

这篇笔记主要介绍梯度下降法,梯度下降不是机器学习专属的算法,它是一种基于搜索的最优化方法,也就是通过不断的搜索然后找到损失函数的最小值。像上篇笔记中使用正规方程解实现多元线性回归,基于
X
b
θ" role="presentation">这个模型我们可以推导出
θ" role="presentation">
的数学解,但是很多模型是推导不出数学解的,所以就需要梯度下降法来搜索出最优解。
梯度下降法概念
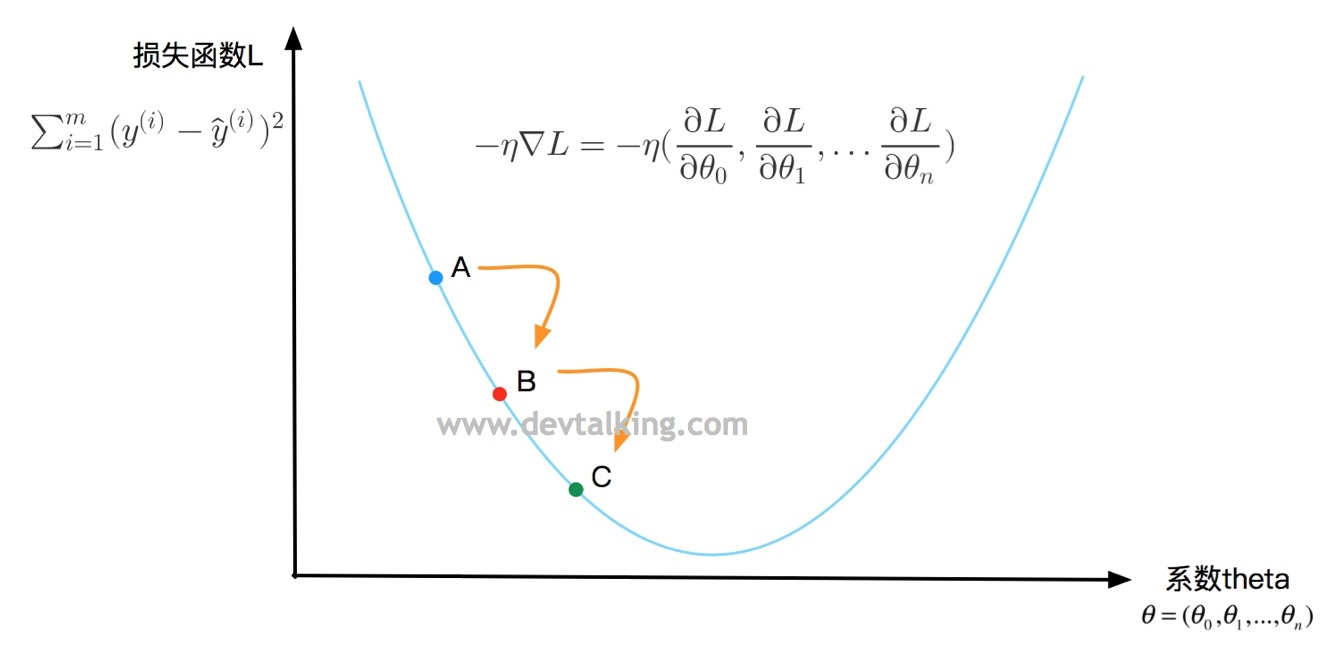
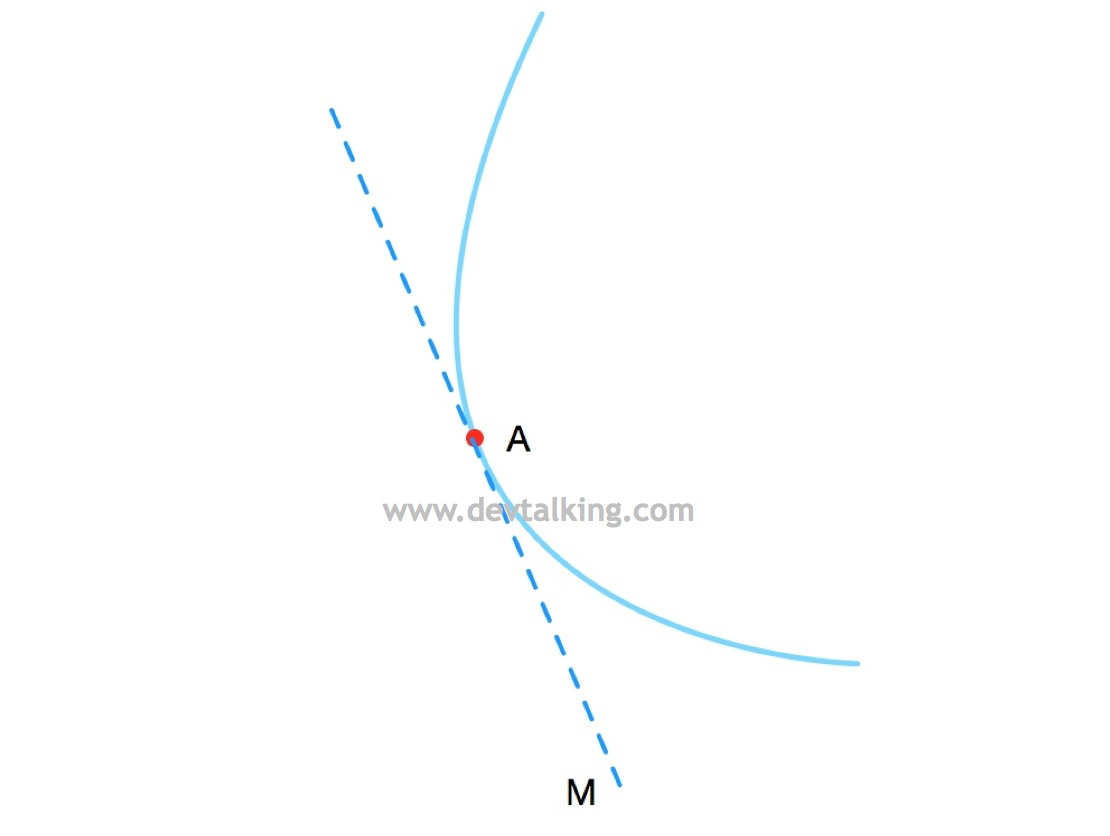
我们来看看在二维坐标里的一个曲线方程:
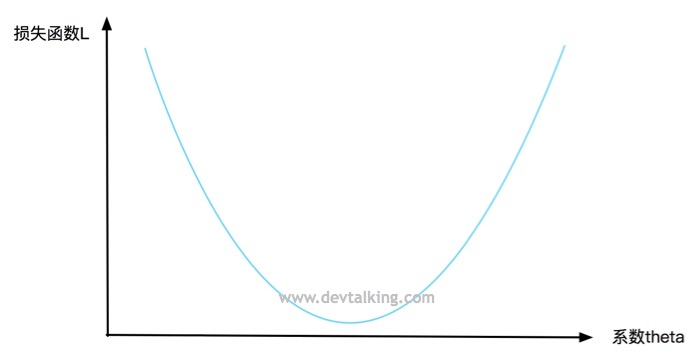
纵坐标表示损失函数L的值,横坐标表示系数
θ" role="presentation">。每一个
θ" role="presentation">
的值都会对应一个损失函数L的值,我们希望损失函数收敛,既找到一个
θ" role="presentation">
的值,使损失函数L的值最小。
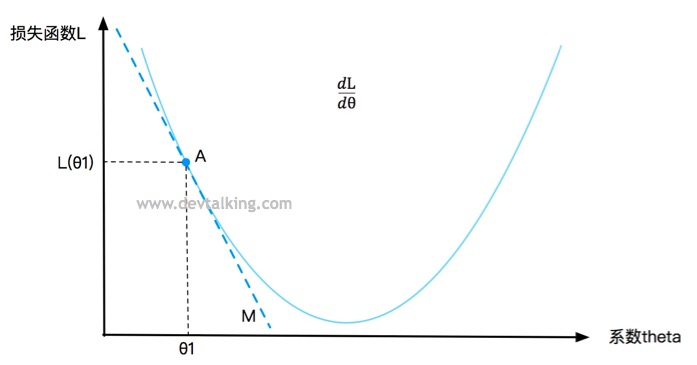
在曲线上定义一点A,对应一个
θ" role="presentation">值,一个损失函数L的值,要判断点A是否是损失函数L的最小值,既求该点的导数,在第一篇笔记中我解释过,点A的导数就是直线M的斜率,直线M是点A的切线,所以导数描述了一个函数在某一点附近的变化率,并且导数大于零时,函数在区间内单调递增,导数小于零时函数在区间内单调递减。所以
d
L
d
θ
" role="presentation">
表示损失函数L增大的变化率,
−
d
L
d
θ
" role="presentation">
表示损失函数L减小的变化率。
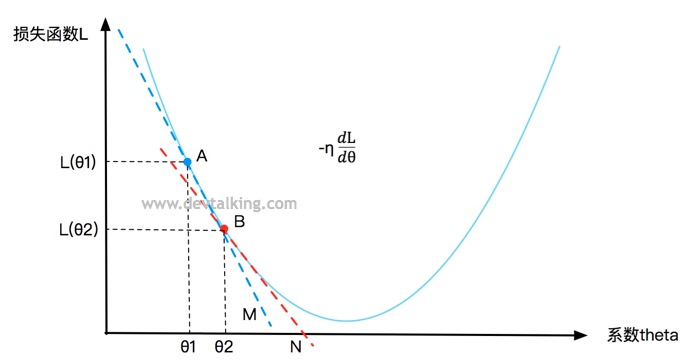
再在曲线上定义一点B,在点A的下方,B点的
θ" role="presentation">值就是A点的
θ" role="presentation">
值加上让损失函数L递减的变化率
−
η
d
L
d
θ
" role="presentation">
,
η" role="presentation">
称为步长,既B点在
−
d
L
d
θ
" role="presentation">
变化率的基础下移动了多少距离,在机器学习中
η" role="presentation">
这个值也称为学习率。
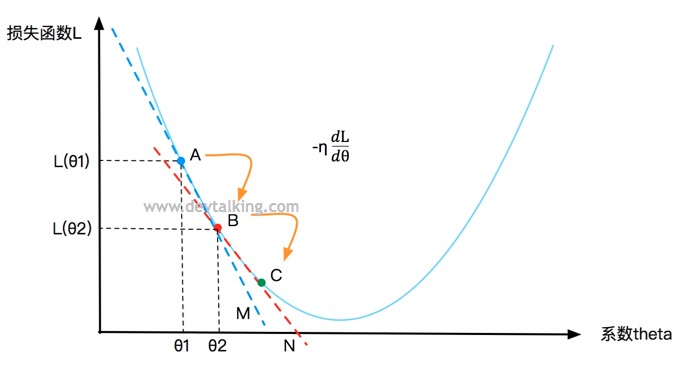
同理还可以再求得点C,然后看是否是损失函数的L的最小值。所以梯度下降法就是基于损失函数在某一点的变化率
−
d
L
d
θ
" role="presentation">,以及寻找下一个点的步长
η" role="presentation">
,不停的找到下一个点,然后判断该点处的损失函数值是否为最小值的过程。
−
η
d
L
d
θ
" role="presentation">
就称为梯度。
在第一篇笔记中将极值的时候提到过,当曲线或者曲面很复杂时,会有多个驻点,既局部极值,所以如果运行一次梯度下降法寻找损失函数极值的话很有可能找到的只是局部极小值点。所以在实际运用中我们需要多次运行算法,随机化初始点,然后进行比较找到真正的全局极小值点,所以初始点的位置是梯度下降法的一个超参数。
不过在线性回归的场景中,我们的损失函数
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
" role="presentation">是有唯一极小值的,所以暂时不需要多次执行算法搜寻全局极值。
梯度下降的步长
步长在梯度下降法中非常重要,这里着重说一下。
-
η" role="presentation">
在机器学习中称为学习率(Learning rate)。
-
η" role="presentation">
-
η" role="presentation">
-
η" role="presentation">
实现梯度下降法
我们在Jupyter Notebook中来看看如何实现梯度下降法:
import numpy as np
import matplotlib.pyplot as plt
# 模拟theta值,及确定一个损失函数
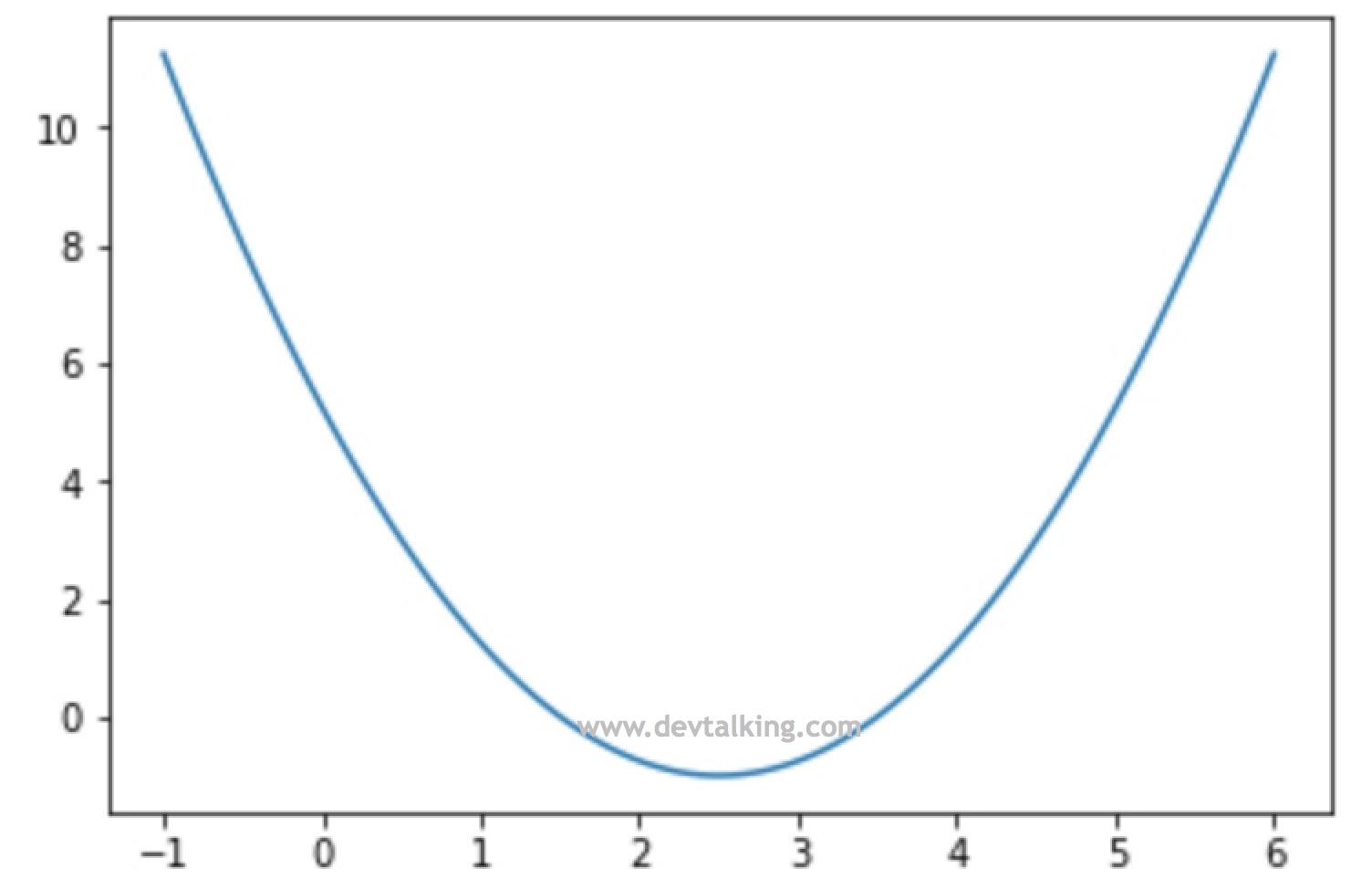
plot_x = np.linspace(-1, 6, 100)
plot_y = (plot_x-2.5)**2-1
# 将该曲线绘制出来
plt.plot(plot_x, plot_y)
plt.show()
下面我们来定义变化率
d
L
d
θ
" role="presentation">和损失函数:
# 变化率
def dL(theta):
# 对(theta-2.5)**2-1 求导,然后返回
return 2*(theta-2.5)
# 损失函数
def L(theta):
return (theta-2.5)**2-1
然后来看看实现梯度下降的过程:
# 步长默认设为0.1
eta = 0.1
# 初始点默认设为0.0
theta = 0.0
# 找到的新的theta值与上一个theta值的差值最小边界
difference = 1e-8
while True:
# 求出梯度,既变化率
gradient = dL(theta)
# 记录上一个theta值
last_theta = theta
# 寻找下一个theta值,既当前的theta值加上乘以步长的使损失函数递减的变化率
theta = theta - eta*gradient
# 当新找到的theta值与上一个theta值之差小于1e-8时,表明此时变化率已经趋于0了,新的theta值可以使损失函数达到极小值
if(abs(L(theta) - L(last_theta)) < difference):
break
print(theta)
print(L(theta))
# 结果
2.499891109642585
-0.99999998814289
得到的
θ" role="presentation">值为2.5,损失函数的极小值为-1,代入方程
(
θ
−
2.5
)
2
−
1" role="presentation">
可验证我们的求解是正确的。
Theta的变化
我们将每次
θ" role="presentation">的值记下来,然后描绘出来,看看是如何变化的:
eta = 0.1
difference = 1e-8
theta = 0.0
theta_history = [theta]
while True:
gradient = dL(theta)
last_theta = theta
theta = theta - eta * gradient
theta_history.append(theta)
if(abs(L(theta) - L(last_theta)) < different):
break
len(theta_history)
# 结果
46
plt.plot(plot_x, L(plot_x))
plt.plot(np.array(theta_history), L(np.array(theta_history)), color='r', marker='+')
plt.show()
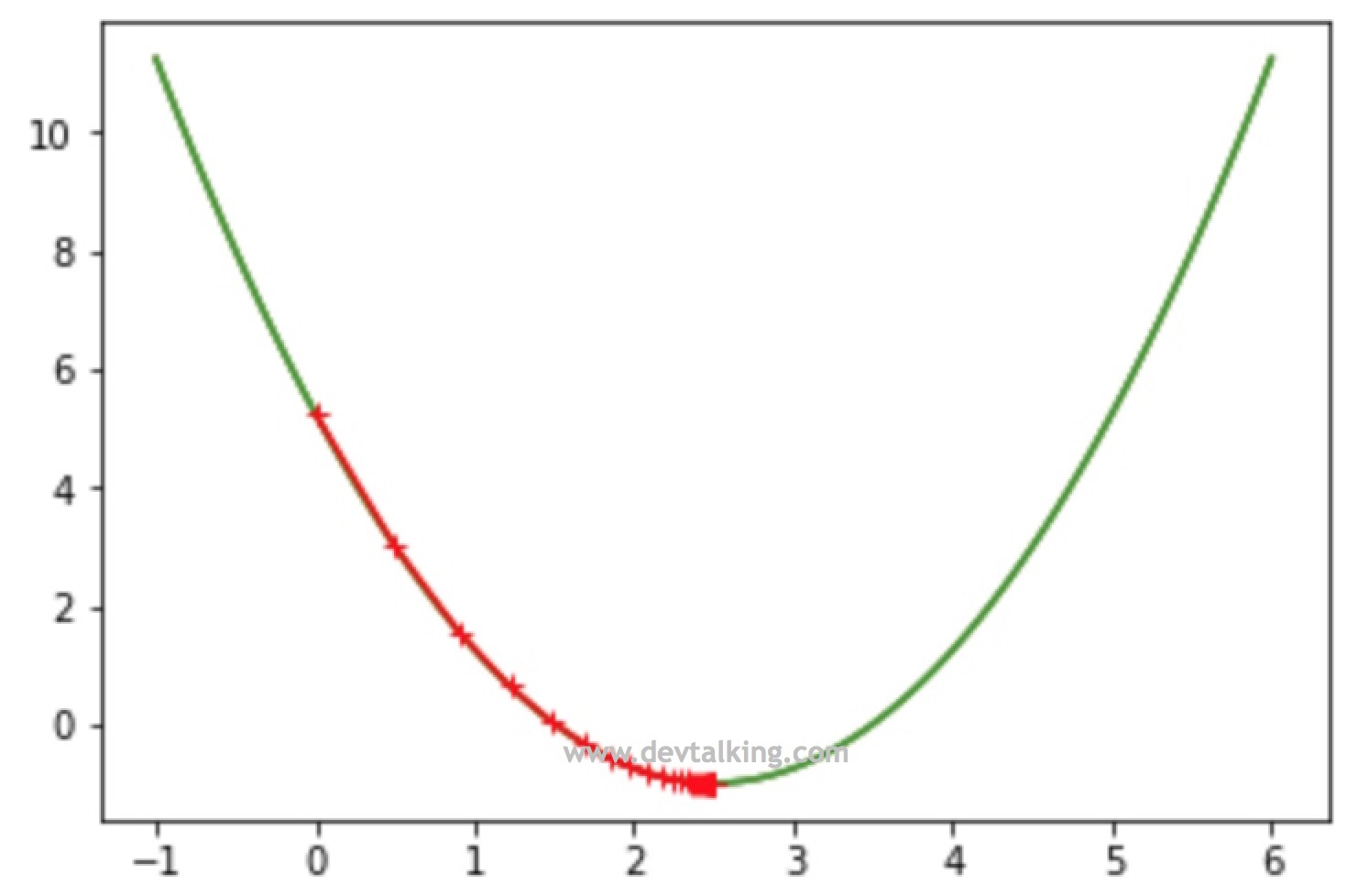
从上面的示例代码中看到,一共经历了45次的查找得到了让函数达到最小值的
θ" role="presentation">。并且看到一开始因为曲线比较陡,所以梯度比较大,两个点之间的间隔比较大,到曲线底部的时候因为曲线开始平缓,梯度逐渐变小,每个点之间的间隔就越来越小。
我们将步长调大一些,看看
θ" role="presentation">的查找轨迹是怎样的:
eta = 0.8
difference = 1e-8
theta = 0.0
theta_history = [theta]
while True:
gradient = dL(theta)
last_theta = theta
theta = theta - eta * gradient
theta_history.append(theta)
if(abs(L(theta) - L(last_theta)) < difference):
break
plt.plot(plot_x, L(plot_x))
plt.plot(np.array(theta_history), L(np.array(theta_history)), color="r", marker="+")
plt.show()
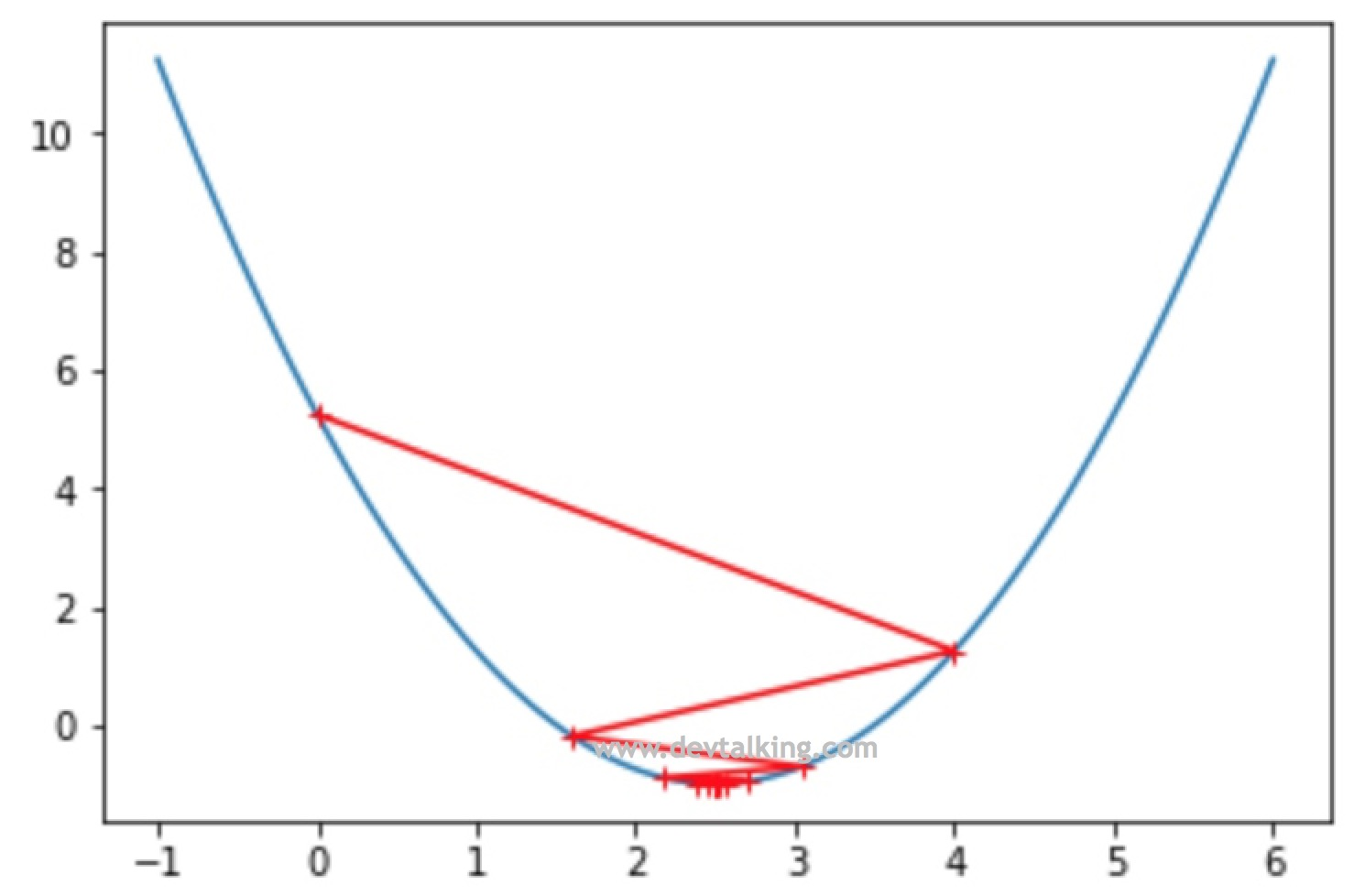
从图中可以看到,第一次查找的时候就越过了极值点,找到了曲线另一侧的点,不过好在损失函数的值还是递减的状态所以最终还是找到了极值点。
我们将步长再调大点,看会发生什么情况:
def L(theta):
