

github地址: github.com/yangjinghit…
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data1 = pd.DataFrame({'X':np.random.randint(1,50,100), 'Y':np.random.randint(1,50, 100)})
data = pd.concat([data1 + 50, data1])
plt.style.use('ggplot')
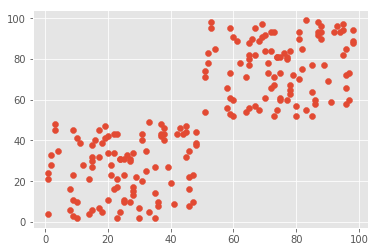
plt.scatter(data['X'], data['Y'])
<matplotlib.collections.PathCollection at 0x11084cf60>
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=2).fit_predict(data)
y_pred
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1], dtype=int32)
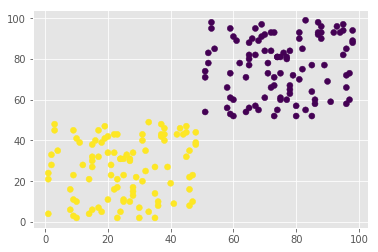
plt.scatter(data.X, data.Y, c=y_pred)
<matplotlib.collections.PathCollection at 0x1a15f51b70>
from sklearn import metrics
metrics.calinski_harabaz_score(data, y_pred)
651.578135407151
y_pred_three = KMeans(n_clusters=3).fit_predict(data)
metrics.calinski_harabaz_score(data, y_pred_three)
440.2030577799353
y_pred_four = KMeans(n_clusters=4).fit_predict(data)
metrics.calinski_harabaz_score(data, y_pred_four)
422.21475785975883
data = pd.read_csv('seeds_dataset.txt', header=None, delim_whitespace=True, names=['x1','x2','x3','x4','x5','x6','x7','y'])
data
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | y | |
|---|---|---|---|---|---|---|---|---|
| 0 | 15.26 | 14.84 | 0.8710 | 5.763 | 3.312 | 2.2210 | 5.220 | 1 |
| 1 | 14.88 | 14.57 | 0.8811 | 5.554 | 3.333 | 1.0180 | 4.956 | 1 |
| 2 | 14.29 | 14.09 | 0.9050 | 5.291 | 3.337 | 2.6990 | 4.825 | 1 |
| 3 | 13.84 | 13.94 | 0.8955 | 5.324 | 3.379 | 2.2590 | 4.805 | 1 |
| 4 | 16.14 | 14.99 | 0.9034 | 5.658 | 3.562 | 1.3550 | 5.175 | 1 |
| 5 | 14.38 | 14.21 | 0.8951 | 5.386 | 3.312 | 2.4620 | 4.956 | 1 |
| 6 | 14.69 | 14.49 | 0.8799 | 5.563 | 3.259 | 3.5860 | 5.219 | 1 |
| 7 | 14.11 | 14.10 | 0.8911 | 5.420 | 3.302 | 2.7000 | 5.000 | 1 |
| 8 | 16.63 | 15.46 | 0.8747 | 6.053 | 3.465 | 2.0400 | 5.877 | 1 |
| 9 | 16.44 | 15.25 | 0.8880 | 5.884 | 3.505 | 1.9690 | 5.533 | 1 |
| 10 | 15.26 | 14.85 | 0.8696 | 5.714 | 3.242 | 4.5430 | 5.314 | 1 |
| 11 | 14.03 | 14.16 | 0.8796 | 5.438 | 3.201 | 1.7170 | 5.001 | 1 |
| 12 | 13.89 | 14.02 | 0.8880 | 5.439 | 3.199 | 3.9860 | 4.738 | 1 |
| 13 | 13.78 | 14.06 | 0.8759 | 5.479 | 3.156 | 3.1360 | 4.872 | 1 |
| 14 | 13.74 | 14.05 | 0.8744 | 5.482 | 3.114 | 2.9320 | 4.825 | 1 |
| 15 | 14.59 | 14.28 | 0.8993 | 5.351 | 3.333 | 4.1850 | 4.781 | 1 |
| 16 | 13.99 | 13.83 | 0.9183 | 5.119 | 3.383 | 5.2340 | 4.781 | 1 |
| 17 | 15.69 | 14.75 | 0.9058 | 5.527 | 3.514 | 1.5990 | 5.046 | 1 |
| 18 | 14.70 | 14.21 | 0.9153 | 5.205 | 3.466 | 1.7670 | 4.649 | 1 |
| 19 | 12.72 | 13.57 | 0.8686 | 5.226 | 3.049 | 4.1020 | 4.914 | 1 |
| 20 | 14.16 | 14.40 | 0.8584 | 5.658 | 3.129 | 3.0720 | 5.176 | 1 |
| 21 | 14.11 | 14.26 | 0.8722 | 5.520 | 3.168 | 2.6880 | 5.219 | 1 |
| 22 | 15.88 | 14.90 | 0.8988 | 5.618 | 3.507 | 0.7651 | 5.091 | 1 |
| 23 | 12.08 | 13.23 | 0.8664 | 5.099 | 2.936 | 1.4150 | 4.961 | 1 |
| 24 | 15.01 | 14.76 | 0.8657 | 5.789 | 3.245 | 1.7910 | 5.001 | 1 |
| 25 | 16.19 | 15.16 | 0.8849 | 5.833 | 3.421 | 0.9030 | 5.307 | 1 |
| 26 | 13.02 | 13.76 | 0.8641 | 5.395 | 3.026 | 3.3730 | 4.825 | 1 |
