

最近收集的数据,硬件:
9900K AVX2 = 3.6*8*32/1000 = 0.92T FP32 @ 95W
1080Ti = 1.48*3584*2/1000 = 10.6T FP32 @ 250W
2080Ti 不用 Tensor Core = 1.55*4352*2/1000 = 13.4T FP32 = 26.8T FP16 @ 250W
2080Ti 用 Tensor Core = 1.55*544*64/1000 = 54T FP16 = 108T INT8 @ 250W
Tesla T4 用 Tensor Core = 65T FP16 = 130T INT8 @ 75W,现在能直接买到的最高能效,但很贵

TPU v1 = 92T INT8 @ 40W
TPU v2 每组 4 个芯片是 45*4=180T bfloat16,有人猜是 200~250W
TPU v3 每组 4 个芯片是 420T bfloat16,有人猜是 200W,指标特高,但买不到

iPhone A12 NPU = 5T INT8 @ 未知 W,这个性能很高了
麒麟 980 NPU = 未知 @ 未知 W,还没找到准确数字,宣传稿说 970 是 1.9T FP16,这个数字肯定是错的,哪位知友有真实数据还请告知
骁龙 8150(855)= 7T INT8 @ 满载 W,这个是 CPU+GPU+DSP 凑一起的数据,无可比性
联发科 P90 NPU = 2.2T INT8,这个在 AI-Benchmark 目前安卓第一,运行一些模型比 980 和 8150 还快,可见各家对于实际网络的优化还是有差异,不知是否是对于 NNAPI 的优化不同:
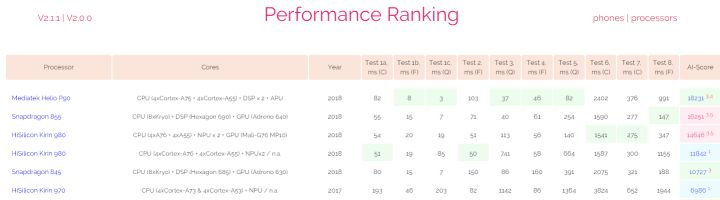
寒武纪 MLU100 = 166T INT8 @ 110W
昇腾 910 = 512T INT8 @ 350W,估计是多个芯片加起来
昇腾 310 = 16T INT8 @ 8W(可见 2T INT8 / W 是目前典型的前沿水准)

检验:VGG16 = 30 GOPS,1080Ti FP32 在 batch 16 做 inference 是 388 image/s,相当于 11.6T FP32(因为有 Winograd 所以比理论值高)。
推理/矩阵/异构计算:
Naive 做法是 im2col + gemm。更好做法是看情况用 Winograd / FFT,也需要 kernel tuning。CPU 多线程用 OpenMP / Intel TBB。Web 多线程用 WebWorkers。
iOS 官方:CoreML(桌面 + iOS,会使用 GPU Metal 和 NPU)。底层还有 BNNS(CPU),MPSCNN(GPU Metal)。
安卓 官方:NNAPI(会使用 CPU NPU 等等)。
GPU 官方:NVIDIA CUDA cudnn TensorRT cublas nccl,AMD ROCm MIOpen。另外都可以用 OpenCL。其实 Intel GPU 也有 clDNN plaidML。NVIDIA 还有个 NVPTX(对应 LLVM target)。
CPU 官方:Intel 有 MKL。
ARM 官方:ARM 有 ACL。骁龙有 SNPE。
FPGA 官方:Xilinx 有 ML Suite,各家都有自己的。
Web:常用技术有 WebAssembly WebGL WebGPU,推理框架有 WebDNN ONNXJS TF.js 等等。可以用 LLVM 编译到 WebAssembly。
简化库:TF 有 JAX,MXNet 也有类似的。另外还有 OpenBLAS / LAPACK 之类。
下面的框架都很快,适合 iOS / 安卓 ARM:
FB NNPACK(桌面CPU + ARM):Maratyszcza/NNPACK
腾讯 FeatherCNN:https://github.com/Tencent/FeatherCNN
腾讯 NCNN:Tencent/ncnn
百度 Paddle Mobile:https://github.com/PaddlePaddle/paddle-mobile
小米 MACE:https://github.com/XiaoMi/mace
还有 FB QNNPACK(跑量化后模型)。
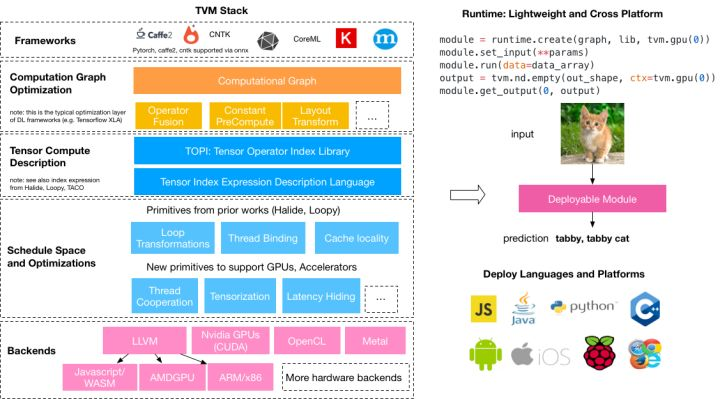
相关编译器:TVM // TF XLA // FB Tensor Comprehensions // Halide // Polyhedral Compilation // The Tensor Algebra Compiler (taco) // DLVM // NNVM 等等。
如您发现遗漏/错误,欢迎留言,谢谢。