try:
return (theta-2.5)**2-1
except:
return float('inf')
eta = 1.1
difference = 1e-8
theta = 0.0
theta_history = [theta]
n_iters = 100
i_iter = 0
while i_iter < n_iters:
gradient = dL(theta)
last_theta = theta
theta = theta - eta * gradient
theta_history.append(theta)
if(abs(L(theta) - L(last_theta)) < difference):
break
i_iter += 1
plt.plot(plot_x, L(plot_x))
plt.plot(np.array(theta_history), L(np.array(theta_history)), color="r", marker="+")
plt.show()
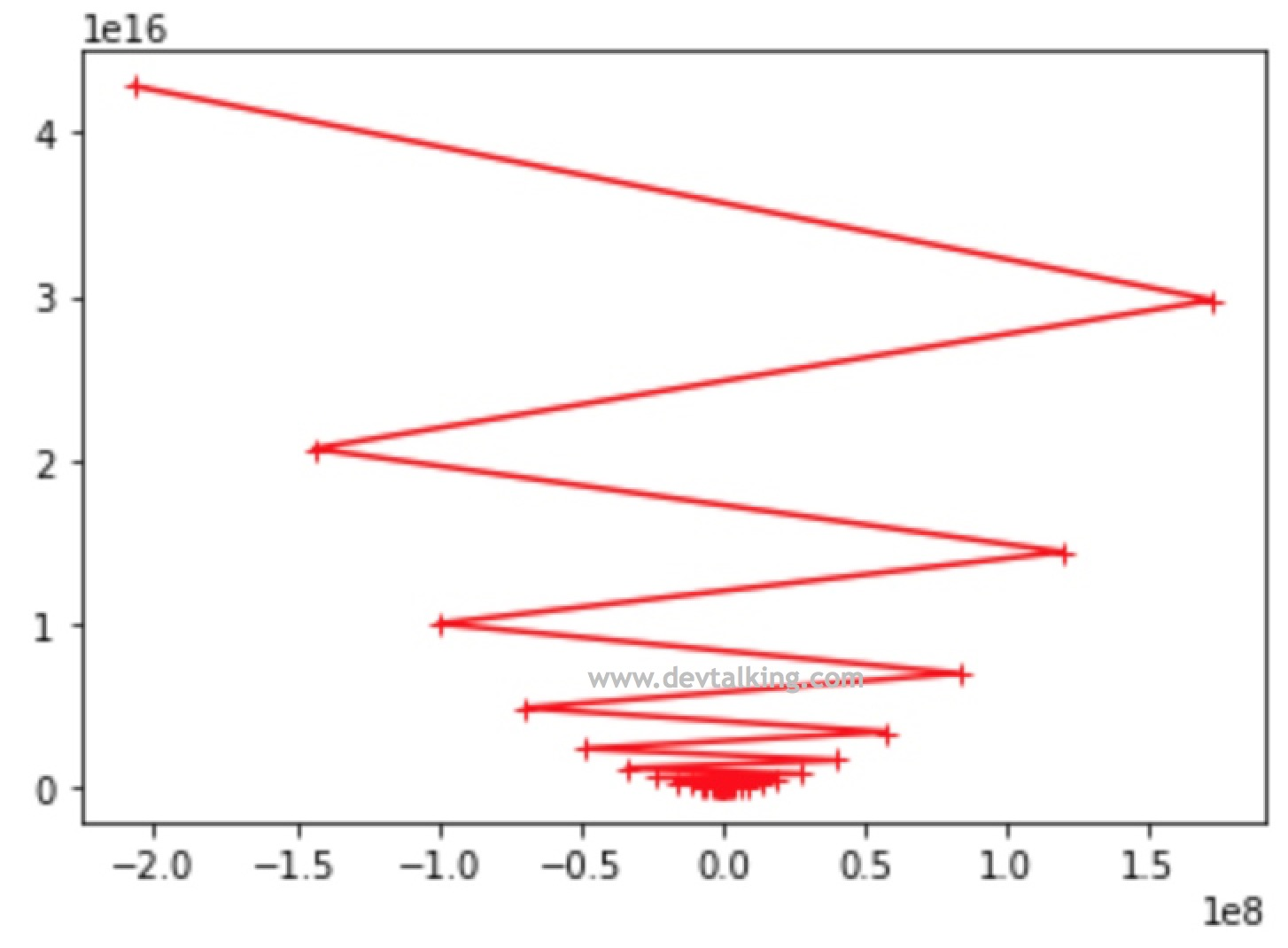
从图中看到每次找到的
θ" role="presentation">会使损失函数越来越大,根本无法找到极小值。所以步长的确定非常重要,不过一般情况下,我们将步长设为0.01是比较保险的做法,但是如果想使算法在各方面达到最优,那么还是需要先对步长这个超参数进行严谨的确定。
求导概念复习
在看如何使用梯度下降解决线性回归问题前,我们先来复习一下求导的知识。
代数函数的求导
-
d
M
d
x
=
0" role="presentation">
-
d
x
n
d
x
=
n
x
n
−
1
" role="presentation">
-
d
|
x
|
d
x
=
x
|
x
|
" role="presentation">
一般求导定则
线性定则
d ( M f ) d x = M d f d x " role="presentation">d(Mf)dx=Mdfdx d ( M f ) d x = M d f d x
d ( f ± g ) d x = d f d x ± d g d x " role="presentation">d(f±g)dx=dfdx±dgdx d ( f ± g ) d x = d f d x ± d g d x
乘法定则
d f g d x = d f d x g + f d g d x " role="presentation">dfgdx=dfdxg+fdgdx d f g d x = d f d x g + f d g d x
除法定则
d f g d x = d f d x g − f d g d x g 2 ( g ≠ 0 )" role="presentation">dfgdx=dfdxg−fdgdxg2 (g≠0) d f g d x = d f d x g − f d g d x g 2 ( g ≠ 0 )
倒数定则
d 1 g d x = − d g d x g 2 ( g ≠ 0 )" role="presentation">d1gdx=−dgdxg2 (g≠0) d 1 g d x = − d g d x g 2 ( g ≠ 0 )
复合函数求导法则
d f [ g ( x ) ] d x = d f ( g ) d g d g d x = f ′ [ g ( x ) ] g ′ ( x )" role="presentation">df[g(x)]dx=df(g)dgdgdx=f′[g(x)]g′(x) d f [ g ( x ) ] d x = d f ( g ) d g d g d x = f ′ [ g ( x ) ] g ′ ( x )
线性回归中使用梯度下降法
上一节通过一维场景解释了梯度下降法,这一节在高维的场景中看看如何使用梯度下降法解决线性回归的问题。
在线性回归的问题中注意一下三个方面:
- 首先损失函数
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
" role="presentation">
是明确的,前面用正规方程解实现的时候已经推导过。
- 其次系数
θ" role="presentation">
不是一维的了,而是多维的,既 θ" role="presentation">
- 最后损失函数不是对一维系数
θ" role="presentation">
,既梯度。
在上一篇笔记中我们推导过
y
^
(
i
)
" role="presentation">的函数:
y ^ ( i ) = θ 0 + θ 1 X 1 ( i ) + θ 2 X 2 ( i ) + … + θ n X n ( i ) " role="presentation">^y(i)=θ0+θ1X(i)1+θ2X(i)2+…+θnX(i)n y ^ ( i ) = θ 0 + θ 1 X 1 ( i ) + θ 2 X 2 ( i ) + … + θ n X n ( i )
所以代入损失函数后就得:
∑ i = 1 m ( y ( i ) − θ 0 − θ 1 X 1 ( i ) − θ 2 X 2 ( i ) − … − θ n X n ( i ) ) 2 " role="presentation">m∑i=1(y(i)−θ0−θ1X(i)1−θ2X(i)2−…−θnX(i)n)2 ∑ i = 1 m ( y ( i ) − θ 0 − θ 1 X 1 ( i ) − θ 2 X 2 ( i ) − … − θ n X n ( i ) ) 2
在讲正规方程解时我们推导过,上面的函数可以转换为:
∑ i = 1 m ( y ( i ) − X b ( i ) θ ) 2 " role="presentation">m∑i=1(y(i)−X(i)bθ)2 ∑ i = 1 m ( y ( i ) − X b ( i ) θ ) 2
我们的目标就是让上面的函数尽可能的小,根据之前讲过的概念,我们知道损失函数的梯度就是对
θ" role="presentation">向量中的每个
θ" role="presentation">
求导,并且在上篇笔记中我们知道
θ" role="presentation">
向量是一个列向量,根据复合函数求导定则,所以损失函数L的梯度为:
∇ L ( θ ) = [ ∂ L ∂ θ 0 ∂ L ∂ θ 1 ∂ L ∂ θ 2 … ∂ L ∂ θ n ] = [ ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − 1 ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 1 ( i ) ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 2 ( i ) ) … ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X n ( i ) ) ] " role="presentation">∇L(θ)=⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣∂L∂θ0∂L∂θ1∂L∂θ2…∂L∂θn⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦=⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣∑mi=12(y(i)−X(i)bθ)(−1)∑mi=12(y(i)−X(i)bθ)(−X(i)1)∑mi=12(y(i)−X(i)bθ)(−X(i)2)…∑mi=12(y(i)−X(i)bθ)(−X(i)n)⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ ∇ L ( θ ) = [ ∂ L ∂ θ 0 ∂ L ∂ θ 1 ∂ L ∂ θ 2 … ∂ L ∂ θ n ] = [ ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − 1 ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 1 ( i ) ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 2 ( i ) ) … ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X n ( i ) ) ]
将2提到外面,然后将后面的负号移进前面的括号里得:
[ ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − 1 ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 1 ( i ) ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 2 ( i ) ) … ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X n ( i ) ) ] = 2 [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ] " role="presentation">⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣∑mi=12(y(i)−X(i)bθ)(−1)∑mi=12(y(i)−X(i)bθ)(−X(i)1)∑mi=12(y(i)−X(i)bθ)(−X(i)2)…∑mi=12(y(i)−X(i)bθ)(−X(i)n)⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦=2⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣∑mi=1(X(i)bθ−y(i))∑mi=1(X(i)bθ−y(i))X(i)1∑mi=1(X(i)bθ−y(i))X(i)2…∑mi=1(X(i)bθ−y(i))X(i)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ [ ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − 1 ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 1 ( i ) ) ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X 2 ( i ) ) … ∑ i = 1 m 2 ( y ( i ) − X b ( i ) θ ) ( − X n ( i ) ) ] = 2 [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ]
可以发现上面公式中每个元素都经过了m求和,这样带来的问题就是梯度受样本数据数量的影响极大,不过在线性回归的评测标准一节中讲到的均方误差MSE就是为了解决这个问题的,所以我们将损失函数直接转变为MSE:
1 m ∑ i = 1 m ( y ( i ) − X b ( i ) θ ) 2 " role="presentation">1mm∑i=1(y(i)−X(i)bθ)2 1 m ∑ i = 1 m ( y ( i ) − X b ( i ) θ ) 2
那么对MSE求梯度的结果自然也是损失函数求梯度后乘以1/m:
2 m [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ] " role="presentation">2m⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣∑mi=1(X(i)bθ−y(i))∑mi=1(X(i)bθ−y(i))X(i)1∑mi=1(X(i)bθ−y(i))X(i)2…∑mi=1(X(i)bθ−y(i))X(i)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ 2 m [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ]
实现线性回归中的梯度下降法
我们先在Jupyter Notebook中来实现,然后再在PyCharm中进行封装:
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子
np.random.seed(666)
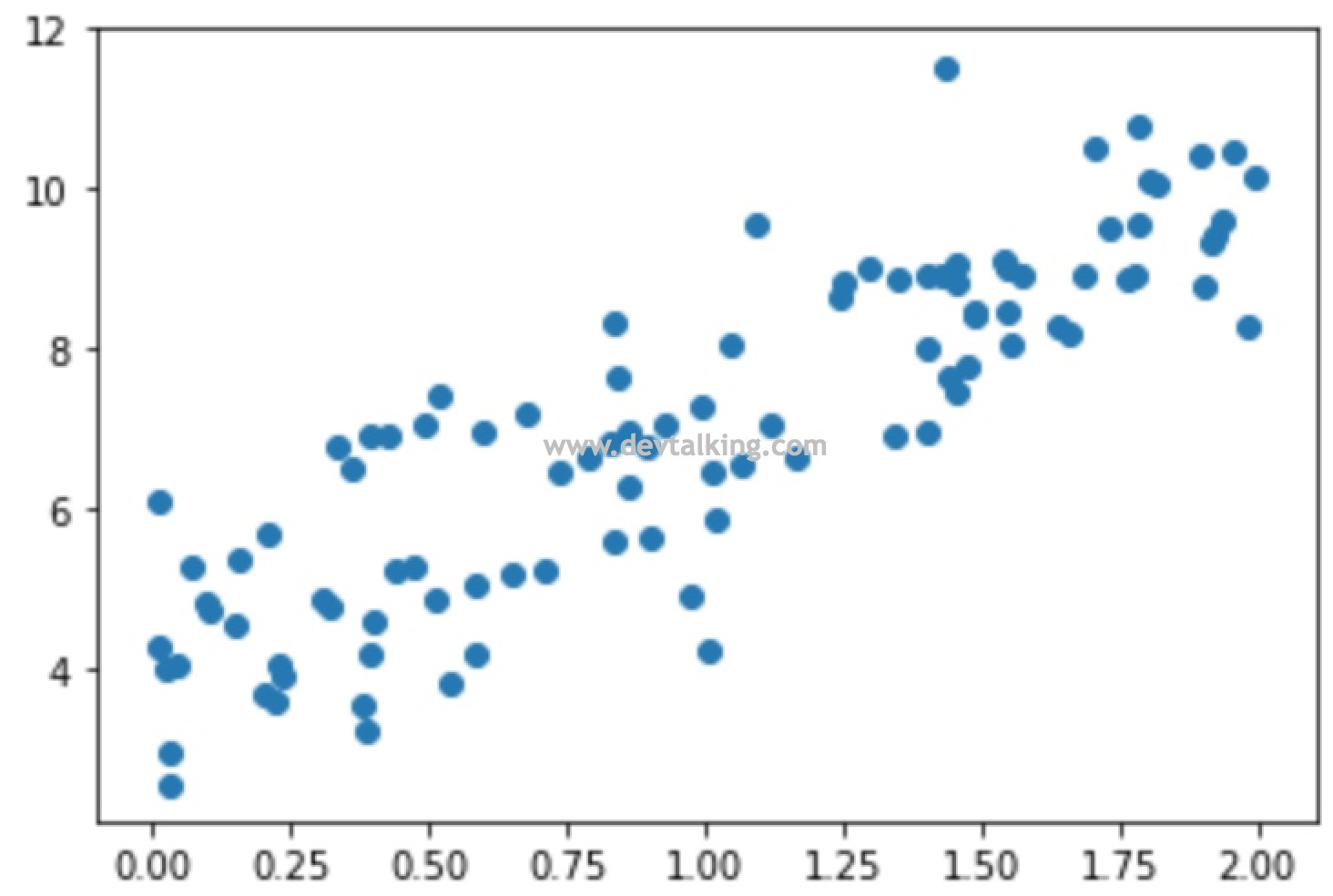
# 随机构建100个数
x = 2 * np.random.random(size=100)
# 拟定一个线性方程,x乘3乘4后再加上随机生成的正态分布数
y = x * 3. + 4. + np.random.normal(size=100)
# 先从100行1列的矩阵开始,既样本数据只有一个特征
X = x.reshape(-1, 1)
plt.scatter(x, y)
plt.show()
# 定义损失函数
def L(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta))**2) / len(X_b)
except:
return float('inf')
# 定义梯度
def dL(theta, X_b, y):
# 开辟空间,大小为theta向量的大小
gradient = np.empty(len(theta))
# 第0元素个特殊处理
gradient[0] = np.sum(X_b.dot(theta) - y)
for i in range(1, len(theta)):
# 矩阵求和可以转换为点乘
gradient[i] = (X_b.dot(theta) - y).dot(X_b[:, i])
return gradient * 2 / len(X_b)
# 梯度下降法
def gradient_descent(X_b, y, initial_theta, eta, n_iters = 1e4, difference = 1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = dL(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if(abs(L(theta, X_b, y) - L(last_theta, X_b, y)) < difference):
break
i_iter += 1
return theta
# 构建X_b
X_b = np.hstack([np.ones((X.shape[0], 1)), X])
# 初始化theta向量为元素全为0的向量
initial_theta = np.zeros(X_b.shape[1])
# 设置步长为0.01
eta = 0.01
theta = gradient_descent(X_b, y, initial_theta, eta)
theta
# 结果
array([ 4.02145786, 3.00706277])
可以看到我们得到的结果,解决为4,斜率为3,和我们拟定的线性方程是一致的。
下面我们在PyCharm中封装梯度下降法。在LinearRegression类中再增加一个fit_gd方法,和fit_normal方法区分开,表明是用梯度下降法进行训练:
# 使用梯度下降法,根据训练数据集X_train,y_train训练LinearRegression模型
def fit_gd(self, X_train, y_train, eta=0.01, n_iters=1e4):
assert X_train.shape[0] == y_train.shape[0], \
"特征数据矩阵的行数要等于样本结果数据的行数"
# 定义损失函数
def L(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta)) ** 2) / len(X_b)
except:
return float('inf')
# 定义梯度
def dL(theta, X_b, y):
# 开辟空间,大小为theta向量的大小
gradient = np.empty(len(theta))
# 第0元素个特殊处理
gradient[0] = np.sum(X_b.dot(theta) - y)
for i in range(1, len(theta)):
# 矩阵求和可以转换为点乘
gradient[i] = (X_b.dot(theta) - y).dot(X_b[:, i])
return gradient * 2 / len(X_b)
# 梯度下降法
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, difference=1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = dL(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(L(theta, X_b, y) - L(last_theta, X_b, y)) < difference):
break
i_iter += 1
return theta
# 构建X_b
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
# 初始化theta向量为元素全为0的向量
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
优化梯度公式
我们先将之前推导出来的梯度公式写出来:
∇ L = 2 m [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ] " role="presentation">∇L=2m⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣∑mi=1(X(i)bθ−y(i))∑mi=1(X(i)bθ−y(i))X(i)1∑mi=1(X(i)bθ−y(i))X(i)2…∑mi=1(X(i)bθ−y(i))X(i)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ ∇ L = 2 m [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ]
将展开来看:
∇ L = 2 m [ ( X b ( 1 ) θ − y ( 1 ) ) + ( X b ( 2 ) θ − y ( 2 ) ) + … + ( X b ( m ) θ − y ( m ) ) ( X b ( 1 ) θ − y ( 1 ) ) X 1 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 1 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 1 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 2 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 2 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 2 ( m ) … ( X b ( 1 ) θ − y ( 1 ) ) X n ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X n ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X n ( m ) ] " role="presentation">∇L=2m⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣(X(1)bθ−y(1))+(X(2)bθ−y(2))+…+(X(m)bθ−y(m))(X(1)bθ−y(1))X(1)1+(X(2)bθ−y(2))X(2)1+…+(X(m)bθ−y(m))X(m)1(X(1)bθ−y(1))X(1)2+(X(2)bθ−y(2))X(2)2+…+(X(m)bθ−y(m))X(m)2…(X(1)bθ−y(1))X(1)n+(X(2)bθ−y(2))X(2)n+…+(X(m)bθ−y(m))X(m)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ ∇ L = 2 m [ ( X b ( 1 ) θ − y ( 1 ) ) + ( X b ( 2 ) θ − y ( 2 ) ) + … + ( X b ( m ) θ − y ( m ) ) ( X b ( 1 ) θ − y ( 1 ) ) X 1 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 1 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 1 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 2 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 2 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 2 ( m ) … ( X b ( 1 ) θ − y ( 1 ) ) X n ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X n ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X n ( m ) ]
将第一行的元素形式统一,每项都乘以
X
0
" role="presentation">,并且
X
0
" role="presentation">
恒等于1:
∇ L = 2 m [ ( X b ( 1 ) θ − y ( 1 ) ) X 0 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 0 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 0 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 1 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 1 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 1 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 2 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 2 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 2 ( m ) … ( X b ( 1 ) θ − y ( 1 ) ) X n ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X n ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X n ( m ) ] " role="presentation">∇L=2m⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣(X(1)bθ−y(1))X(1)0+(X(2)bθ−y(2))X(2)0+…+(X(m)bθ−y(m))X(m)0(X(1)bθ−y(1))X(1)1+(X(2)bθ−y(2))X(2)1+…+(X(m)bθ−y(m))X(m)1(X(1)bθ−y(1))X(1)2+(X(2)bθ−y(2))X(2)2+…+(X(m)bθ−y(m))X(m)2…(X(1)bθ−y(1))X(1)n+(X(2)bθ−y(2))X(2)n+…+(X(m)bθ−y(m))X(m)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ ∇ L = 2 m [ ( X b ( 1 ) θ − y ( 1 ) ) X 0 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 0 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 0 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 1 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 1 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 1 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 2 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 2 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 2 ( m ) … ( X b ( 1 ) θ − y ( 1 ) ) X n ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X n ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X n ( m ) ]
下面我们来两个矩阵,A为一个1行m列的矩阵,B为一个m行n列的矩阵:
A = 2 m [ X b ( 1 ) θ − y ( 1 ) X b ( 2 ) θ − y ( 2 ) … X b ( m ) θ − y ( m ) ] " role="presentation">A=2m[X(1)bθ−y(1)X(2)bθ−y(2)…X(m)bθ−y(m)] A = 2 m [ X b ( 1 ) θ − y ( 1 ) X b ( 2 ) θ − y ( 2 ) … X b ( m ) θ − y ( m ) ]
