常见排序算法
本文涉及的算法有:
- 冒泡排序
- 选择排序
- 计数排序
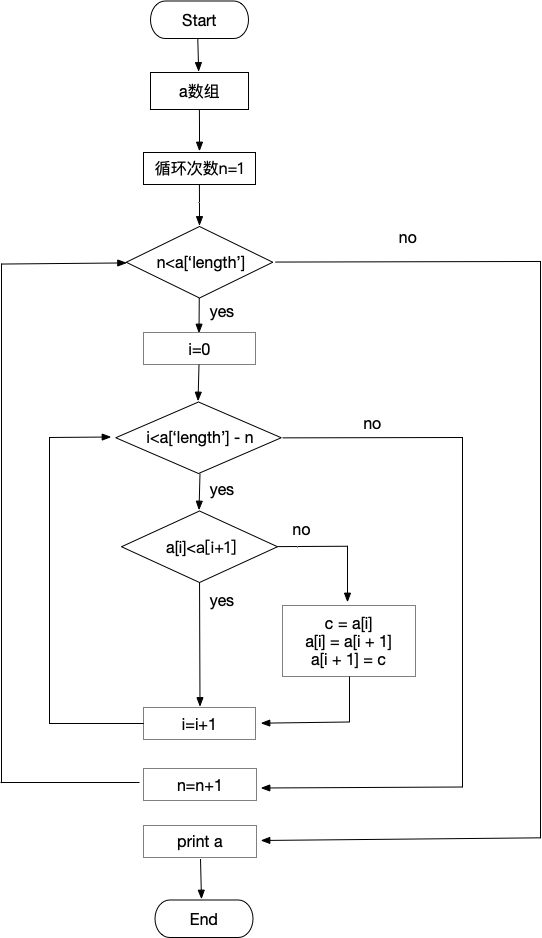
冒泡排序
- 伪代码
语法定义: "<-" 赋值符号 a[0]会转换为a['0']
a <- {
'0': 6,
'1': 1,
'2': 3,
'3': 5,
'4': 2,
'5': 4,
'length': 6
}
// 当前循环次数
n <- 1
while (n < a['length'])
// 当前选中的数字下标
index <- 0
while (index < a['length'] - n)
if (a[index] < a[index+1])
index <- index+1
else
c <- a[index]
a[index] <- a[index+1]
a[index+1] <- c
index <- index+1
end
n <- n+1
end
end
print a
end
- 流程图
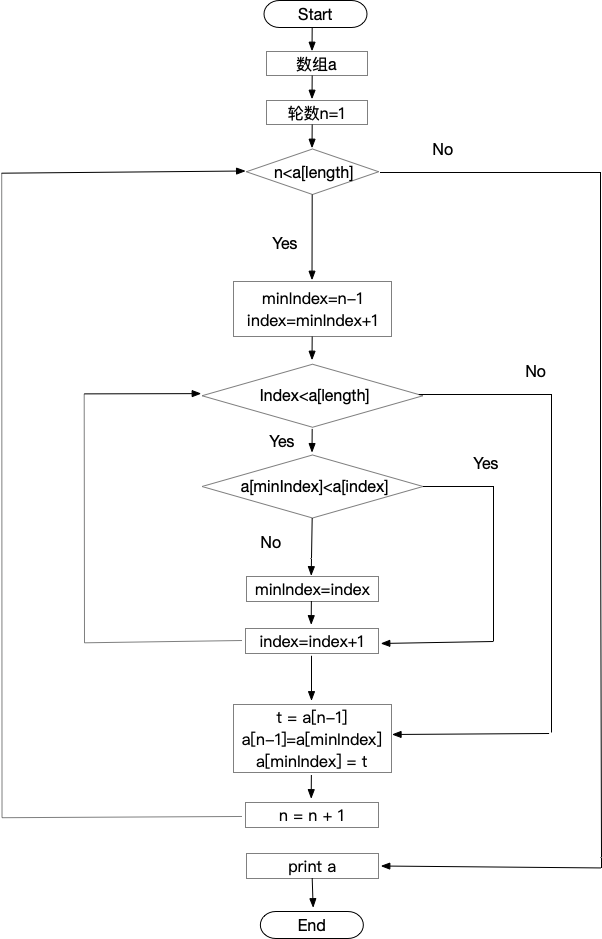
选择排序
- 伪代码
a <- {
'0': 3,
'1': 1,
'2': 6,
'3': 4,
'4': 5,
'5': 2,
'length': 6
}
// 当前轮数
n = 1
while(n < a['length'])
minIndex = n - 1
index = minIndex + 1
if (index < a['length'])
if (a[minIndex] < a[index])
index = index + 1
else
minIndex = index
index = index + 1
end
else
t = a[n - 1]
