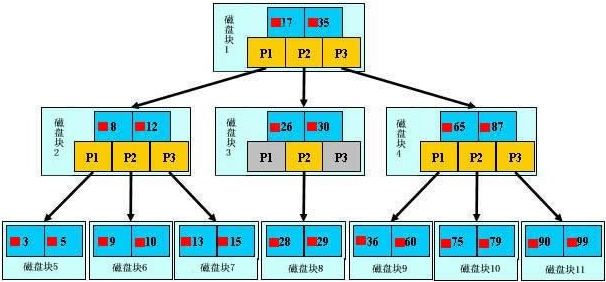
7.2 索引的原理
字典目录就是典型的索引,数据库也可以用此类方法查询,比如,把数据分成段,然后分段查询,如果有1000条数据,要查第250条,每100条分成一段,第三段就可以找到第250条数据,除去了90%无用效数据。
7.3 索引的操作
- 创建索引
- 如果指定字段是字符串,需要指定长度,建议长度与定义字段时长度一致
- 字段类型如果不是字符串,可以不填写长度部分
create index 索引名称 on 表名(字段名称(长度))
- 删除索引:drop index 索引名称 on表名;
例:create table test_index(title varchar(10));
7.4 注意事项
建立太多的索引将会影响更新个插入的速度,因为它需要同样更新每个索引文件,对于一个经常需要更新和插入的表格,就没必要建立索引了,对于较小的表,排序的开销不会很大,也没必要建立另外的索引。建立索引会占用磁盘空间
8. MySQL主从同步配置
8.1 主从同步的定义
主从同步使得数据可以从一个数据库服务器复制到其他服务器上,在复制数据时,一个服务器充当主服务器(master),其余的服务器充当从服务器(slave)。因为复制是异步进行的,所以从服务器不需要一直连接着主服务器,从服务器甚至可以通过拨号断断续续地连接主服务器。通过配置文件,可以指定复制所有的数据库,某个数据库,甚至是某个数据库上的某个表。 主从同步的好处:
- 通过增加从服务器来提高数据库的性能,在主服务器上执行写入和更新,在从服务器上向外提供读功能,可以动态地调整从服务器的数量,从而调整整个数据库的性能
- 提高数据安全,因为数据已复制到从服务器,从服务器可以终止复制进程,所以,可以在从服务器上备份而不破坏主服务器相应数据
- 在主服务器上生成实时数据,而在从服务器上分析这些数据,从而提高主服务器的性能
8.2 主从同步的基本步骤