B = [ X 0 ( 1 ) X 1 ( 1 ) X 2 ( 1 ) … X n ( 1 ) X 0 ( 2 ) X 1 ( 2 ) X 2 ( 2 ) … X n ( 2 ) … X 0 ( m ) X 1 ( m ) X 2 ( m ) … X n ( m ) ] " role="presentation">B=⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣X(1)0X(1)1X(1)2…X(1)nX(2)0X(2)1X(2)2…X(2)n…X(m)0X(m)1X(m)2…X(m)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ B = [ X 0 ( 1 ) X 1 ( 1 ) X 2 ( 1 ) … X n ( 1 ) X 0 ( 2 ) X 1 ( 2 ) X 2 ( 2 ) … X n ( 2 ) … X 0 ( m ) X 1 ( m ) X 2 ( m ) … X n ( m ) ]
在第二篇笔记中我们复习过矩阵的运算,让A矩阵点乘B矩阵会得到一个1行n列的新矩阵:
A ⋅ B = 2 m [ X b ( 1 ) θ − y ( 1 ) X b ( 2 ) θ − y ( 2 ) … X b ( m ) θ − y ( m ) ] ⋅ [ X 0 ( 1 ) X 1 ( 1 ) X 2 ( 1 ) … X n ( 1 ) X 0 ( 2 ) X 1 ( 2 ) X 2 ( 2 ) … X n ( 2 ) … X 0 ( m ) X 1 ( m ) X 2 ( m ) … X n ( m ) ] = [ ( X b ( 1 ) θ − y ( 1 ) ) X 0 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 0 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 0 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 1 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 1 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 1 ( m ) … ( X b ( 1 ) θ − y ( 1 ) ) X n ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X n ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X n ( m ) ] " role="presentation">A⋅B=2m[X(1)bθ−y(1)X(2)bθ−y(2)…X(m)bθ−y(m)]⋅ ⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣X(1)0X(1)1X(1)2…X(1)nX(2)0X(2)1X(2)2…X(2)n…X(m)0X(m)1X(m)2…X(m)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦=⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣(X(1)bθ−y(1))X(1)0+(X(2)bθ−y(2))X(2)0+…+(X(m)bθ−y(m))X(m)0(X(1)bθ−y(1))X(1)1+(X(2)bθ−y(2))X(2)1+…+(X(m)bθ−y(m))X(m)1…(X(1)bθ−y(1))X(1)n+(X(2)bθ−y(2))X(2)n+…+(X(m)bθ−y(m))X(m)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ A ⋅ B = 2 m [ X b ( 1 ) θ − y ( 1 ) X b ( 2 ) θ − y ( 2 ) … X b ( m ) θ − y ( m ) ] ⋅ [ X 0 ( 1 ) X 1 ( 1 ) X 2 ( 1 ) … X n ( 1 ) X 0 ( 2 ) X 1 ( 2 ) X 2 ( 2 ) … X n ( 2 ) … X 0 ( m ) X 1 ( m ) X 2 ( m ) … X n ( m ) ] = [ ( X b ( 1 ) θ − y ( 1 ) ) X 0 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 0 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 0 ( m ) ( X b ( 1 ) θ − y ( 1 ) ) X 1 ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X 1 ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X 1 ( m ) … ( X b ( 1 ) θ − y ( 1 ) ) X n ( 1 ) + ( X b ( 2 ) θ − y ( 2 ) ) X n ( 2 ) + … + ( X b ( m ) θ − y ( m ) ) X n ( m ) ]
注意上面
A
⋅
B" role="presentation">的矩阵是1行n列的矩阵,将其转置后就称为了n行1列的矩阵,正是之前展开的梯度
∇
L" role="presentation">
,所以我们的梯度公式可写为:
∇ L = 2 m ( ( X b θ − y ) ⊤ X b ) ⊤ = 2 m X b ⊤ ( X b θ − y )" role="presentation">∇L=2m((Xbθ−y)⊤Xb)⊤=2mX⊤b(Xbθ−y) ∇ L = 2 m ( ( X b θ − y ) ⊤ X b ) ⊤ = 2 m X b ⊤ ( X b θ − y )
如此一来我们就可以修改一下之前封装的梯度的方法了:
# 定义梯度
def dL(theta, X_b, y):
# # 开辟空间,大小为theta向量的大小
# gradient = np.empty(len(theta))
# # 第0元素个特殊处理
# gradient[0] = np.sum(X_b.dot(theta) - y)
#
# for i in range(1, len(theta)):
# # 矩阵求和可以转换为点乘
# gradient[i] = (X_b.dot(theta) - y).dot(X_b[:, i])
return X_b.T.dot(X_b.dot(theta) - y) * 2 / len(X_b)
此时就可以用一行代码取代之前的for循环来实现梯度了。
用真实数据测试梯度下降法
我们用Scikit Learn提供的波士顿房价来测试一下梯度下降法:
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
# 取前10行数据观察一下
X[10:]
# 结果
Out[17]:
array([[ 2.24890000e-01, 1.25000000e+01, 7.87000000e+00, ...,
1.52000000e+01, 3.92520000e+02, 2.04500000e+01],
[ 1.17470000e-01, 1.25000000e+01, 7.87000000e+00, ...,
1.52000000e+01, 3.96900000e+02, 1.32700000e+01],
[ 9.37800000e-02, 1.25000000e+01, 7.87000000e+00, ...,
1.52000000e+01, 3.90500000e+02, 1.57100000e+01],
...,
[ 6.07600000e-02, 0.00000000e+00, 1.19300000e+01, ...,
2.10000000e+01, 3.96900000e+02, 5.64000000e+00],
[ 1.09590000e-01, 0.00000000e+00, 1.19300000e+01, ...,
2.10000000e+01, 3.93450000e+02, 6.48000000e+00],
[ 4.74100000e-02, 0.00000000e+00, 1.19300000e+01, ...,
2.10000000e+01, 3.96900000e+02, 7.88000000e+00]])
从前10行的数据中可以看出来,数据之间的差距非常大,不同于正规方程法的
θ" role="presentation">有数学解,在梯度下降中会非常影响梯度的值,既影响
θ" role="presentation">
的搜索,从而影响收敛速度和是否能收敛,所以一般在使用梯度下降法前,都需要对数据进行归一化处理,将数据转换到同一尺度下。在第三篇笔记中介绍过数据归一化的方法,Scikit Learn中也提供了数据归一化的方法,我们就使用Scikit Learn中提供的方法对波士顿数据进行归一化:
