

认识爬虫
众所周知,爬虫是python语言中一种非常重要的工具,能够方便地在互联网中搜集我们想要的内容(一般来说是指html中存在的内容,如:图片、文本等)
本文所涉及的内容仅帮助python初学者更好的理解爬虫。
爬虫到底是什么?
本文以爬取网络小说章节名称+链接为例,我们编写爬虫是为什么?是为了直接把网页上的小说内容自动获取存入本地文档中!
如今爬虫技术已将相当成熟,已经出现Scrapy、PySpider、Beautiful Soup等爬虫框架.
urllib.request
re
以上两个库是我们学习不使用框架的情况下编写爬虫所必须的。
我的第一个爬虫小程序
首先,我们可以将整个思路一一细分。
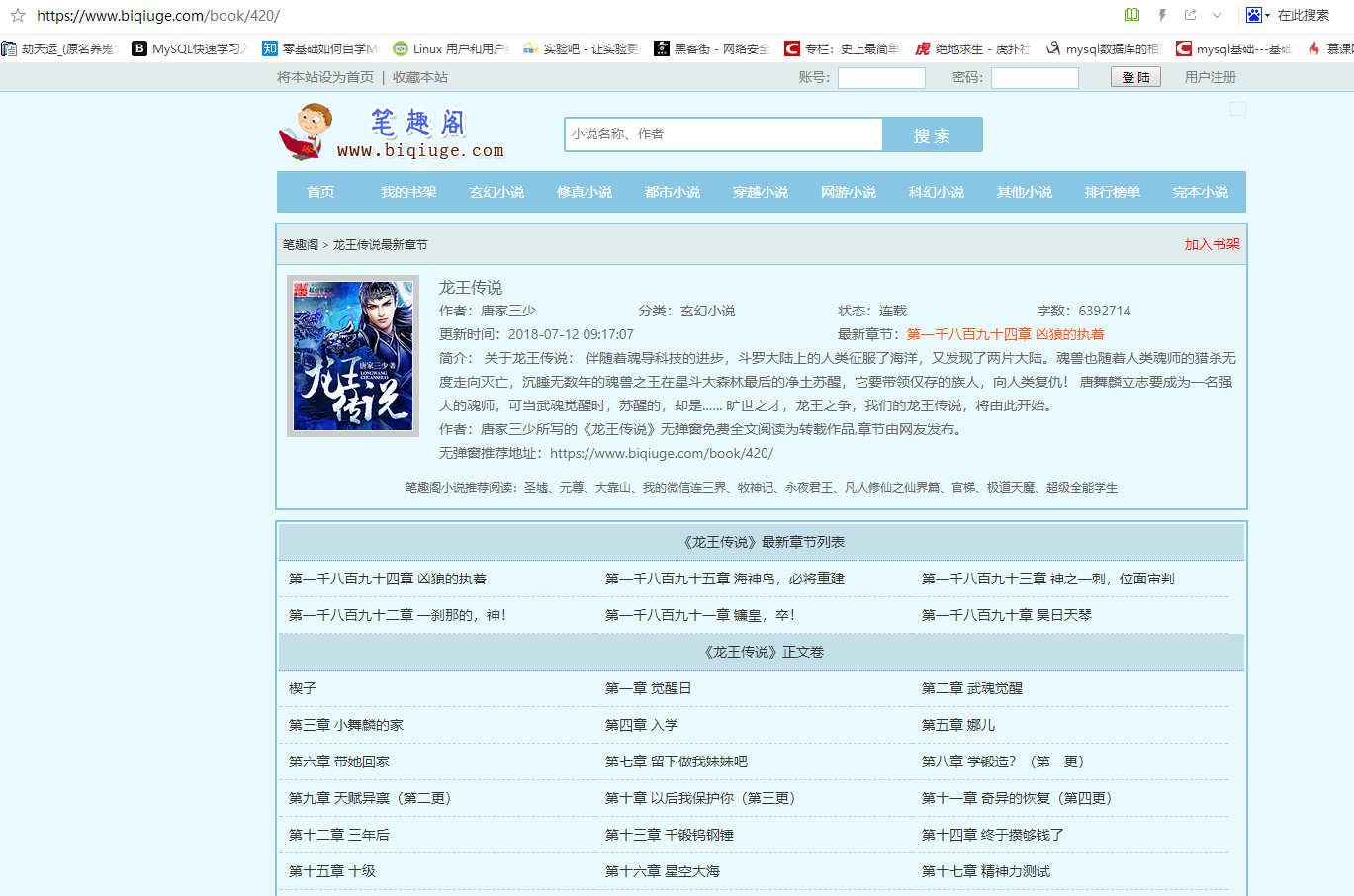
我们以笔趣阁中的《龙王传说》为例,首先在笔趣阁上找到它,并进入小说章节页面.
import urllib.request as req
import re
#获得主html
def getHtml(url1): #我将获取url以及打开url对象的过程写成一个函数
page=req.urlopen(url1)
html1=page.read().decode('gbk') #urlopen获取的内容需要解码后才能显示
return html1
html1=getHtml("https://www.biqiuge.com/book/420/")
print(html1)
代码运行结果:

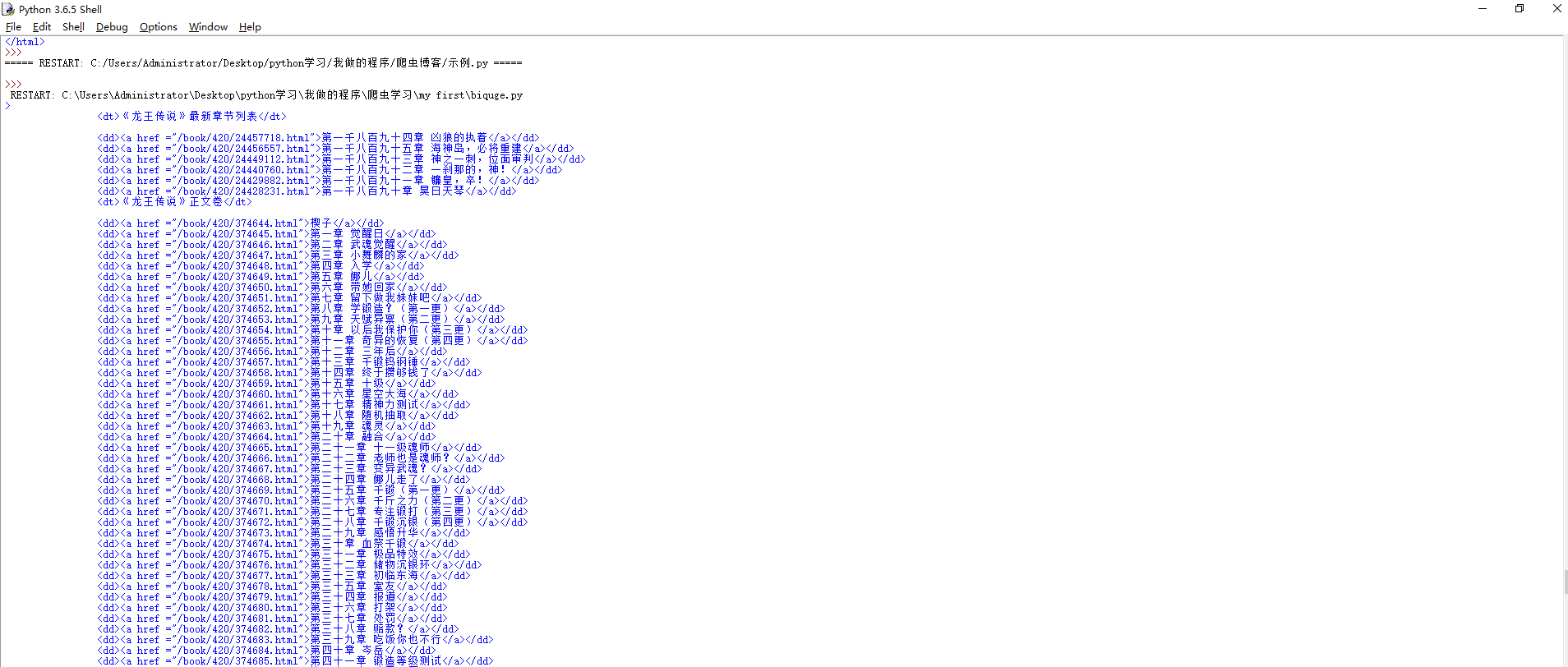
def getZjurls(html): #获取章节url
page=re.findall(r'<dl(.*?)</dl>',html,re.S) #正则表达式,获取<dl到</dl>之间的所有内容
firstpage=page[0] #写进列表
index=firstpage.find('楔子')
代码运行结果:
index=firstpage.find('楔子') #我这里为了使输出结果美观将楔子去掉了,在上一步获取的内容中找到楔子的位置
firstpage=firstpage[index-37:] #保留firstpage中的内容从“楔子”结束的位置开始到firstpage结束
firstpage=firstpage.replace('<dd>','')
firstpage=firstpage.replace('</dd>','')
firstpage=firstpage.replace('<a>','')
firstpage=firstpage.replace('</a>','')
firstpage=firstpage.replace('<','')
firstpage=firstpage.replace(' ','')
firstpage=firstpage.replace('<','')
firstpage=firstpage.replace('>','')
firstpage=firstpage.replace('a','')
firstpage=firstpage.replace('href','')
firstpage=firstpage.replace('=','')
firstpage=firstpage.replace('\t','')
firstpage=firstpage.replace('"','')
代码运行结果:

htmlList=getZjurls(html1)
htmlList=htmlList.split('\n') #按换行符切片保存至列表
for line in htmlList:
print("https://www.biqiuge.com"+line) #列表每行数据,并在开头加上主url循环 输出
代码运行结果如下:
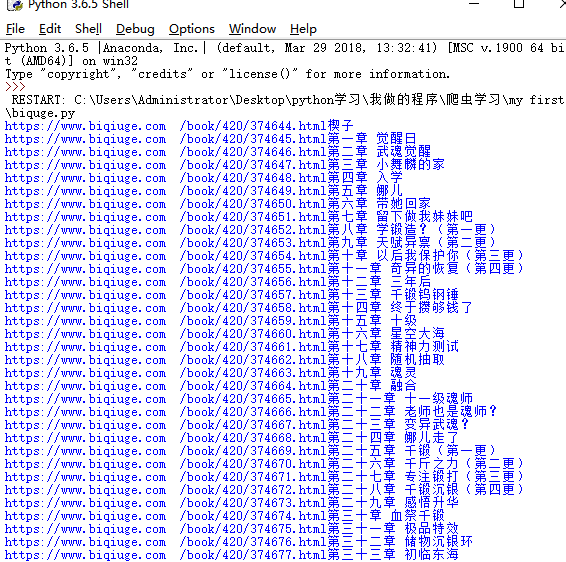
目标达成!
本文只是为了学习爬虫基础知识,并不是为了真正爬取小说内容,希望大家学会之后不要用于商业用途。
