

概括机器学习\深度学习中一些常用的优化算法梯度下降法、动量法momentum、Adagrad、RMSProp、Adadelta、Adam,介绍不同算法之间的关联和优缺点,后续会继续分享其他的算法,感兴趣的可以关注一下。
大多数机器学习问题最终都会涉及一个最优化问题,只是有的是基于最大化后验概率,例如贝叶斯算法,有的是最小化类内距离,例如k-means,而有的是根据预测值和真实值构建一个损失函数,用优化算法来最优化这个损失函数达到学习模型参数的目的。
优化算法有很多种,如果按梯度的类型进行分类,可以分为有梯度优化算法和无梯度优化算法,有梯度优化算法主要有梯度下降法、动量法momentum、Adagrad、RMSProp、Adadelta、Adam等,无梯度优化算法也有很多,像粒子群优化算法、蚁群算法群体智能优化算法,也有贝叶斯优化、ES、SMAC这一类的黑盒优化算法,这篇文章主要介绍一下有梯度优化算法。
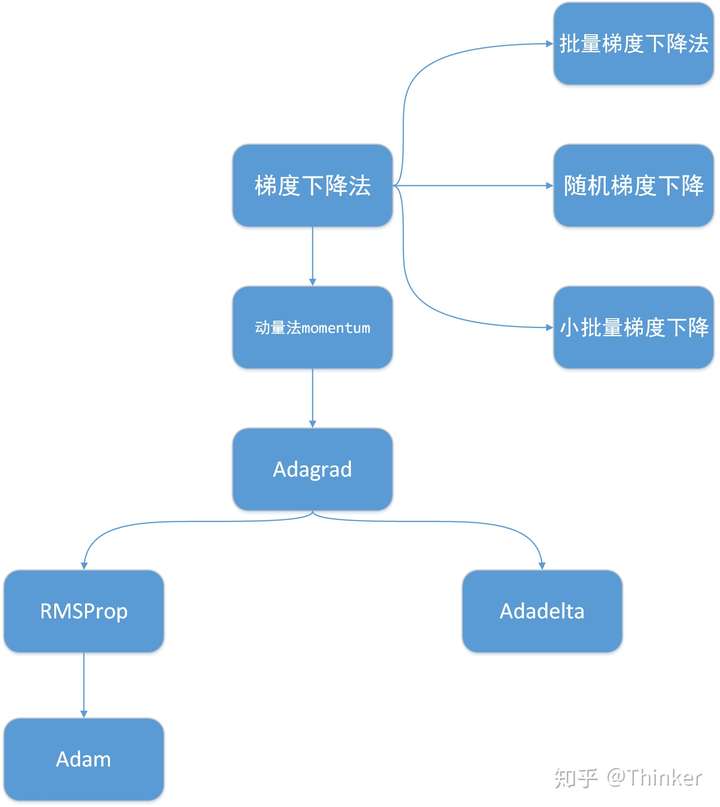
优化算法之间的关系
首先看一下下面的流程图,机器学习中常用的一个有梯度优化算法之间的关系:
梯度下降法
梯度下降法主要分为三种,
- 梯度下降法
梯度下降使用整个训练数据集来计算梯度,因此它有时也被称为批量梯度下降
下面就以均方误差讲解一下,假设损失函数如下:
其中 是预测值,
是真实值,那么要最小化上面损失
,需要对每个参数
运用梯度下降法:
其中 是损失函数对参数
的偏导数、
是学习率,也是每一步更新的步长。
- 随机梯度下降法
在机器学习\深度学习中,目标函数的损失函数通常取各个样本损失函数的平均,那么假设目标函数为:
其中 是第
个样本的目标函数,那么目标函数在在
处的梯度为:
如果使用梯度下降法(批量梯度下降法),那么每次迭代过程中都要对 个样本进行求梯度,所以开销非常大,随机梯度下降的思想就是随机采样一个样本
来更新参数,那么计算开销就从
下降到
。
- 小批量梯度下降法
随机梯度下降虽然提高了计算效率,降低了计算开销,但是由于每次迭代只随机选择一个样本,因此随机性比较大,所以下降过程中非常曲折(图片来自《动手学深度学习》),
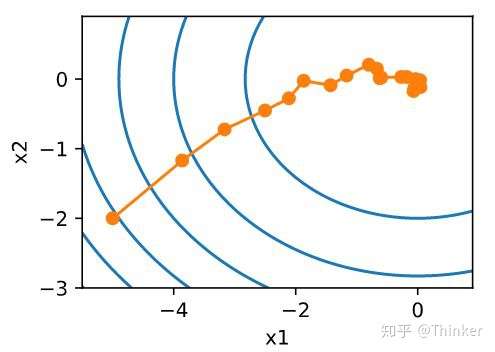
所以,样本的随机性会带来很多噪声,我们可以选取一定数目的样本组成一个小批量样本,然后用这个小批量更新梯度,这样不仅可以减少计算成本,还可以提高算法稳定性。小批量梯度下降的开销为 其中
是批量大小。
该怎么选择?