# 先将样本数据拆分为训练样本数据和测试样本数据
from myML.modelSelection import train_test_split
X_train, y_train, X_test, y_test = train_test_split(X, y, seed=123)
# 使用Scikit Learn提供的数据归一化方法处理训练数据
from sklearn.preprocessing import StandardScaler
standard_scalar = StandardScaler()
standard_scalar.fit(X_train)
X_train_standard = standard_scalar.transform(X_train)
# 再来看看归一化后的数据前10行,和未归一化之前的做一下比较
X_train_standard[10:]
# 结果
array([[-0.3854578 , -0.49494584, -0.70629402, ..., -0.5235474 ,
0.22529916, -1.09634897],
[ 8.34092707, -0.49494584, 1.03476103, ..., 0.80665081,
0.32122168, 1.38375621],
[-0.44033902, 1.83594326, -0.83504431, ..., -0.90360404,
0.45082029, -0.83197228],
...,
[-0.39976896, -0.49494584, 1.58926511, ..., 1.28172161,
0.42018591, 0.2101475 ],
[-0.422702 , -0.49494584, -0.74140773, ..., 0.33158002,
0.4131248 , -0.41372555],
[-0.44280463, 3.05688517, -1.35589775, ..., -0.14349077,
-0.1499176 , -0.02205637]])
可以看到数据都在同一个尺度内了,然后我们用优化后的梯度下降法来训练归一化后的样本数据:
from myML.LinearRegression import LinearRegression
lr = LinearRegression()
lr.fit_gd(X_train_standard, y_train)
lr.intercept_
# 结果
21.629336734693847
lr.coef_
# 结果
array([-0.9525182 , 0.55252408, -0.30736822, -0.03926274, -1.37014814,
2.61387294, -0.82461734, -2.36441751, 2.02340617, -2.17890468,
-1.76883751, 0.7438223 , -2.25694241])
# 在计算score前,需要对X_test数据也进行归一化处理
X_test_standard = standard_scalar.transform(X_test)
lr1.score(X_test_standard, y_test)
# 结果
0.80028998868733348
看到结果与我们之前使用正规方程法得到的结果是一致的。
随机梯度下降法
在实际的运用中,训练数据的量级往往都很大,我们目前实现梯度下降法是需要让每一个样本数据都参与梯度计算的,称为批量梯度下降,所以当样本数据量很大的时候,计算梯度的速度就会很慢,所以这一节我们来看看改进这个情况的随机梯度下降法。
以一个山谷的俯视示意图为例,先来看看批量梯度下降法对
θ" role="presentation">值的查找轨迹:
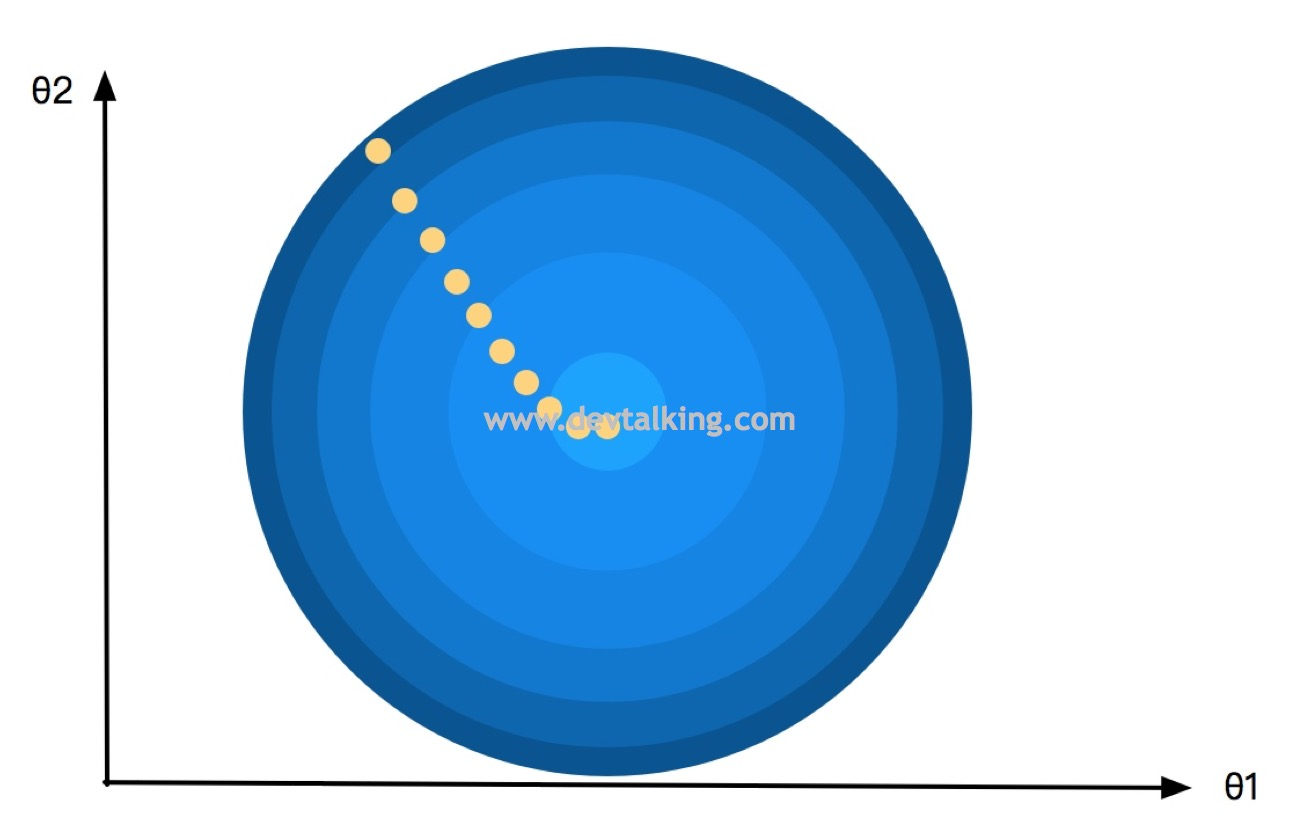
可以看到呈现出的轨迹是平滑下降的,每一个
θ" role="presentation">值都比上一个
θ" role="presentation">
值小,最终找到使损失函数达到极小值的
θ" role="presentation">
。这是因为每一个
θ" role="presentation">
都会对所有样本进行了计算,为了增加拟合效率,对每一个
θ" role="presentation">
,我们不对所有样本进行计算,而是每次只取一个样本进行计算,取多次来找到最终的
θ" role="presentation">
值,这就是随机梯度下降的基本思想。
那么我们再来看看随机梯度下降法的
θ" role="presentation">查找轨迹:
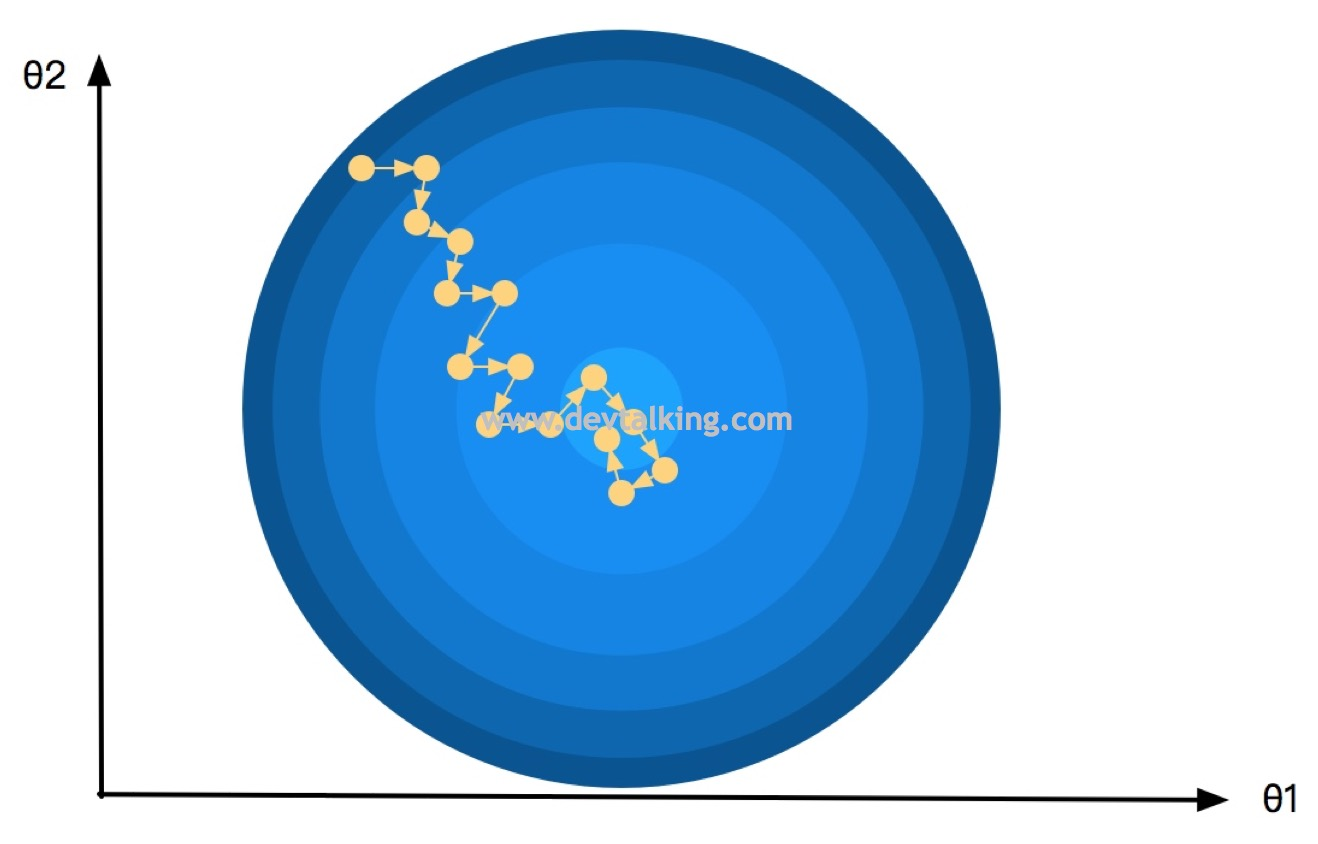
因为每次只随机取一个样本进行计算,所以可以看到随机梯度下降法查找
θ" role="presentation">的轨迹是也是随机的,很多时候搜索下一个
θ" role="presentation">
的路径并不是最短路径,并且下一个
θ" role="presentation">
的损失函数值比上一个
θ" role="presentation">
的损失函数值还要大,但是最终依然会找到使损失函数达到极小值的
θ" role="presentation">
。
我们来看看梯度公式:
2 m [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ] " role="presentation">2m⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣∑mi=1(X(i)bθ−y(i))∑mi=1(X(i)bθ−y(i))X(i)1∑mi=1(X(i)bθ−y(i))X(i)2…∑mi=1(X(i)bθ−y(i))X(i)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ 2 m [ ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ∑ i = 1 m ( X b ( i ) θ − y ( i ) ) X n ( i ) ]
按照随机梯度下降的思路,每次只取一个样本进行计算,也就是i每次只取一个值:
2 [ ( X b ( i ) θ − y ( i ) ) ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ( X b ( i ) θ − y ( i ) ) X n ( i ) ] " role="presentation">2⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣(X(i)bθ−y(i))(X(i)bθ−y(i))X(i)1(X(i)bθ−y(i))X(i)2…(X(i)bθ−y(i))X(i)n⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ 2 [ ( X b ( i ) θ − y ( i ) ) ( X b ( i ) θ − y ( i ) ) X 1 ( i ) ( X b ( i ) θ − y ( i ) ) X 2 ( i ) … ( X b ( i ) θ − y ( i ) ) X n ( i ) ]
向量化后可得:
2 ( X b ( i ) ) ⊤ ( X b ( i ) θ − y ( i ) )" role="presentation">2(X(i)b)⊤(X(i)bθ−y(i)) 2 ( X b ( i ) ) ⊤ ( X b ( i ) θ − y ( i ) )
注意上面这个公式并不是梯度公式,而是搜索
θ" role="presentation">的某一个方向,批量梯度下降是不放过任何一个搜索
θ" role="presentation">
的方向,而随机梯度下降是每次选择一个方向进行搜索。另外需要注意的是随机梯度下降法中的步长(学习率)并不是固定不变的,不然就无法找补随机路径的不足了,所以随机梯度下降法中的步长是根据搜索次数的增加而降低的,也就是逐渐递减的。那么学习率的公式我们首先想到的就是取搜索次数的倒数:
η = 1 i _ i t e r s " role="presentation">η=1i_iters η = 1 i _ i t e r s
但是如果搜索次数很小或者很大的时候都会出现问题,前者会导致学习率下降的幅度过大,而后者会导致学习率下降的幅度过小,所以我们将分母加上一个常数,分子也用一个常数,这样就能保证学习率的递减幅度在一个较为平滑的状态:
η = a i _ i t e r s + b " role="presentation">η=ai_iters+b η = a i _ i t e r s + b
a和b其实就是随机梯度下降法的两个超参数了,不过这里我们不对这两个超参数进行搜索,我们使用最佳实践就好,一般取a为5,b为50。
