


微信公众号:深广大数据Club关注可了解更多大数据的相关。问题或建议,请公众号留言;如果你觉得深广大数据Club对你有帮助,欢迎转发朋友圈
本文主要讲述ExecutionGraph的生成过程,ExecutionGraph是在JobManager端生成,由Client端提交的JobGraph转换而来。建议在本篇文章之前先看下之前的两篇文章。
ExecutionGraph的生成过程
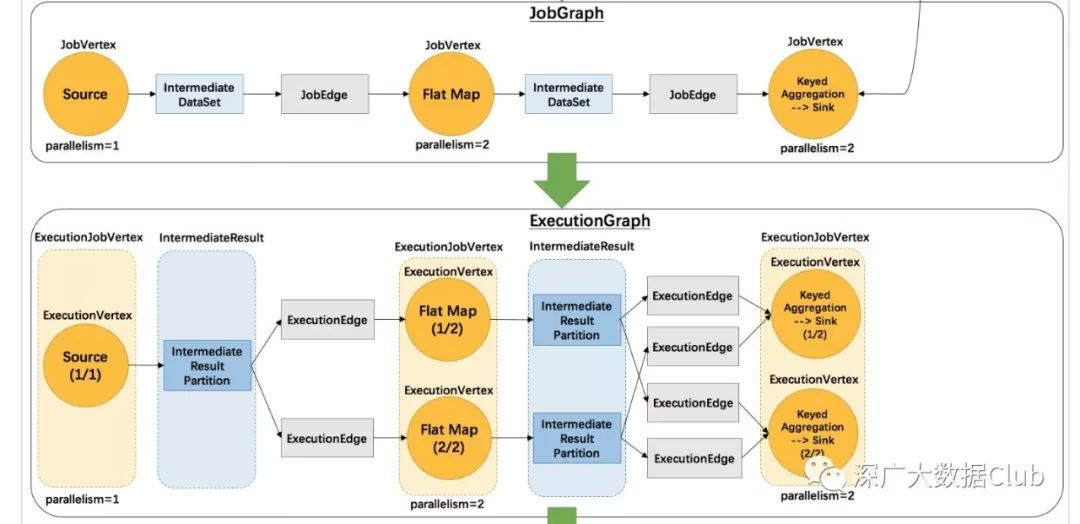
前面我们将了StreamGraph以及JobGraph的生成过程,StreamGraph以及JobGraph都是在Client生成的。现在我们来分析Flink四层Graph的第三层ExecutionGraph。
与之前的JobGraph类似,ExecutionGraph也同样需要JobGraph来生成。不同的是ExecutionGraph是在JobMananger端生成。Client与JobManager进行通讯,将JobGraph等信息发送到JobManager,由其做后续的处理。
此处我们先不关心JobGraph以及JobManager之间是如何通讯的。只关注JobGraph提交到JobManager 后是如何转换成分布式化的ExecutionGraph的。
executionGraph = ExecutionGraphBuilder.buildGraph( executionGraph, jobGraph, flinkConfiguration, futureExecutor, ioExecutor, scheduler, userCodeLoader, checkpointRecoveryFactory, Time.of(timeout.length, timeout.unit), restartStrategy, jobMetrics, numSlots, blobServer, Time.milliseconds(allocationTimeout), log.logger)JobManager的submitJob方法中,调用ExecutionGraphBuilder.buildGraph创建ExecutionGraph.
ExecutionGraphBuilder.buildGraph
方法整体代码较长,此处我们将其进行拆分讲解。
-
检查JobGraph是否为空
checkNotNull(jobGraph, "job graph cannot be null");-
通过JobGraph封装JobInformation
final String jobName = jobGraph.getName(); final JobID jobId = jobGraph.getJobID(); final FailoverStrategy.Factory failoverStrategy = FailoverStrategyLoader.loadFailoverStrategy(jobManagerConfig, log); final JobInformation jobInformation = new JobInformation( jobId, jobName, jobGraph.getSerializedExecutionConfig(), jobGraph.getJobConfiguration(), jobGraph.getUserJarBlobKeys(), jobGraph.getClasspaths());-
创建ExecutionGraph
// create a new execution graph, if none exists so far final ExecutionGraph executionGraph; try { executionGraph = (prior != null) ? prior : new ExecutionGraph( jobInformation, futureExecutor, ioExecutor, rpcTimeout, restartStrategy, failoverStrategy, slotProvider, classLoader, blobWriter, allocationTimeout); } catch (IOException e) { throw new JobException("Could not create the ExecutionGraph.", e); }-
设置基础信息
// set the basic propertiesexecutionGraph.setScheduleMode(jobGraph.getScheduleMode());executionGraph.setQueuedSchedulingAllowed(jobGraph.getAllowQueuedScheduling());try { executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph));}catch (Throwable t) { log.warn("Cannot create JSON plan for job", t); // give the graph an empty plan executionGraph.setJsonPlan("{}");}-
对JobGraph中的JobVerex列表进行排序,并绑定到ExecutionGraph
// topologically sort the job vertices and attach the graph to the existing oneList<JobVertex> sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources();if (log.isDebugEnabled()) { log.debug("Adding {} vertices from job graph {} ({}).", sortedTopology.size(), jobName, jobId);}executionGraph.attachJobGraph(sortedTopology);-