当数据量不大的时候可以选择批量梯度下降法,当数据量很大时可以选择小批量梯度下降法。
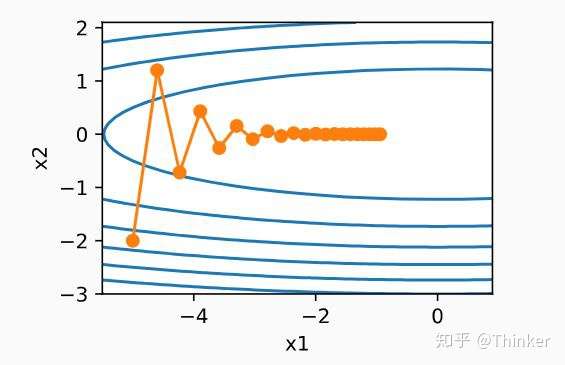
动量法momentum
梯度下降法的缺点是每次更新沿着当前位置的梯度方向进行,更新仅仅取决于所在的位置举个例子,假设一个二维的问题, ,目标函数在 某一点处
方向的梯度要远小于
,那么在
方向更新的复读就会很快,震荡就很严重,降低学习率
可以减小
方向的幅度,但是整体的更新速度也就随着变慢了(图片来源于《动手学深度学习》)。
以 来代表小批量的梯度,那么小批量梯度下降法的为:
动量法在梯度下降法的基础上结合指数加权平均的思想加入一个动量变量 来控制不同方向的梯度,使得各个方向的梯度移动一致,
也就是把小批量梯度下降法中的 变成
,其中
。
Adagrad
前面所介绍的方法都是针对梯度进行改进,而保持一个固定的学习率,例如动量法是通过指数加权平均使得各个方向的梯度尽可能的保持一致,减少梯度在各个方向的发散,而Adagrad算法是根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。
Adagrad在原来的基础上加入了一个梯度的累加变量 ,
其中 是按元素乘积,接下来对学习率根据累加梯度进行调整,
其中 是一个很小的数字,为了维持数值的稳定性。
可以看出Adagrad与小批量梯度下降法的不同之处在于把原来的固定学习率 改为根据累加变量自适应修改的学习率。
RMSProp
Adagrad算法在原来的基础上加上了累加变量 ,
作为自适应调节学习率的参数会逐渐增大,因此会导致学习率逐渐减小或不变,这会导致一种现象,前期学习率下降非常快,但是如果在学习率下降到很小的时候依然没有找到一个比较好的解时,到后期会非常缓慢,甚至找不到一个有用的解,RMSProp在Adagrad的基础上做了一些修改。
RMSProp使用了和动量法类似的思想,对梯度和累加变量利用指数加权平均,
和 Adagrad 一样,RMSProp 将目标函数自变量中每个元素的学习率通过按元素运算重新调整,然后更新自变量,
Adadelta
Adadelta和RMSProp一样,是针对Adagrad后期有可能较难找到有用解的问题进行改进,和RMSProp不同的是,Adadelta没有学习率这个参数。
和RMSProp相同点是,Adadelta也维护了一个累加变量 ,
和RMSProp不同的是,Adadelta还维护了一个变量 ,
梯度更新公式就变成了:
现在回过头看一下,可以发现,Adadelta和RMSProp的不同之处就是把学习率 修改为
。
Adam
这个算法在深度学习中用的比较多,Adam是在RMSProp的基础上进行改进的,该算法与RMSProp不同的是,Adam不仅对累加状态变量 进行指数加权平均,还对每一个小批量的梯度
进行指数加权平均。
Adam加入了动量变量 ,
状态变量的指数加权平均为,
需要注意的是,当迭代次数 较小时,过去的权值之和会较小,假设时间步
,
,那么
,为了消除这个影响Adam算法采用对变量
,
进行修正,
更新公式为:
结语:本人也是一个学习者,本文主要参考李沐的《动手学深度学习》,概括性的总结了一下,文末附上课程链接,如果想详细了解的可以看一下。后期我会定期分享一些机器学习、优化算法、计算机视觉、强化学习等方面的知识,也会分享一些开发中的总结和经验,如果感兴趣的可以关注一下,学习。zh.gluon.ai/chapter_int…
