

版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。QQ邮箱地址:1120746959@qq.com,如有任何技术交流,可随时联系。
1 基本数据探索
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
X = pd.read_csv('C:\\ML\\MLData\\iris.data')
X.columns = ['sepal_length_cm', 'sepal_width_cm', 'petal_length_cm', 'petal_width_cm', 'class']
X.head()
X.sample(n=10)
X.shape
(149, 5)
X.dtypes
sepal_length_cm float64
sepal_width_cm float64
petal_length_cm float64
petal_width_cm float64
class object
dtype: object
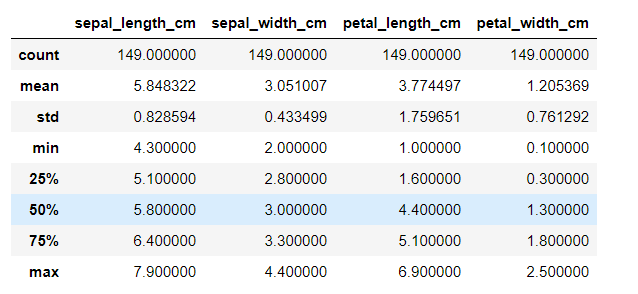
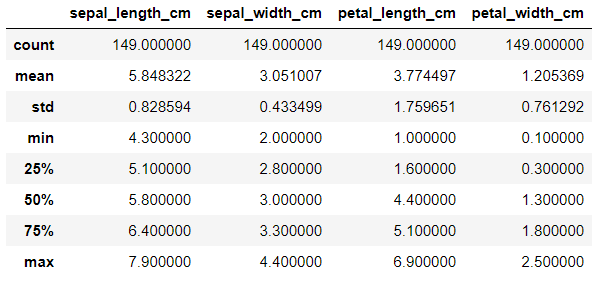
X.describe()
-
one-hot编码
# 创建一个简单的原始数据 testdata = pd.DataFrame({'age':[4,6,3,3],'pet':['cat','dog','dog','fish']}) testdata age pet 0 4 cat 1 6 dog 2 3 dog 3 3 fish pd.get_dummies(testdata,columns=['pet']) age pet_cat pet_dog pet_fish 0 4 1 0 0 1 6 0 1 0 2 3 0 1 0 3 3 0 0 1 testdata.pet.values.reshape(-1,1) array([['cat'], ['dog'], ['dog'], ['fish']], dtype=object) from sklearn.preprocessing import OneHotEncoder OneHotEncoder().fit_transform(testdata.age.values.reshape(-1,1)).toarray() array([[0., 1., 0.], [0., 0., 1.], [1., 0., 0.], [1., 0., 0.]]) -
时间类型处理(DatetimeIndex)
import pandas as pd data = pd.read_csv('kaggle_bike_competition_train.csv', header = 0, error_bad_lines=False) data.head() #先看下数据的样子,打印前5行
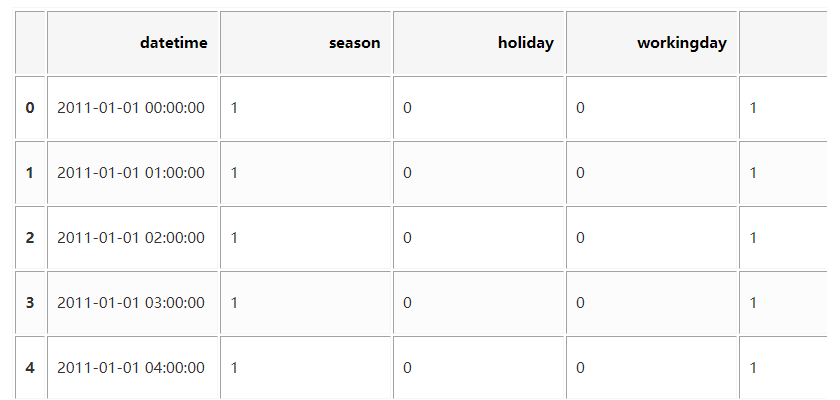
#下面我们只看datatime这个时间类型属性,
#首先,我们可以将它切分成
data = data.iloc[:,:1] #只看datatime这个属性
temp = pd.DatetimeIndex(data['datetime'])
data['date'] = temp.date #日期
data['time'] = temp.time #时间
data['year'] = temp.year #年
data['month'] = temp.month #月
data['day'] = temp.day #日
data['hour'] = temp.hour #小时
data['dayofweek'] = temp.dayofweek #具体星期几
data['dateDays'] = (data.date - data.date[0]) #生成一个时间长度特征 ['0days','0days',...,'1days',...]