| 27 | 12.74 | 13.67 | 0.8564 | 5.395 | 2.956 | 2.5040 | 4.869 | 1 |
| 28 | 14.11 | 14.18 | 0.8820 | 5.541 | 3.221 | 2.7540 | 5.038 | 1 |
| 29 | 13.45 | 14.02 | 0.8604 | 5.516 | 3.065 | 3.5310 | 5.097 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 180 | 11.41 | 12.95 | 0.8560 | 5.090 | 2.775 | 4.9570 | 4.825 | 3 |
| 181 | 12.46 | 13.41 | 0.8706 | 5.236 | 3.017 | 4.9870 | 5.147 | 3 |
| 182 | 12.19 | 13.36 | 0.8579 | 5.240 | 2.909 | 4.8570 | 5.158 | 3 |
| 183 | 11.65 | 13.07 | 0.8575 | 5.108 | 2.850 | 5.2090 | 5.135 | 3 |
| 184 | 12.89 | 13.77 | 0.8541 | 5.495 | 3.026 | 6.1850 | 5.316 | 3 |
| 185 | 11.56 | 13.31 | 0.8198 | 5.363 | 2.683 | 4.0620 | 5.182 | 3 |
| 186 | 11.81 | 13.45 | 0.8198 | 5.413 | 2.716 | 4.8980 | 5.352 | 3 |
| 187 | 10.91 | 12.80 | 0.8372 | 5.088 | 2.675 | 4.1790 | 4.956 | 3 |
| 188 | 11.23 | 12.82 | 0.8594 | 5.089 | 2.821 | 7.5240 | 4.957 | 3 |
| 189 | 10.59 | 12.41 | 0.8648 | 4.899 | 2.787 | 4.9750 | 4.794 | 3 |
| 190 | 10.93 | 12.80 | 0.8390 | 5.046 | 2.717 | 5.3980 | 5.045 | 3 |
| 191 | 11.27 | 12.86 | 0.8563 | 5.091 | 2.804 | 3.9850 | 5.001 | 3 |
| 192 | 11.87 | 13.02 | 0.8795 | 5.132 | 2.953 | 3.5970 | 5.132 | 3 |
| 193 | 10.82 | 12.83 | 0.8256 | 5.180 | 2.630 | 4.8530 | 5.089 | 3 |
| 194 | 12.11 | 13.27 | 0.8639 | 5.236 | 2.975 | 4.1320 | 5.012 | 3 |
| 195 | 12.80 | 13.47 | 0.8860 | 5.160 | 3.126 | 4.8730 | 4.914 | 3 |
| 196 | 12.79 | 13.53 | 0.8786 | 5.224 | 3.054 | 5.4830 | 4.958 | 3 |
| 197 | 13.37 | 13.78 | 0.8849 | 5.320 | 3.128 | 4.6700 | 5.091 | 3 |
| 198 | 12.62 | 13.67 | 0.8481 | 5.410 | 2.911 | 3.3060 | 5.231 | 3 |
| 199 | 12.76 | 13.38 | 0.8964 | 5.073 | 3.155 | 2.8280 | 4.830 | 3 |
| 200 | 12.38 | 13.44 | 0.8609 | 5.219 | 2.989 | 5.4720 | 5.045 | 3 |
| 201 | 12.67 | 13.32 | 0.8977 | 4.984 | 3.135 | 2.3000 | 4.745 | 3 |
| 202 | 11.18 | 12.72 | 0.8680 | 5.009 | 2.810 | 4.0510 | 4.828 | 3 |
| 203 | 12.70 | 13.41 | 0.8874 | 5.183 | 3.091 | 8.4560 | 5.000 | 3 |
| 204 | 12.37 | 13.47 | 0.8567 | 5.204 | 2.960 | 3.9190 | 5.001 | 3 |
| 205 | 12.19 | 13.20 | 0.8783 | 5.137 | 2.981 | 3.6310 | 4.870 | 3 |
| 206 | 11.23 | 12.88 | 0.8511 | 5.140 | 2.795 | 4.3250 | 5.003 | 3 |
| 207 | 13.20 | 13.66 | 0.8883 | 5.236 | 3.232 | 8.3150 | 5.056 | 3 |
| 208 | 11.84 | 13.21 | 0.8521 | 5.175 | 2.836 | 3.5980 | 5.044 | 3 |
| 209 | 12.30 | 13.34 | 0.8684 | 5.243 | 2.974 | 5.6370 | 5.063 | 3 |
210 rows × 8 columns
data.columns
Index(['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'y'], dtype='object')
y_pred = KMeans(n_clusters=3).fit_predict(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']])
y_pred
array([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 0, 2, 2,
2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 0, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 2, 2,
2, 2, 2, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1,
2, 2, 2, 2, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)
y_pre = pd.Series(y_pred)
y_pre
0 2
1 2
2 2
3 2
4 2
5 2
6 2
7 2
8 2
9 2
10 2
11 2
12 2
13 2
14 2
15 2
16 0
17 2
18 2
19 0
20 2
21 2
22 2
23 2
24 2
25 2
26 0
27 2
28 2
29 2
..
