

概述
String类无疑是日常开发中的使用最频繁的类之一。其被final修饰:
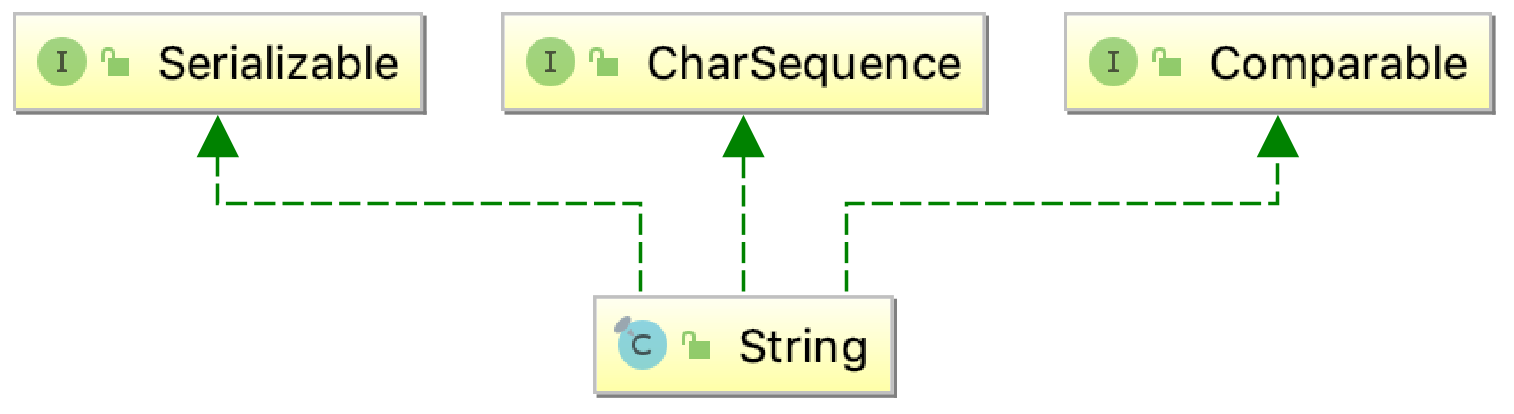
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
因此可知String类是一个不可变类,且实现了Serializable,Comparable和CharSequence接口。
阈
hash
hash阈来用缓存字符串的hash code,默认为0。
/** Cache the hash code for the string */
private int hash; // Default to 0
serialVersionUID
String类实现了Serializable接口,因此支持序列化和反序列化。serialVersionUID字段则是用来在运行时判断类版本的一致性。
value[]
String类用一个char数组来存储真实字符序列,就好比Integer中的字段value表示Integer对象的实际值。并且这个数组还被final修饰了,这正是我们所熟知的:String的内容一旦被初始化后,其值就不能再被修改了。当然,通过反射还是可以修改String内容的,不过没啥意义。
/**The value is usesed for character storage.*/
private final char value[];
构造函数
在jdk8中有14中不同的String类构造函数,下面记录一些常用的。
public String()
很明显,String类显示的声明了一个空构造函数。
public String() {
this.value = "".value;
}
即使是空的构造函数,但还是会创建一个String对象,因此,下面这种字符串的声明方式,不仅鸡肋而且浪费恐怖,不提倡:
String str = new String();
str = "realString";
public Sting(String)
入参为一个字符串的构造函数。其直接将入参字符串的value域和hash域直接赋值给目标String。且String类是不可变类,因此不会对原有的入参字符串产生副作用。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
在实际开发中,我们应该直接采用字面量赋值的方式来初始化String对象(记为方法一),而不是通过上述这个构造函数new一个String对象(记为方法二)。这是因为:
- 方法一构造一个新的字符串时,编译器会优先从常量池中(堆中的一块专门区域)查找是否已经存在这个字符串字面量。如果存在则直接返回该对象地址,否则构造一个新对象并保存一份在常量池中。这实现了一种类似缓存的机制,可以避免不必要的开销。
- 方法二new一个String对象时,即使常量池在存在该对象的字面量,但还是会要求编译器在堆中开辟一个新的内存空间来保存新new出来的对象。
public static void main(String[] args){
String a = "string";
String b = "string";
String c = new String("string");
String d = new String("string");
System.out.println("a==b: " +(a == b));
System.out.println("a==c: " +(a == c));
System.out.println("c==d: " +(c == d));
}
---------------output------------
a==b: true // a和b都是常量池中同一个String对象
a==c: false // a是常量池中的对象,但c是堆内存中新申请的一块空间
c==d: false // 虽然在常量池中存在字面量"string",但c和d都是堆内存中新建立的独立对象
public String(char[])
入参是一个char数组,构造器调用Arrays.copyOf()方法将入参的字符序列依次复制成一个新的String对象,且不会对入参有副作用。
public String(char value[]) {
this.value = Arrays.copyof(value, vlaue.length);
}
方法
equals(Object)方法
该方法重写了Object的equals方法,用来判断两个字符串是否包含相同的字符序列,最大时间复杂度为O(n),其中n字符串长度。
public boolean equals(Object anObject) {
// 1. 引用同一对象,判定true
if (this == anObject) {
return true;
}
// 2. 入参不是String类型,判定false
if (anObject instancof String) {
String anotherString = (String) anObject;
int n = value.lenth;
// 3. 长度不匹配,判定false
if (n == anotherString.value.length) {
char v1[] = value; // 写成char[] v1 = value,更规范点
char v2[] = anotherString.value;
int i = 0;
// 4. 逐字符比较,如不等,判定false
while (n-- != 0){
if (v1[i] != v2[i]) {
return false;
}
i++;
}
}
// 5. 否则,判断true
return true;