另外一个关键的超参数是搜索次数,假设取样本数据量的1/3作为搜索次数,因为每次是随机取一个样本数据,那势必会有一部分样本数据取不到,从而不会计算,并且取到的样本数据里也会有重复的数据,这样虽然收敛时间减少了,但是准确率却会打折扣,那么为了训练数据的准确性,我们希望每次搜索到的样本数据不重复,并且能所有的样本数据都希望在某一方向进行计算,所以将搜索次数的概念转变一下,既为随机搜索样本数据,且不重复,且所有样本数据都被搜索到一遍的轮数。这样一来,这个轮数可以很小,一般搜索4轮5轮既可。
实现随机梯度下降法
我们先模拟10万条样本数据,然后用批量梯度下降法训练一次,看看拟合时间:
import numpy as np
# 模拟10万条样本数据
m = 100000
# 随机生成10万个数
x = np.random.random(size=m)
# 转换成10万行1列的矩阵
X = x.reshape(-1, 1)
# 拟定一个线性方程,计算y值,系数为4,截距为3,并且加上一个随机噪音值
y = x * 4 + 3 + np.random.normal(0, 3, size=m)
# 先使用批量梯度下降法
from myML.LinearRegression import LinearRegression
lr = LinearRegression()
%%time
lr.fit_gd(X, y)
# 结果
CPU times: user 6.59 s, sys: 496 ms, total: 7.08 s
Wall time: 5.19 s
# 截距
lr.intercept_
# 结果
2.9982721096748928
# 系数
lr.coef_
# 结果
array([ 3.99485476])
我们看到使用批量梯度下降法计算出的截距和系数和拟定的线性方程中的截距和系数是差不多的,并且拟合时间用了5.19秒。
下面我们直接在PyCharm中封装随机梯度下降的方法,在LinearRegression类中增加fit_sgd方法:
# 使用随机梯度下降法,根据训练数据集X_train,y_train训练LinearRegression模型
def fit_sgd(self, X_train, y_train, n_iters=5, a=5, b=50):
assert X_train.shape[0] == y_train.shape[0], \
"特征数据矩阵的行数要等于样本结果数据的行数"
assert n_iters >= 1, \
"至少要搜索一轮"
# 定义theta查找方向的函数,这里不是全量的X_b矩阵了,而是X_b矩阵中的一行数据,
# 既其中的的一个样本数据,对应的y值也只有一个
def dL_sgd(theta, X_b_i, y_i):
return X_b_i.T.dot(X_b_i.dot(theta) - y_i) * 2
# 实现随机梯度下降法
def sgd(X_b, y, initial_theta, n_iters):
# 定义学习率公式
def eta(iters):
return a / (iters + b)
theta = initial_theta
# 样本数量
m = len(X_b)
# 第一层循环是循环轮数
for i_inter in range(n_iters):
# 在每一轮,随机生成一个乱序数组,个数为m
indexs = np.random.permutation(m)
# 打乱样本数据
X_b_new = X_b[indexs]
y_new = y[indexs]
# 第二层循环便利所有为乱序的样本数据,既保证样本数据能被随机的,全部的计算到
for i in range(m):
# 每次用一个随机样本数据计算theta搜索方向
gradient = dL_sgd(theta, X_b_new[i], y_new[i])
# 计算下一个theta
theta = theta - eta(i_inter * m + i) * gradient
return theta
# 构建X_b
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
# 初始化theta向量为元素全为0的向量
initial_theta = np.zeros(X_b.shape[1])
self._theta = sgd(X_b, y_train, initial_theta, n_iters)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
然后在Jupyter Notebook中使用封装好的随机梯度下降法来训练刚才的数据:
lr1 = LinearRegression()
# 这里我们使用默认的5次搜索轮数,轮数越少,拟合时间越短
%%time
lr1.fit_sgd(X, y)
# 结果
CPU times: user 967 ms, sys: 6.31 ms, total: 973 ms
Wall time: 971 ms
# 截距
lr1.intercept_
# 结果
2.9746308939605761
# 系数
lr1.coef_
# 结果
array([ 3.96594805])
可以看到最终的结果和批量梯度下降法训练出的是差不多的,但是拟合时间只用了971毫秒。
Scikit Learn中的随机梯度下降法
这一节我们用真实的波士顿房价数据,使用Scikit Learn中的随机梯度下降进行训练看看:
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from myML.modelSelection import train_test_split
X_train, y_train, X_test, y_test = train_test_split(X, y, seed=123)
from sklearn.preprocessing import StandardScaler
standard_scalar = StandardScaler()
standard_scalar.fit(X_train)
X_train_standard = standard_scalar.transform(X_train)
X_test_standard = standard_scalar.transform(X_test)
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(n_iter=150)
%time sgd_reg.fit(X_train_standard, y_train)
sgd_reg.score(X_test_standard, y_test)
# 结果
CPU times: user 8.59 ms, sys: 2.26 ms, total: 10.8 ms
Wall time: 8.06 ms
0.80003192122081712
再来看看使用我们自己封装的随机梯度下降训练波士顿房价数据:
from myML.LinearRegression import LinearRegression
lr = LinearRegression()
%%time
lr.fit_gd(X_train_standard, y_train, n_iters=150)
# 结果
CPU times: user 256 ms, sys: 3.43 ms, total: 259 ms
Wall time: 257 ms
lr1.score(X_test_standard, y_test)
# 结果
0.80028998868733348
可以看到在同样的搜索轮数,相同的评分值情况下,Scikit Learn中的随机梯度下降法的收敛时间远远小于我们自己实现的随机梯度下降法,这是因为Scikit Learn中实现的时候使用了大量优化的算法,我们只是使用了最核心的思想进行封装,这点需要大家知晓。
关于梯度的调试
从字面意思就不难看出梯度下降法中梯度的重要性,在线性回归问题中,我们尚且能推导出梯度的公式,但在一些复杂的情况下,推导梯度的公式非常不容易,所以我们推导出的梯度公式是否合理,是否是正确的,就需要有一个方法来验证。这一小节就给大家介绍一个梯度调试的方法。
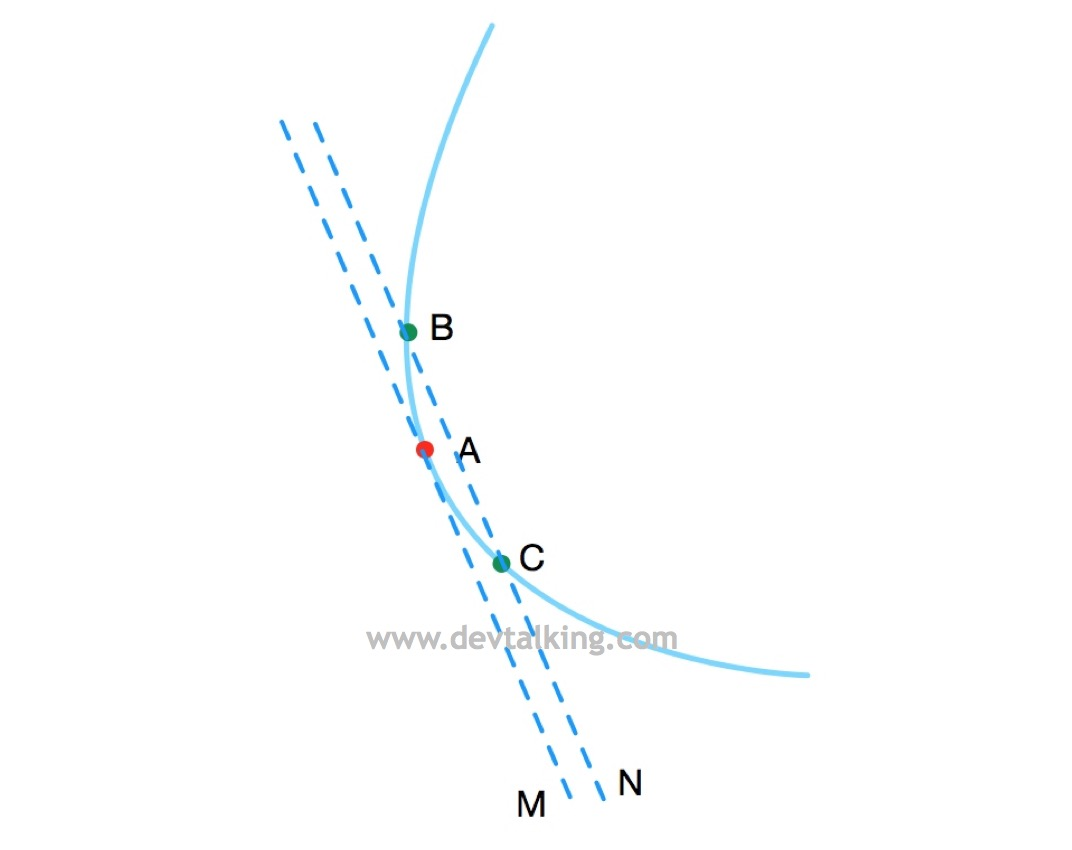
拿一维场景来说,A点的梯度也就是导数是它切线M的斜率。然后我们在直线M的右侧再画出一条平行与直线M的直线N,直线N的斜率与直线M的斜率近乎相等,此时直线N与曲线有两个相交点B和点C,这两个点分别在A点的负方向,也就是下上方,和在A点的正方向,也就是在下方,此时直线M也称为曲线的割线:
在第一篇笔记中讲过直线的斜率定义,既对于两个已知点
(
x
1
,
y
1
)" role="presentation">和
(
x
2
,
y
2
)" role="presentation">
,如果
x
1
" role="presentation">