180 0
181 0
182 0
183 0
184 0
185 0
186 0
187 0
188 0
189 0
190 0
191 0
192 0
193 0
194 0
195 0
196 0
197 0
198 0
199 0
200 0
201 2
202 0
203 0
204 0
205 0
206 0
207 0
208 0
209 0
Length: 210, dtype: int32
y_pre.unique()
array([2, 0, 1])
y_pre = y_pre.map({2:1, 1:2, 0:3})
y_pre
0 1
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 1
11 1
12 1
13 1
14 1
15 1
16 3
17 1
18 1
19 3
20 1
21 1
22 1
23 1
24 1
25 1
26 3
27 1
28 1
29 1
..
180 3
181 3
182 3
183 3
184 3
185 3
186 3
187 3
188 3
189 3
190 3
191 3
192 3
193 3
194 3
195 3
196 3
197 3
198 3
199 3
200 3
201 1
202 3
203 3
204 3
205 3
206 3
207 3
208 3
209 3
Length: 210, dtype: int64
data_p = pd.DataFrame({'y_pre':y_pre, 'y':data.y})
data_p['acc'] = data_p.y_pre == data_p.y
data_p
| y | y_pre | acc | |
|---|---|---|---|
| 0 | 1 | 1 | True |
| 1 | 1 | 1 | True |
| 2 | 1 | 1 | True |
| 3 | 1 | 1 | True |
| 4 | 1 | 1 | True |
| 5 | 1 | 1 | True |
| 6 | 1 | 1 | True |
| 7 | 1 | 1 | True |
| 8 | 1 | 1 | True |
| 9 | 1 | 1 | True |
| 10 | 1 | 1 | True |
| 11 | 1 | 1 | True |
| 12 | 1 | 1 | True |
| 13 | 1 | 1 | True |
| 14 | 1 | 1 | True |
| 15 | 1 | 1 | True |
| 16 | 1 | 3 | False |
| 17 | 1 | 1 | True |
| 18 | 1 | 1 | True |
| 19 | 1 | 3 | False |
| 20 | 1 | 1 | True |
| 21 | 1 | 1 | True |
| 22 | 1 | 1 | True |
| 23 | 1 | 1 | True |
| 24 | 1 | 1 | True |
| 25 | 1 | 1 | True |
| 26 | 1 | 3 | False |
| 27 | 1 | 1 | True |
| 28 | 1 | 1 | True |
| 29 | 1 | 1 | True |
| ... | ... | ... | ... |
| 180 | 3 | 3 | True |
| 181 | 3 | 3 | True |
| 182 | 3 | 3 | True |
| 183 | 3 | 3 | True |
| 184 | 3 | 3 | True |
| 185 | 3 | 3 | True |
| 186 | 3 | 3 | True |
| 187 | 3 | 3 | True |
| 188 | 3 | 3 | True |
| 189 | 3 | 3 | True |
| 190 | 3 | 3 | True |
| 191 | 3 | 3 | True |
| 192 | 3 | 3 | True |
| 193 | 3 | 3 | True |
| 194 | 3 | 3 | True |
| 195 | 3 | 3 | True |
| 196 | 3 | 3 | True |
| 197 | 3 | 3 | True |
| 198 | 3 | 3 | True |
| 199 | 3 | 3 | True |
| 200 | 3 | 3 | True |
| 201 | 3 | 1 | False |
| 202 | 3 | 3 | True |
| 203 | 3 | 3 | True |
| 204 | 3 | 3 | True |
| 205 | 3 | 3 | True |
| 206 | 3 | 3 | True |
| 207 | 3 | 3 | True |
| 208 | 3 | 3 | True |
| 209 | 3 | 3 | True |
210 rows × 3 columns
data_p.acc.sum()/len(data_p)
0.8952380952380953