有很多种配置主从同步的方法,可以总结为如下的步骤:
- 在主服务器上,必须开启二进制日志机制和配置一个独立的ID
- 在每一个从服务器上,配置一个唯一的ID,创建一个用来专门复制主服务器数据的账号
- 在开始复制进程前,在主服务器上记录二进制文件的位置信息
- 如果在开始复制之前,数据库中已经有数据,就必须先创建一个数据快照(可以使用mysqldump导出数据库,或者直接复制数据文件)
- 配置从服务器要连接的主服务器的IP地址和登陆授权,二进制日志文件名和位置
9. 服务器的动态资源请求
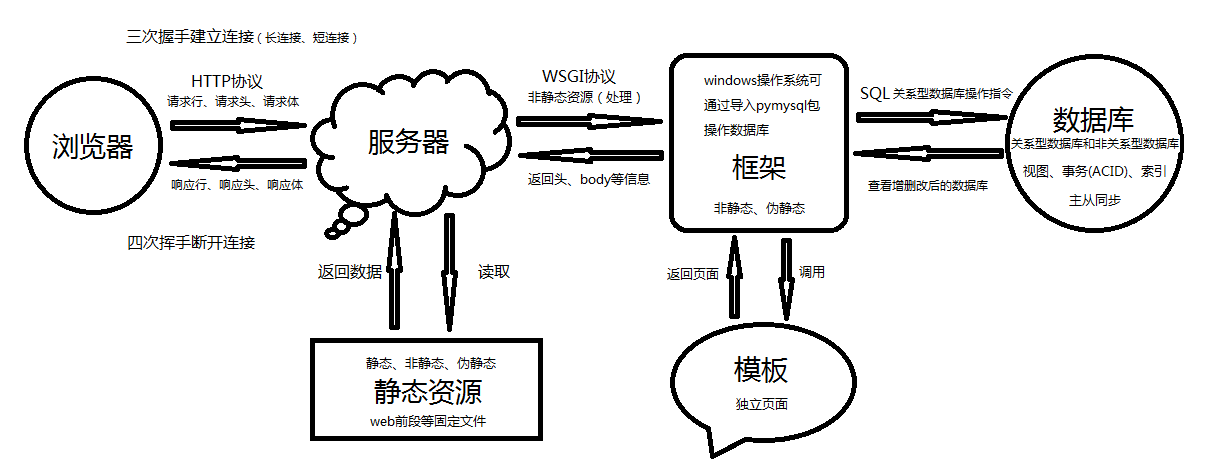
9.1 浏览器请求动态页面的过程
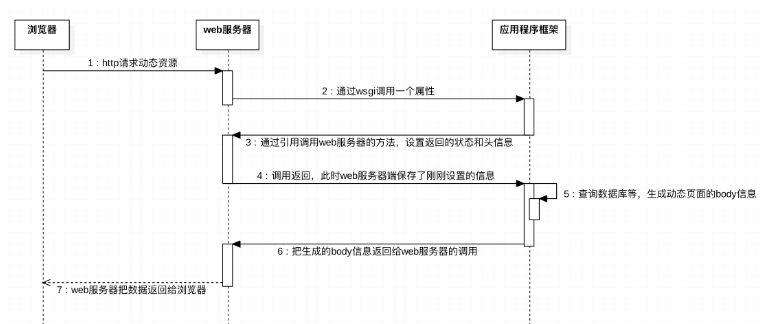
9.2 WSGI
WSGI允许开发者将选择web框架和web服务器分开。可以混合匹配web服务器和web框架,选择一个适合的配对。比如,可以在Gunicorn 或者 Nginx/uWSGI 或者 Waitress上运行 Django, Flask, 或 Pyramid。真正的混合匹配,得益于WSGI同时支持服务器和架构:
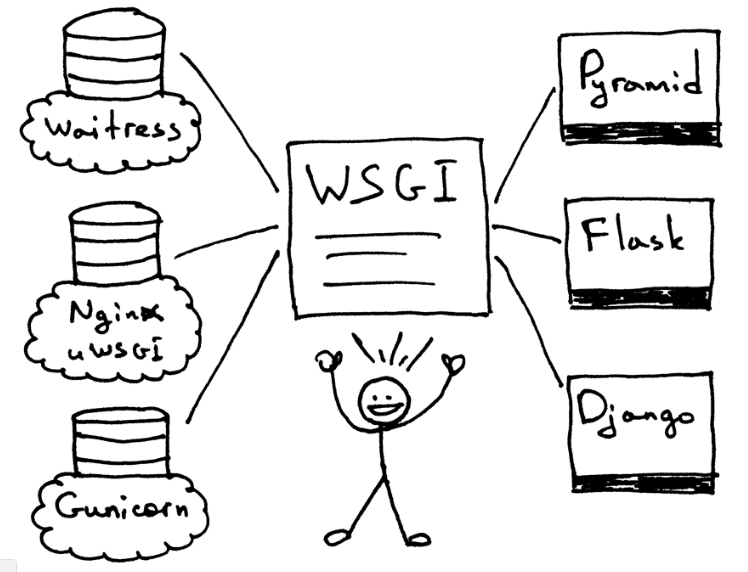
9.3 定义WSGI
只要求Web开发者实现一个函数,就可以响应HTTP请求
def application(environ, start_response):
start_response("200 OK", [("Content-Type", "text/html")])
return "Hello World!"
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
- environ:一个包含所有HTTP请求信息的dict对象;
- start_response:一个发送HTTP响应的函数。
10. web总体简图