不等于
x
2
" role="presentation">
,则经过这两点直线的斜率为
(
y
1
−
y
2
)
/
(
x
1
−
x
2
)" role="presentation">
。我们假设点B和点C相距点A为
ϵ" role="presentation">
,所以直线N的斜率为:
L ( θ + ϵ ) − L ( θ − ϵ ) θ + ϵ − ( θ − ϵ ) = L ( θ + ϵ ) − L ( θ − ϵ ) 2 ϵ " role="presentation">L(θ+ϵ)−L(θ−ϵ)θ+ϵ−(θ−ϵ)=L(θ+ϵ)−L(θ−ϵ)2ϵ L ( θ + ϵ ) − L ( θ − ϵ ) θ + ϵ − ( θ − ϵ ) = L ( θ + ϵ ) − L ( θ − ϵ ) 2 ϵ
通过这个公式就可以模拟计算出某一点的导数。对于高维的梯度也是同样的道理。
θ
=
(
θ
0
,
θ
1
,
θ
2
,
…
,
θ
n
)" role="presentation">θ=(θ0,θ1,θ2,…,θn)
θ
=
(
θ
0
,
θ
1
,
θ
2
,
…
,
θ
n
)
∂
L
∂
θ
=
(
∂
L
∂
θ
0
,
∂
L
∂
θ
1
,
∂
L
∂
θ
2
,
…
,
∂
L
∂
θ
n
)" role="presentation">∂L∂θ=(∂L∂θ0,∂L∂θ1,∂L∂θ2,…,∂L∂θn)
∂
L
∂
θ
=
(
∂
L
∂
θ
0
,
∂
L
∂
θ
1
,
∂
L
∂
θ
2
,
…
,
∂
L
∂
θ
n
)
高维情况中,
θ" role="presentation">和梯度如上所示,如果我们要模拟计算
θ
0
" role="presentation">
的梯度,首先得出
θ
0
" role="presentation">
上方和下方的
θ" role="presentation">
:
θ
0
+
=
(
θ
0
+
ϵ
,
θ
1
,
θ
2
,
…
,
θ
n
)" role="presentation">θ+0=(θ0+ϵ,θ1,θ2,…,θn)
θ
0
+
=
(
θ
0
+
ϵ
,
θ
1
,
θ
2
,
…
,
θ
n
)
θ
0
−
=
(
θ
0
−
ϵ
,
θ
1
,
θ
2
,
…
,
θ
n
)" role="presentation">θ−0=(θ0−ϵ,θ1,θ2,…,θn)
θ
0
−
=
(
θ
0
−
ϵ
,
θ
1
,
θ
2
,
…
,
θ
n
)
那么模拟出的
θ
0
" role="presentation">导数为:
∂ L ∂ θ 0 = L ( θ 0 + ) − L ( θ 0 − ) 2 ϵ " role="presentation">∂L∂θ0=L(θ+0)−L(θ−0)2ϵ ∂ L ∂ θ 0 = L ( θ 0 + ) − L ( θ 0 − ) 2 ϵ
以此类推,可以模拟计算出所有
θ" role="presentation">的导数,从而模拟计算出梯度。虽然该方法与损失函数形态无关,但是对每个
θ" role="presentation">
导数的模拟计算都需要将两组
θ" role="presentation">
向量代入损失函数进行计算,时间复杂度还是非常高的,但是有一个优势是可以忽略损失函数形态。所以我们一般用这种方式在一开始投入一些时间算出梯度,因为这个梯度是基于斜率的数学定理计算出的,所以它可以认为是一个合理的梯度,然后将它作为标准来验证通过梯度下降法计算出的梯度的正确性。
实现梯度的调试方法
我们在PyCharm中对我们封装好的梯度下降做一下改动,首先在LinearRegression类中增加一个名为dL_debug()的方法:
def dL_debug(theta, X_b, y, epsilon=0.01):
# 开辟大小与theta向量一致的向量空间
result = np.empty(len(theta))
# 便利theta向量中的每一个theta
for i in range(len(theta)):
# 复制一份theta向量
theta_1 = theta.copy()
# 将第i个theta加上一个距离,既求该theta正方向的theta
theta_1[i] += epsilon
# 在复制一份theta向量
theta_2 = theta.copy()
# 将第i个theta减去同样的距离,既求该theta负方向的theta
theta_2[i] -= epsilon
# 求出这两个点连线的斜率,既模拟该theta的导数
result[i] = (L(theta_1, X_b, y) - L(theta_2, X_b, y)) / (2 * epsilon)
return result
然后对fit_gd()方法增加一个参数is_debug,默认值为False,然后对gradient_descent()进行修改,让其当is_debug为True时走Debug的求梯度的方法,反之走梯度公式的方法:
# 实现批量梯度下降法
def gradient_descent(X_b, y, initial_theta, eta, difference=1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
# 当is_debug为True时走debug的求梯度的方法,反之走梯度公式的方法
if is_debug:
gradient = dL_debug(theta, X_b, y)
else:
gradient = dL(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(L(theta, X_b, y) - L(last_theta, X_b, y)) < difference):
break
i_iter += 1
return theta
下面我们使用波士顿房价的数据验证一下:
import numpy as np
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from myML.modelSelection import train_test_split
X_train, y_train, X_test, y_test = train_test_split(X, y, seed=123)
from sklearn.preprocessing import StandardScaler
standard_scalar = StandardScaler()
standard_scalar.fit(X_train)
X_train_standard = standard_scalar.transform(X_train)
X_test_standard = standard_scalar.transform(X_test)
from myML.LinearRegression import LinearRegression
lr = LinearRegression()
# 使用debug方式训练
%time lr.fit_gd(X_train_standard, y_train, is_debug=True)
# 结果
CPU times: user 2.55 s, sys: 11.4 ms, total: 2.57 s
Wall time: 2.57 s
lr.intercept_
# 结果
21.629336734693936
lr.coef_
# 结果
array([-0.9525182 , 0.55252408, -0.30736822, -0.03926274, -1.37014814,
2.61387294, -0.82461734, -2.36441751, 2.02340617, -2.17890468,
-1.76883751, 0.7438223 , -2.25694241])
# 用梯度公式方式训练
% time lr.fit_gd(X_train_standard, y_train)
# 结果
CPU times: user 241 ms, sys: 4.12 ms, total: 245 ms
Wall time: 242 ms
lr.intercept_
# 结果
21.629336734693936
lr.coef_
# 结果
array([-0.9525182 , 0.55252408, -0.30736822, -0.03926274, -1.37014814,
2.61387294, -0.82461734, -2.36441751, 2.02340617, -2.17890468,
-1.76883751, 0.7438223 , -2.25694241])
可以看到我们使用Debug方式训练数据时用了2.57秒,不过求了准确合理的梯度。然后用梯度公式法训练了数据,耗时242毫米,但结果相同,说明梯度计算的没有问题。
申明:本文为慕课网liuyubobobo老师《Python3入门机器学习 经典算法与应用》课程的学习笔记,未经允许不得转载。