data['dateDays'] = data['dateDays'].astype('timedelta64[D]') #转换成float型
data
2 数据可视化探索分析
-
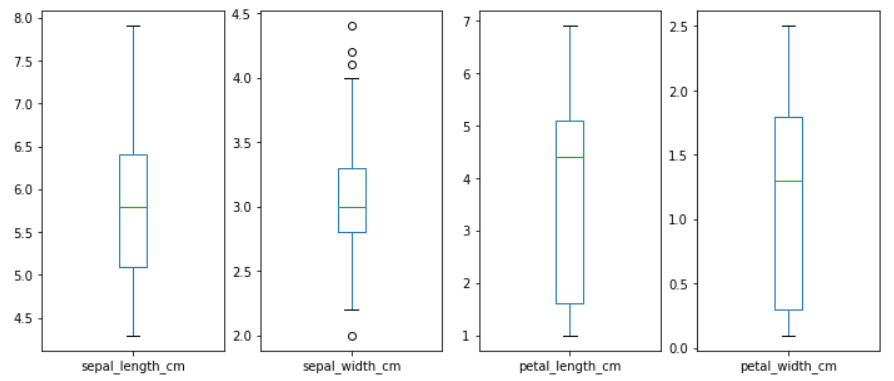
box 查看异常点
X.plot(kind="box",subplots=True,layout=(1,4),figsize=(12,5)) plt.show()
-
hist区间图
X.hist(figsize=(12,5),xlabelsize=1,ylabelsize=1) plt.show()
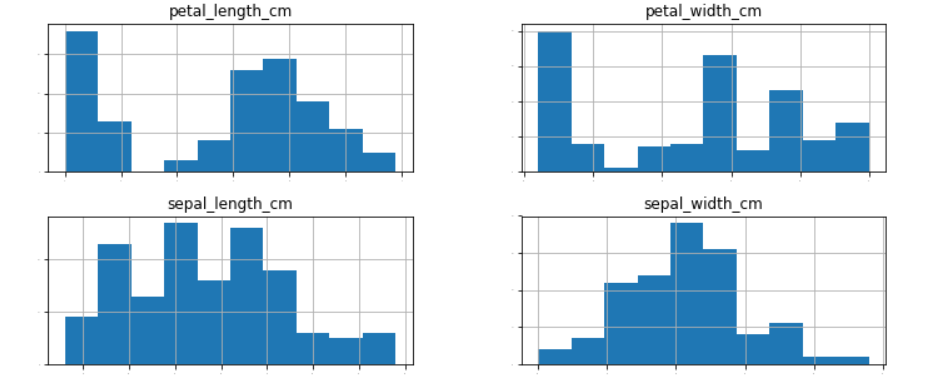
-
密度图
X.plot(kind="density",subplots=True,layout=(1,4),figsize=(12,5)) plt.show()
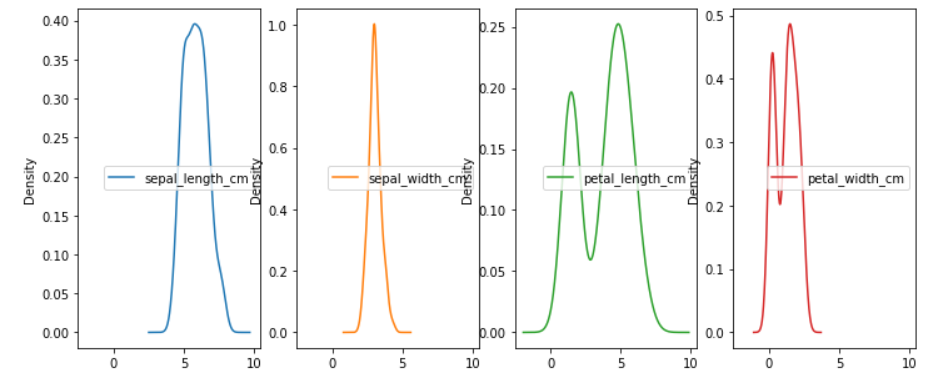
-
热力图关系图
fig = plt.figure(figsize=(10,10)) ax = fig.add_subplot(111) cax = ax.matshow(X.corr(),vmin=-1,vmax=1,interpolation="none") fig.colorbar(cax) ticks = np.arange(0,4,1) ax.set_xticks(ticks) ax.set_yticks(ticks) ax.set_xticklabels(col_name) ax.set_yticklabels(col_name) plt.show()
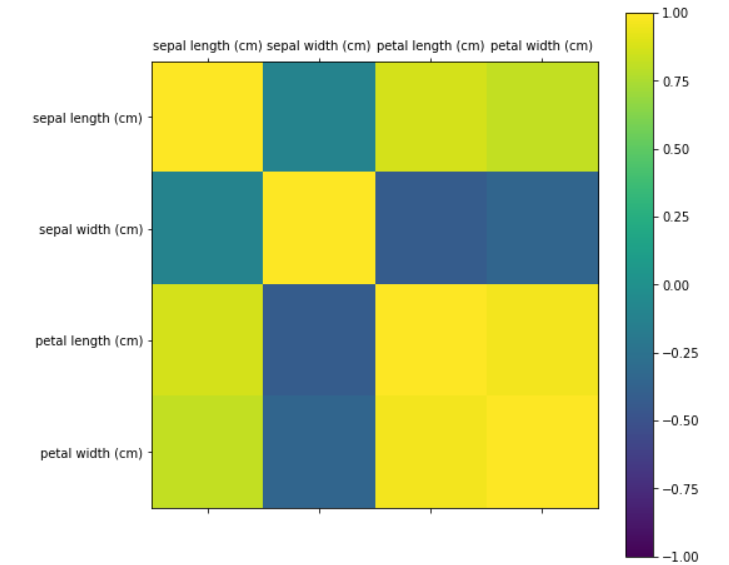
3 数据比例划分
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
all_inputs = iris_data[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values
all_classes = iris_data['class'].values
(training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_inputs, all_classes, train_size=0.75, random_state=1)
4 多分类模型集中评估
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
models = []
models.append(("AB",AdaBoostClassifier()))
models.append(("GBM",GradientBoostingClassifier()))
models.append(("RF",RandomForestClassifier()))
models.append(("ET",ExtraTreesClassifier()))
models.append(("SVC",SVC()))
models.append(("KNN",KNeighborsClassifier()))
models.append(("LR",LogisticRegression()))
models.append(("GNB",GaussianNB()))
models.append(("LDA",LinearDiscriminantAnalysis()))
names = []
results = []
for name,model in models:
result = cross_val_score(model,training_inputs,training_classes,scoring="accuracy",cv=5)
names.append(name)
results.append(result)
print("{} Mean:{:.4f}(Std{:.4f})".format(name,result.mean(),result.std()))
AB Mean:0.9097(Std0.0290)
GBM Mean:0.9370(Std0.0361)
RF Mean:0.9461(Std0.0442)
ET Mean:0.9370(Std0.0361)
SVC Mean:0.9640(Std0.0340)