a[n - 1] = a[minIndex]
a[minIndex] = t
n = n + 1
end
end
print a
end
- 流程图
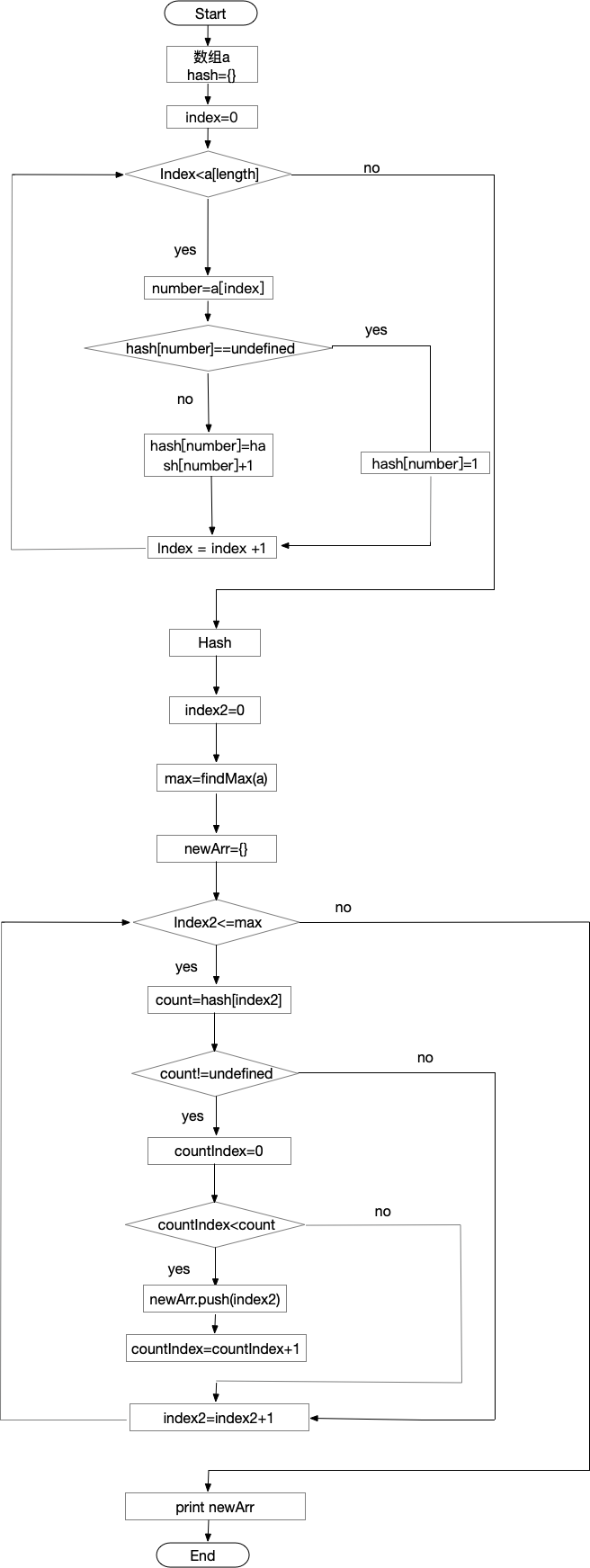
计数排序
- 伪代码
a <- {
'0':0,
'1':2,
'2':1,
'3':56,
'4':3,
'5':67,
'6':3,
'length':7
}
// length 是数组最大数字加1, 如果存在'66': 1, 那么length 就是 67
hash <- {
}
index <- 0
while(index < a['length'])
number <- a[index]
if hash[number] == undefined
hash[number] <- 1
else
hash[number] <- hash[number] + 1
end
index <- index + 1
end
hash <- {
'0':1,
'1':1,
'2':1,
'3':2,
'56':1,
'67':1
}
index2 <- 0
max <- findMax(a) // a中最大值是67, hash的length就是68, 从0开始, '0':1, '1':1 ..... '67':1
newArr <- {}
while(index2 <= max)
count <- hash[index2]
if count != undefined
countIndex = 0
while(countIndex < count)
newArr.push(index2)
countIndex <- countIndex + 1
end
end
index2 <- index2 + 1
end
print newArr
- 流程图