

最近由于公司事情多,忙于项目发布,所以好久都没有更新,现在项目上线了可以稍微有空继续整理了。
今天要说的是MySQL中的索引问题,这也是在发布项目时因为有一条SQL没有使用索引直接导致该模块整个不能使用,发布失败!也是借此机会将自己所了解和学习到的索引的相关知识做一个整理。
众所周知,索引不是一句两句,也不是一篇两篇能解释完尽的,所以这里会分成好几篇来讲解,并且后续会持续的更新。如果文章中有不正确的地方希望大家能指正,互相讨论,共同进步。
此次废话略多,接下来进入正文,话不多说先上图。
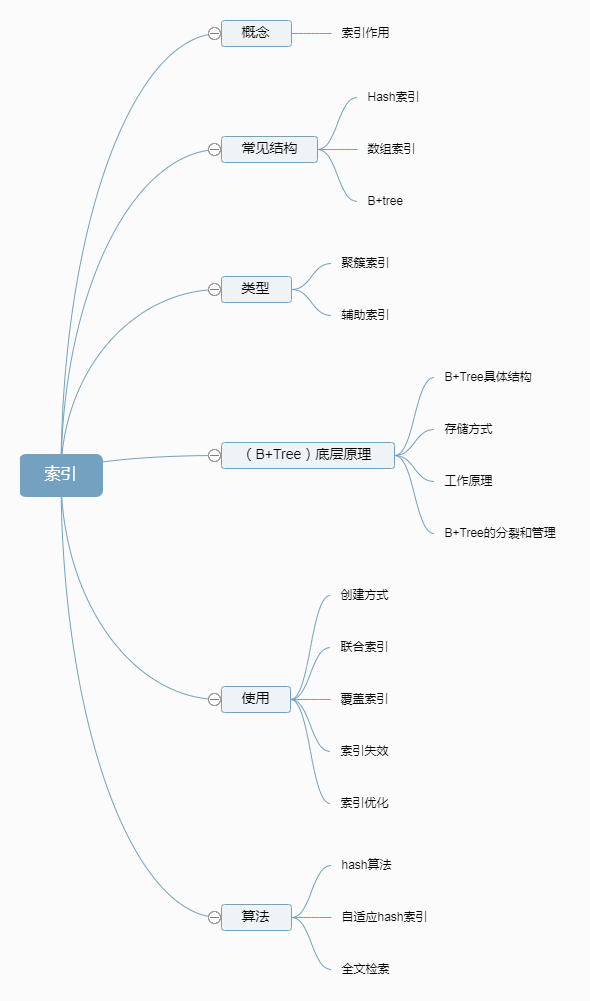
概念
索引:是对数据库表中一列或多列的值进行排序的一种存储结构,使用索引可快速访问数据库表中的特定信息
这是比较官方的一种解释,其作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容,所以简而言之索引就是用来提高查询性能的一种手段。
优点:
- 大大加快数据的检索速度
- 加速表与表之间的连接
- 在使用分组和排序字句进行数据检索时,可以显著减少查询中分组和排序的时间
缺点:
- 索引的存储需要额外的物理空间
- 对表中数据进行增删改是,也需要维护索引,降低了数据的维护速度
常见结构
适用于索引的数据结构主要有哈希表,有序数组,树,这里简单介绍常见的三种。
-
哈希表结构
哈希表结构就是Key-Value的键值对的方式,如此查询的时间复杂度只有O(1),查询速度比较快,但是这种结构不适用于范围类型的查询。
哈希表的底层使用的是数组+链表,通过hash算法对key进行计算得到数组中的槽位,然后将value存于该槽位,如果已经有数据了,则以链表的方式往后排列。自适应哈希索引使用的就是这种结构。一般这种结构在NoSQL引擎中使用比较多。 -
有序数组
使用有序数组来做索引在等值查询和范围查询中具有很高的性能,但是在进行插入和删除时就比较麻烦,所以只适合用于静态存储引擎。
-
B+Tree B+Tree是在搜索树的基础上发展过来的,其特点就是扇出比较高,对于千万级数据量的搜索只要2-4次I/O。需要注意的是B+Tree的数据全部放在叶子节点。在我们常用的InnoDB引擎中默认的索引都是这种数据结构实现的。
索引类型
在InnoDB中其实只有两种类型的索引聚簇索引和辅助索引(非聚簇索引)。这两种索引都是使用的B+Tree来实现的。下面详细的介绍一下。
聚簇索引
我们知道在InnoDB中,每一张表都会有主键,如果没有显示指明主键,那么会使用唯一约束字段作为主键,如果也没有唯一约束,那么InnoDB会使用一个6个字节的指针row_id作为这个表中的主键。
而聚簇索引就是建立在主键上面的索引,因此也称为主键索引,同时叶子节点中存放的即为整个表的行记录数据,因此也将聚簇索引的叶子节点称为数据页。
一般情况下,有多个索引时优化器会优先使用聚簇索引来进行查询。
辅助索引
对于辅助索引,也称为非聚簇索引,在辅助索引的叶子节点中并不包含行记录的全部数据,叶子节点保存的是相应行数据的聚簇索引键。一个表上面只能有一个聚簇索引,但是可以有多个辅助索引。
当使用辅助索引来查询时会先拿到主键索引的主键,然后再通过主键索引得到完整的行记录,回到主键索引的这个过程称为回表。
索引(B+Tree)数据结构
所有的系统都有一个最小的存储单元,Windows中的文件系统是4kB,在InnoDb引擎中最小的存储单元是16KB,这个在单元在InnoDB中可以称为一个“页”(Page)。
B+Tree结构
前面我们说过在InnoDB中索引的数据结构是B+Tree,那么B+Tree是个什么样的结构呢?
B+Tree是目前关系型数据库系统中最为常用和最为有效的索引,其类似于二叉树(B+Tree不是二叉树),可以根据键值(key-value)快速找到数据。
B+Tree树索引并不能找到一个给定键值的具体行,它只能找到被查找的数据行所在的页,然后把页读入内存,再使用二分法得到要查找的数据。
这里对B+Tree做个简单的定义:它是一种平衡查找树,在B+Tree中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各个叶子节点指针进行连接。如下图是一个简单的B+Tree结构图,其高度为2,每页可以存放4个数据页,扇出为4。
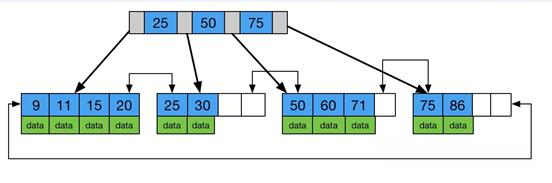
B+Tree存储
上面说了InnoDB使用页来管理存储,所以所有的表数据都是存放在B+Tree的叶子节点,非叶子节点存放索引值和指针。
之前说过MySQL通过索引只需要2-4次的I/O就能找到对应的数据,这是为啥呢?我们接下来可以简单的分析一下:
假设一行记录1KB=1024B大小,那么主键ID为BIGINT类型就是8个字节大小(8B),而指针是6B,那么一个16KB大小的页可以存储16 * 1024/(8+6) = 1170 个指针,那么高度为2的B+Tree大概可以有1170 * 16 =18720条记录,高度为3的B+Tree可以有1170 * 1170 * 16 = 21902400条记录,所以千万级的表通过索引只要2-4次的I/O就能将数据查询出来。
小结
从上面的推理可以得出主键长度越小,那么效率就越高。 所以从性能和存储空间方面考量,自增主键往往是更合理的选择。