KNN Mean:0.9374(Std0.0454)
LR Mean:0.9379(Std0.0353)
GNB Mean:0.9556(Std0.0391)
LDA Mean:0.9735(Std0.0360)
5 流水线交叉验证
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = []
pipeline.append(("ScalerET", Pipeline([("Scaler",StandardScaler()),
("ET",ExtraTreesClassifier())])))
pipeline.append(("ScalerGBM", Pipeline([("Scaler",StandardScaler()),
("GBM",GradientBoostingClassifier())])))
pipeline.append(("ScalerRF", Pipeline([("Scaler",StandardScaler()),
("RF",RandomForestClassifier())])))
names = []
results = []
for name,model in pipeline:
kfold = KFold(n_splits=5,random_state=42)
result = cross_val_score(model, training_inputs,training_classes, cv=kfold, scoring="accuracy")
results.append(result)
names.append(name)
print("{}: Error Mean:{:.4f} (Error Std:{:.4f})".format(
name,result.mean(),result.std()))
ScalerET: Error Mean:0.9372 (Error Std:0.0358)
ScalerGBM: Error Mean:0.9462 (Error Std:0.0332)
ScalerRF: Error Mean:0.9553 (Error Std:0.0275)
6 超参数网格交叉评估
from sklearn.model_selection import GridSearchCV
param_grid = {
"C":[0.1, 0.3, 0.5, 0.7, 0.9, 1.0, 1.3, 1.5, 1.7, 2.0],
"kernel":['linear', 'poly', 'rbf', 'sigmoid']
}
model = SVC()
kfold = KFold(n_splits=5, random_state=42)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring="accuracy", cv=kfold)
grid_result = grid.fit(training_inputs,training_classes)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
Best: 0.972973 using {'C': 0.9, 'kernel': 'linear'}
0.954955 (0.027681) with: {'C': 0.1, 'kernel': 'linear'}
0.927928 (0.021620) with: {'C': 0.1, 'kernel': 'poly'}
0.945946 (0.016821) with: {'C': 0.1, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 0.1, 'kernel': 'sigmoid'}
0.963964 (0.017933) with: {'C': 0.3, 'kernel': 'linear'}
0.954955 (0.028629) with: {'C': 0.3, 'kernel': 'poly'}
0.954955 (0.027681) with: {'C': 0.3, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 0.3, 'kernel': 'sigmoid'}
0.963964 (0.017933) with: {'C': 0.5, 'kernel': 'linear'}
