

本文首发于微信公众号“脑人言”(ibrain-talk)和知乎专栏“群体智能”,授权转载请联系后台管理员。
Original Title:The Entropy of Artificial Intelligence and a Case Study of AlphaZero from Shannon's Perspective
Original Pre-print:arxiv-version
For original link,please visit Dive into the Origin of the Intelligence and Research Gate
简要解读
最近发布的AlphaZero算法在国际象棋、shogi和Go游戏中超越了人类顶级棋手,这提出了两个开放性的问题。
- AlphaZero系统或者其它智能系统的智能如何度量?是否存在终极智能?
- AlphaZero系统中复杂的强化学习和自对弈(self-play)范式是否对应简洁的信息论模型,从而能够支持对其学习过程的量化分析,并发现更多可一般化的认识。
针对上述两个问题,本文作了初步的尝试:
- 通过智能-信息统一模型视角,可以将智能系统建模为外部和内部通信信道。通过引入智能熵的概念,智能系统的智能演化过程可以看作解析信道传递的信息,不断提升智能熵的过程。在特定环境和给定任务的前提下,智能熵存在上界并且该上界可以由外部信道容量严格界定——从而引入智能容量的概念。
- AlphaZero系统中,两个对弈的智能体是在协同演化,通过迭代编译码试图逼近智能容量。因此,可以将其建模为经典的Turbo编码和迭代译码架构,并且已经有EXIT-chart这一经典量化分析工具,可用于其学习演化过程的量化分析。
最后,本文基于上述认识,给出了如何构建强人工智能的理论和应用方面的粗浅认识,供后续深入研究。
一、简介
在图1中,我们将(3)中提出的通用智能通信模型(UICM)应用到AlphaZero上。具体而言,AlphaZero中有两个智能体可以自对弈,并且它们通过环境彼此交互,例如19*19棋盘。每个智能体在做出决定和采取下一步行动之前,观察其对手的移动,评估棋盘的情况,识别模式并预测未来的行动。信息交换和处理流程等价于智能体A和智能体B之间的双向交互香农通信模型,其中通信信道是棋盘,DecX_Ext是外部信道译码器,SrcX和DesA是信息源和信息宿,FX是反馈学习通路,基于历史经验所更新的DesX也可以促进SrcX的演化,支撑更有效的棋路(行动)。因此两个自对弈AlphaZero智能体的感知和行为可以被建模为译码器和编码器,实现智能体和环境之间的交互。
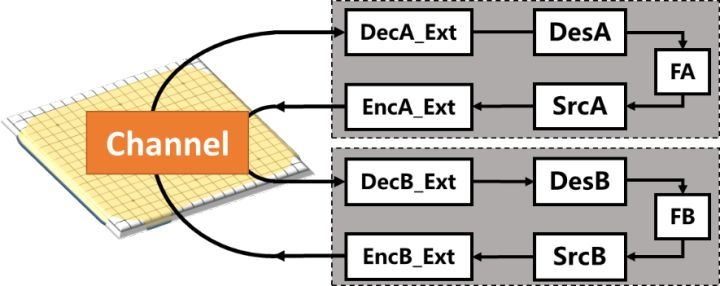
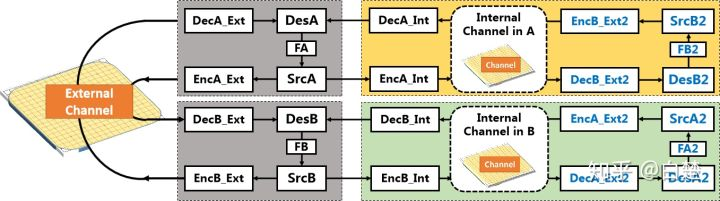
在国际象棋或围棋中,两个智能体都试图赢得比赛,因此每个智能体都试图预测彼此的行为。因此,我们可以通过添加内部通信通道来概括香农的通信模型,如图2所示。
在智能体A中,它构建内部环境模型,包括棋盘、智能体B和评价者critic(图中未示出),用于评估获胜概率。因此,智能体A可以在其内部通过虚拟棋盘与虚拟智能体B进行对弈。这种内在的思维过程也可以被建模为双向通信。为了区分不同的信道,我们将真实智能体A和B之间的通信表示为外部(External,简称Ext)通信,而智能体内部的通信表示为内部(Internal,简称Int)通信。每个AlphaZero智能体可以建立内部通道或环境模型,也建立对方智能体的模型,预测其可能采取的行动并评估效果,同时学习对手智能体的行为。
二、智能熵和智能容量
AlphaZero中单个智能体的目标是获得更多对手信息,从而采取更有效的行动。具体而言,在两个智能体的“零和博弈”中,智能体A译码的关于智能体B的源信息量表示为IB-A,智能体B译码的关于智能体A的源信息量表示为IA-B。智能体A占主导地位的条件是IB-A >IA-B,即智能体A更高概率确定其对手的感知-行动策略,从而采取更有效的行动。
因此,本文提出了智能熵的概念—即智能体可从外部通信信道(环境)中获取的互信息量,可以由熵来量化,而后者不能超过外部通信信道的香农容量。
以AlphaZero为例,其获得的信息熵应当为自对弈智能体的最大值。AlphaZero的智能熵可以被定义为能够获取的关于环境(包括环境中的对弈者)的信息量,因此可以被外部信道的信道容量严格界定。在围棋中,外部信道是361个落点的棋盘,其时空序列最多包含361!种状态,因此其信道容量C可以很快界定如下。
Imax(A,B) = MAX ( IB-A, IA-B ) ≤ C ≤ log2(361!) ≈ 2552.