}
return false;
}
compareTo(String)方法
该方法实现了Comparable接口的compareTo方法,用来按字典顺序比较两个字符串。该比较是基于字符串中各个字符的Unicode值。
字典序
因为该方法比较两个字符串的大小,采用的是字典序,因此有必要了解一下字典序。
字典序定义:如果这两个字符串不同,那么它们要么在某个索引处的字符不同(该索引对二者均为有效索引),要么长度不同,或者同时具备这两种情况。如果它们在一个或多个索引位置上的字符不同,假设 k 是这类索引的最小值;则在位置k上具有较小值的那个字符串(使用 < 运算符确定),其字典顺序在其他字符串之前。在这种情况下,compareTo返回这两个字符串在位置k处两个char值得差,即值:
this.charAt(k) - anotherString.charAt(k);
如果没有字符不同的索引位置,则较短字符串的字典顺序在较长字符串之前。在这种情况下,compareTo返回这两个字符串长度的差,即值:
this.length() - anotherString.length();
入参
anotherString: String,要比较的字符串
返回值
- 正数:按字典序,调用者位于入参字符串之后
- 负数:按字典序,调用者位于入参字符串之前
- 0:两者相等,此时若调用equals方法肯定是返回true
源码分析
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = min(len1, len2); // 取两字符串长度的最小值
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) { // 只遍历min(len1, len2)次
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) { // 某个索引处字符不同,则返回字符的差值
return c1 - c2;
}
k++;
}
// 如果前个字符都相同,则返回长度差
return len1 - len2;
}
这个方法写的很巧妙。从初始索引开始,如果两个对象能比较字符的地方都比较完了还相等,就直接返回长度差。此时如果两个字符串长度相等,则返回的刚好就是0,巧妙地判断了返回值的三种情况。且是的最大时间复杂度为T=O(n),其中n为两个字符串的长度最小值。
可能有人好奇,为什么没有在方法体中看到对入参为null的防护?这是因为Comparable接口中已经定了,当入参为null时,compareTo方法会直接抛出NullPointException异常。
startsWith方法
startsWith(才发现原来中间还有个s,代码补全的锅!)用来判断字符串是否以指定的前缀开始。其包含两种重载方法:
startsWith(String, int)
入参
- String prefix: 前缀
- int toffset: 在此字符串中开始查找的位置
返回值
- true: 字符序列是此对象从索引 toffset 处开始的子字符串前缀
- false: toffset为负或大于此String对象的长度或字符序列不是此对象从索引 toffset 处开始的子字符串前缀
源码分析
public boolean startsWith(String prefix, int toffset) {
char ta[] = value; // 变量名为啥用ta,难道是target?
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
//如果起始地址小于0或者大于自身对象长度,返回false
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
// 从尾开始比较
while (--pc >= 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}
startsWith(String)
这个方法直接调用了startsWith(String, 0):
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
}
endsWith(String)
相比startsWith,endsWith只有一种方法签名。而且,endsWith的实现方式很巧妙,直接借助了startsWith(String, int)方法:
public boolean endsWith(String suffix) {
// 将判断是否存在指定后缀转换为去判断是否是指定前缀
return startsWith(suffix, value.length - suffix.value.length);
}
replace方法
replace包含两种重载形式,一种是替换字符串中指定字符,另一种则是替换指定字符序列。
replace(char, char)
直接上源码,就是逐字符校验,讨巧之处在于先定位到旧值出现的位置,才去new一个char数组保存目标字符串。
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
// 找到oldChar最开始出现的位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
// 从那个位置开始依次遍历,用新值代替出现的旧值
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) { // 直接for循环拷贝
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}