0.954955 (0.028629) with: {'C': 0.5, 'kernel': 'poly'}
0.963964 (0.017933) with: {'C': 0.5, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 0.5, 'kernel': 'sigmoid'}
0.963964 (0.017933) with: {'C': 0.7, 'kernel': 'linear'}
0.963964 (0.033773) with: {'C': 0.7, 'kernel': 'poly'}
0.963964 (0.017933) with: {'C': 0.7, 'kernel': 'rbf'}
0.342342 (0.045336) with: {'C': 0.7, 'kernel': 'sigmoid'}
0.972973 (0.021914) with: {'C': 0.9, 'kernel': 'linear'}
0.963964 (0.033773) with: {'C': 0.9, 'kernel': 'poly'}
0.963964 (0.017933) with: {'C': 0.9, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 0.9, 'kernel': 'sigmoid'}
0.972973 (0.021914) with: {'C': 1.0, 'kernel': 'linear'}
0.963964 (0.033773) with: {'C': 1.0, 'kernel': 'poly'}
0.963964 (0.017933) with: {'C': 1.0, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 1.0, 'kernel': 'sigmoid'}
0.972973 (0.021914) with: {'C': 1.3, 'kernel': 'linear'}
0.963964 (0.033773) with: {'C': 1.3, 'kernel': 'poly'}
0.963964 (0.017933) with: {'C': 1.3, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 1.3, 'kernel': 'sigmoid'}
0.972973 (0.021914) with: {'C': 1.5, 'kernel': 'linear'}
0.963964 (0.033773) with: {'C': 1.5, 'kernel': 'poly'}
0.963964 (0.017933) with: {'C': 1.5, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 1.5, 'kernel': 'sigmoid'}
0.972973 (0.021914) with: {'C': 1.7, 'kernel': 'linear'}
0.954955 (0.028629) with: {'C': 1.7, 'kernel': 'poly'}
0.963964 (0.017933) with: {'C': 1.7, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 1.7, 'kernel': 'sigmoid'}
0.963964 (0.017933) with: {'C': 2.0, 'kernel': 'linear'}
0.954955 (0.028629) with: {'C': 2.0, 'kernel': 'poly'}
0.954955 (0.027681) with: {'C': 2.0, 'kernel': 'rbf'}
0.351351 (0.049646) with: {'C': 2.0, 'kernel': 'sigmoid'}
总结
本文没有华丽的技术,在于整合多分类模型集中评估,流水线交叉验证以及超参数网格交叉评估多种场景。
版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。QQ邮箱地址:1120746959@qq.com,如有任何技术交流,可随时联系。
秦凯新 于深圳