式中的不等号代表了围棋的规则可能限制了某些状态,因此信道容量有所下降,但是这个可以另行严格测算,不影响本文的结论——在给定环境(如围棋棋盘)和任务(如围棋对弈)的前提下,智能体的智能熵存在上界——智能容量,用于表征所能达到的最高智能水平,即在给定环境和任务下的终极智能度量。
三、AlphaZero自对弈模型中蕴含的迭代译码架构
在明确了智能容量或外部信道容量的前提下,我们以AlphaZero为案例,研究如何通过设计译码器,从而从外部信道(环境)中获取比人类智能更高的智能熵,并更接近围棋对弈的智能容量。
两个对弈的智能体在AlphaZero的内部通信信道中协同进化,并且每个智能体之间相互迭代,解析来自外部和内部通信信道的信息。我们可以将每个智能体作为一个译码器,作为信息论领域(3)中著名的Turbo译码器的分量译码器。
这种Turbo迭代设计在逼近香农容量纠错码设计方面曾经取得了历史性的突破。在其发明前的若干年,一度认为香农信道容量远不可在有限编码长度和计算资源条件下实现。当下,类似的困局也在若干人工智能领域重演,而AlphaZero在棋类对弈这一细分领域实现了突破,本文认为,从信息论的角度出发,其成功主要原因在于迭代译码思想。
AlphaZero的迭代译码结构可以直接从图2中提取,但是我们在图3中重新绘制它以使其信息流动关系更加清楚。
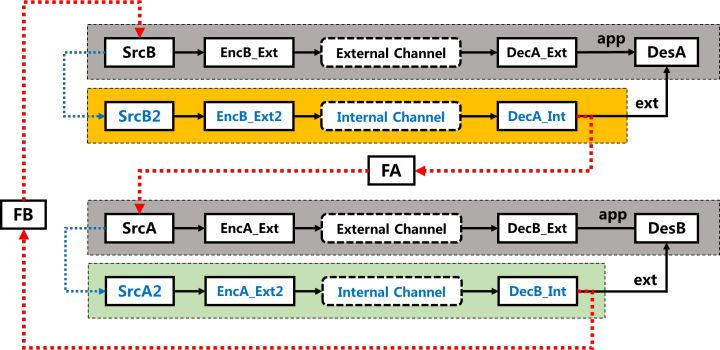
每个AlphaZero智能体构成一个译码器,用于从外部信道和内部信道中提取关于其对弈智能体的信息。该译码器可以输出外部信息,以逐步降低关于其对手智能体信息的不确定性。
传统的Turbo译码器与提出的Turbo译码器的主要区别在于信息源。交互式Turbo译码器中的两个分量译码器试图从单个信息源恢复信息。例如,智能体A的目标是解析来自智能体B的信息源,从而有效地、甚至完全预测智能体B的未来行动,从而采取合适的行动赢得游戏。然而,由于智能体A不能直接入侵智能体B的思维模式(获得上帝视角),因此只能在智能体A内部构建智能体B的模型。
但是,在智能体A内所构建的智能体B的源信息SrcB2,本质上是对SrcB的近似,在学习过程中能够改进。一种简化视角是将SrcB到SrcB2的编码过程,以及EncB_Ext2中的编码过程等效为一个信息编码过程,从而形式化为一个随时间演化的编码器。此外,FA和FB的反馈设计可以是完全互易的,但是非互易的设计不代表一定不能获得最优译码性能。因此,AlphaZero中的迭代译码器的结构可以等效于标准的Turbo迭代译码结构(3)。
四、学习过程的定量分析
在深入研究定量分析之前,我们给出以下观点。尽管自对弈智能体在减少彼此的不确定性方面正在竞争,但为了在外部信道上联合译码信息,它们是协同工作的,并且旨在达到信道容量。这里,我们来看看AlphaZero学习过程中使用的Elo度量,其中e(·)表示Elo评级,更高的评级意味着更高的获胜概率,而e(A)或e(B)可能没有上界。
Pr{A defeats B} = 1 / ( 1 + 10 ^ (C_elo*(e(B) - e(A))).
