

最近准备做一个关于学习编程类的app和小程序,为什么选择做移动端的呢?因为网页版的有太多太多了,像菜鸟教程,自学网啊等等,而相应的app实在太少了,免费的几款,类似《软件工程师》,《EK教程》之类的,体验差而且使用起来也不是那么舒服。所以就产生了这么一个想法。
要想做这么一个东西出来,最主要的就是数据的问题。如果有数据了,那么其他的功能就是只是体力活了。
那么数据如何来呢?
我慢慢一个一个按照我要做的教程大纲,一个一个百度->查询->入库,但是这都9102年了,这样做就是一个庞大的工作量和十足的耐心问题了,我是没有那么多时间和耐心了。
所以要完成这个工作量,唯一的方法那就是爬虫了。爬虫有很多框架,但是作为一个IOS开发,我只会php啊,经过研究,最后决定使用phpSpider这个框架来完成我的目的。
而要学习phpSpider的使用,如果只是看开发文档,要完成所有功能,还是远远不够的,文档毕竟是个大的框架,告诉你怎么使用,但是在实际操作中,还有各种各样的坑需要自己慢慢研究。而如果百度或者谷歌的话,那么就会发现一个问题,这个问题就是国内文章的通病,你抄我的,我抄你的,没有实际解决问题的东西,所以这就是我写这个东西的原因,帮你填上哪些让我掉过的坑。
所以,这是一个我的学习和研究历程。我的目标网站是菜鸟教程。
废话不多说了,开始进入我的历程。
安装之类的,我就不再说了,直接正题。
我要完成的大致功能如下:
而菜鸟教程的布局和我的差不多,这就是我选择菜鸟的原因。
首先从最简单的一级菜单入手
1 一级菜单的获取
爬虫的配置文件如下
'domains' => array(
'www.runoob.com',
'runoob.com',
),
'scan_urls' => array(
"http://www.runoob.com/index.html", // 随便定义一个入口,要不然会报没有入口url错误,但是这里其实没用
),
'list_url_regexes' => array(
"http://www.runoob.com/index.html", // 主菜单
),
'content_url_regexes' => array(
"http://www.runoob.com/index.html",
),然后分析fields应该如何完成
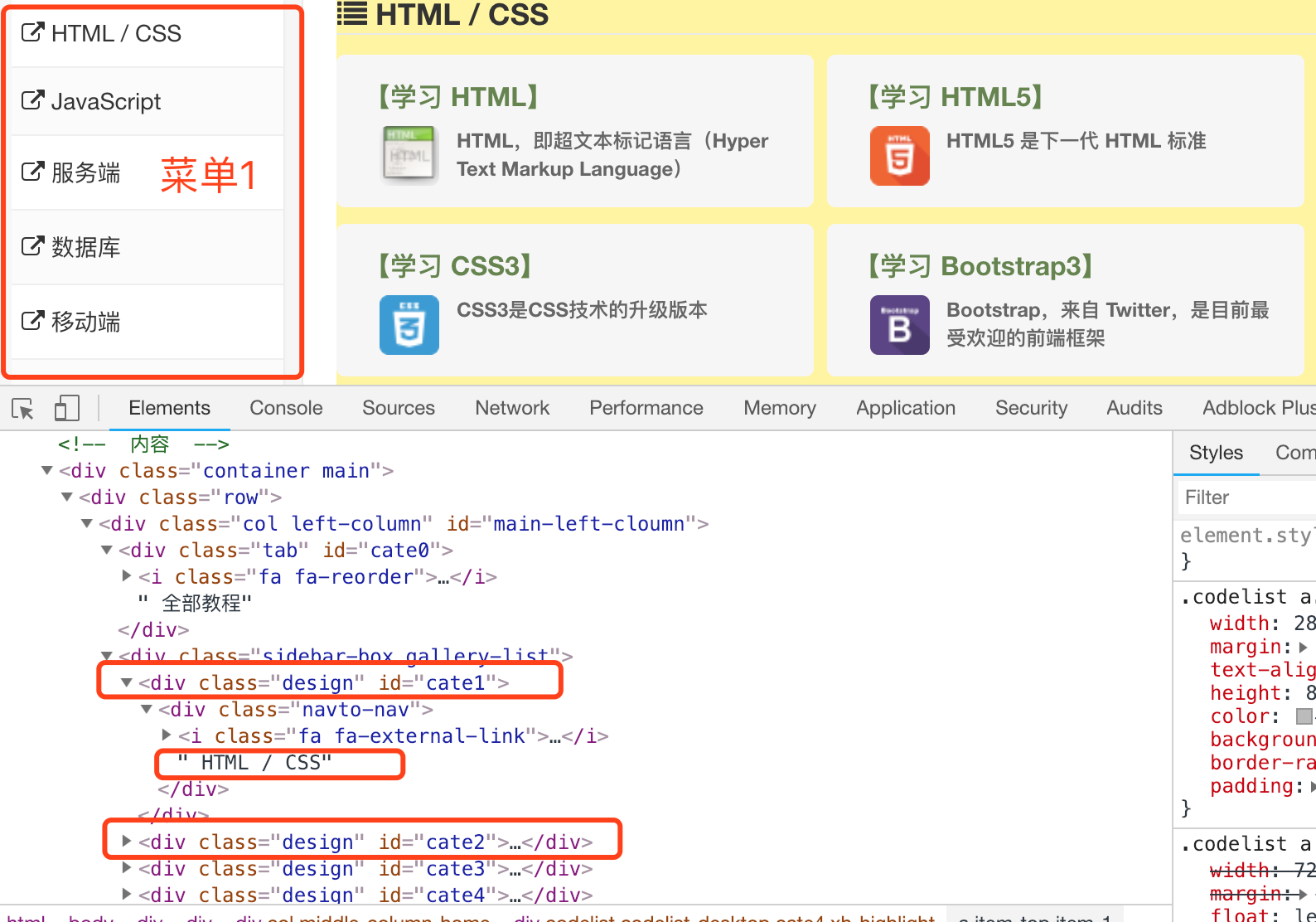
要想取得HTML/CSS,观察<div>标签的,只需要重复取id包含cateX的<div>标签,就可以取出来我们需要的数据
那么我们的fields应该这样来
array(
'name' => "column",
'selector' => "//div[contains(@id,'cate')]//text()", //后面的text()直接取得内容,因为div下面的标签<i>对于我们来说没有实际意义
'required' => true,
),好了这样我们
$spider->start();
会出现我们想要的结果么?
其实并不能,刚才我们也说了只需要循环取id包含cate的就可以,但是我们的fields并没有什么循环,注意:这里要添加上
'repeated' => true, array(
'name' => "column",
'selector' => "//div[contains(@id,'cate')]//text()",
'required' => true,
// 定义该field抽取到的内容是否是有多项, 默认false,赋值为true的话, 无论该field是否真的是有多项, 抽取到的结果都是数组结构
'repeated' => true,
),这个时候我们在回调函数打印$data
$spider->on_extract_field = function($fieldname, $data, $page){
print_r($data);
}
OK 我们需要的东西已经看见了,之后就是处理空内容的问题
这就是最简单的一级栏目获取的方法。