配置checkpoint信息
... //省略checkpoint信息设置executionGraph.enableCheckpointing( chkConfig.getCheckpointInterval(), chkConfig.getCheckpointTimeout(), chkConfig.getMinPauseBetweenCheckpoints(), chkConfig.getMaxConcurrentCheckpoints(), chkConfig.getCheckpointRetentionPolicy(), triggerVertices, ackVertices, confirmVertices, hooks, checkpointIdCounter, completedCheckpoints, rootBackend, checkpointStatsTracker);-
创建ExectionGraph metrics
... //省略metrics信息设置executionGraph.getFailoverStrategy().registerMetrics(metrics);ExecutionGraphBuilder.attachJobGraph
public void attachJobGraph(List<JobVertex> topologiallySorted) throws JobException { ... final ArrayList<ExecutionJobVertex> newExecJobVertices = new ArrayList<>(topologiallySorted.size()); ... for (JobVertex jobVertex : topologiallySorted) { if (jobVertex.isInputVertex() && !jobVertex.isStoppable()) { this.isStoppable = false; } // create the execution job vertex and attach it to the graph ExecutionJobVertex ejv = new ExecutionJobVertex( this, jobVertex, 1, rpcTimeout, globalModVersion, createTimestamp); ejv.connectToPredecessors(this.intermediateResults); ... //省略多行代码。 newExecJobVertices.add(ejv); } terminationFuture = new CompletableFuture<>(); failoverStrategy.notifyNewVertices(newExecJobVertices);}核心内容:
-
生成ExecutionJobVertex列表,用于存储生成的ExecutionJobVertex
-
将传入的排序好的JobVertex列表进行遍历,生成ExecutionJobVertex,并添加到ExecutionJobVertex
-
将ExecutionJobVertex列表传入到failoverStrategy.notifyNewVertices()方法,用于故障容错
扩展:本地模式
其实上述所讲述的JobManager形式是属于集群模式的提交方式。在本地调用过程中,与ExecutionGraphBuilder的交互并不是JobManager,而是JobMaster。但ExecutionGraph的生成过程是一致的。
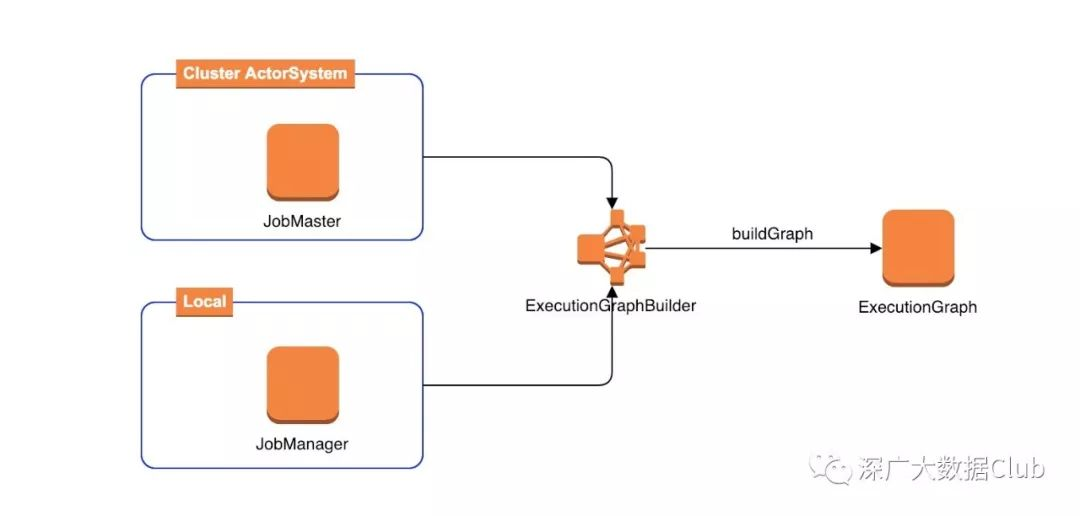
JobMaster
private ExecutionGraph createExecutionGraph(JobManagerJobMetricGroup currentJobManagerJobMetricGroup) throws JobExecutionException, JobException { return ExecutionGraphBuilder.buildGraph( null, jobGraph, jobMasterConfiguration.getConfiguration(), scheduledExecutorService, scheduledExecutorService, slotPool.getSlotProvider(), userCodeLoader, highAvailabilityServices.getCheckpointRecoveryFactory(), rpcTimeout, restartStrategy, currentJobManagerJobMetricGroup, blobServer, jobMasterConfiguration.getSlotRequestTimeout(), log); }具体的调用过程大家可以自己去跟读下代码。
系列相关文章
Flink源码解析 | 从Example出发理解Flink-Flink启动
Flink源码解析 | 从Example出发:读懂本地任务执行流程
Flink源码解析 | 从Example出发:读懂集群任务执行流程
Flink源码解析 | 从Example出发:读懂Flink On Yarn任务执行流程
Flink源码解析 | 从Example出发:读懂start-start-shell.sh任务执行流程
Flink源码解析 | 从Example出发:理解StreamGraph的生成过程
Flink源码解析 | 从Example出发:理解JobGraph的生成过程
关注公众号