只要对弈的两个智能体能力相当,使得e(A) = e(B),AlphaZero中的两个智能体依然具有相等的获胜或失败的概率。因此,以Elo为度量的智能没有上界。
因此,我们把观点转换到用香农信息熵来度量学习过程。首先,AlphaZero的智能上限也是自对弈智能体A或B的智能上限。其次,如图3所示,如果由自对弈智能体形成的分量译码器之间交换的外部信息不再增加,则学习过程也停止,因此智能体A或B的智能水平也无法进一步提升了。注意两点:
- 在逼近上述过程中,Elo趋于无穷。
- 外部信息IE(A)和IE(B)未必达到1.0,因为学习过程可能陷入和终止于局部最优。
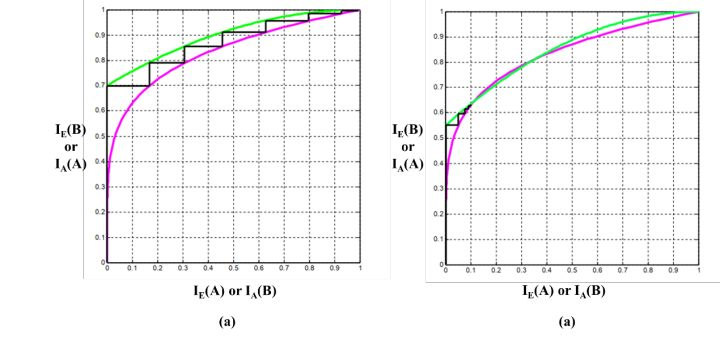
这种外部信息交换过程可以量化分析。在通信学界,为了分析和优化迭代译码,Stephan Ten Brink博士提出了EXtrinsic Information Transfer图(EXIT图),支持定量分析和图形化表示,可以通过EXIT图表中的外信息曲线来区分学习过程是否达到全局最优,或者陷入局部最优。
图4中提供了两个示例。关于IE(A)和IE(B)曲线的案例研究的进一步结果将公布在论文的发表版本。
五、结论与启示
本文将智能体与环境的相互作用建模为外部通信信道和内部通信通道之间的信息流动,而智能体的智能上限可由香农的信道容量给出。本文还讨论了能够逼近智能容量的智能体设计,重点分析了AlphaZero中蕴含的迭代译码架构。据此,EXIT图可以作为预测智能体学习性能的定量分析工具。在(3)中将更详细地讨论关于智能-通信统一模型,这里简要地将AlphaZero所提供的借鉴总结如下:
- 智能体的学习本质是为了最大限度地还原外部通信信道(环境)所传递的信息,提升自身的智能熵,因此其获得的智能熵由外部信道的信道容量所限定。以AlphaZero为例,其外部信道是静态的围棋棋盘,其信道容量不超过log2(361!)。
- 智能体的自对弈(对抗学习)过程的本质是迭代译码,从而逼近给定环境和任务条件下的智能容量,或者等效而言,在其内部构建无损的信道模型。以AlphaZero为例,两个智能体通过构建和更新内部信道模型(环境模型),来实现对外部信道(环境)的学习和适应。通过学习和演化,智能体的内部信道模型(环境模型)可能无限逼近外部信道模型(环境)。例如,在AlphaZero中,内部信道(环境模型)的终极目标是重构所有361!种可能状态。
- 从理论角度进一步审视上述观点,我们可以在围棋对弈中定义终极智能。终极围棋智能能够达到特定的围棋棋盘环境下的智能上限。而如果两个终极围棋智能进行对弈,他们彼此都有完全充分的信息。在这种情况下,任何一方获胜的概率仍为50%,因此等效于量子叠加态,其不确定性处于最高。在两个终极智能的任何一方作出第一次移动后,不确定度将立即降低到0,即测量导致了该量子叠加态的坍缩。
- 借鉴AlphaZero在棋类游戏的突破,其设计思想中的迭代译码或学习原理可能应用到其他领域的智能体设计。例如内部信道可以通过诸如深层神经网络之类的非线性组件来构建,从而近似大容量的外部信道(环境模型)。因此,如果遵循独立编码和迭代译码思想,来构建逼近智能容量的学习系统,与现有技术中普遍采用的单分量译码器相比,可能带来学习性能上的突破。
- EXIT图可以作为量化分析智能体学习过程的有力工具,但是要解决动态开放环境时互信息量的评估问题。因为一般而言,智能体所处的环境比AlphaZero的静态封闭棋盘复杂得多。
六、参考文献
1. Silver, D. et al., A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 362, 1140 – 1144 (2018).
2. C. E. 香农, A mathematical theory of communication. Bell Labs Technical Journal 27.4, 379-423 (1948).
3. B. Zhang et al., An Unified Intelligence-Communication Model for Multi-Agent System Part-I: Overview. arXiv preprint arXiv:1811.09920 (2018).
4. C. Berrou, A. Glavieux, P. Thitimajshima. Near 香农 limit error-correcting coding and decoding. IEEE International Conference on Communications. (1993).
5. S. T. Brink, Convergence behavior of iteratively decoded parallel concatenated codes. IEEE Trans Commun 49.10, 1727-1737 (2001).
