

强化学习
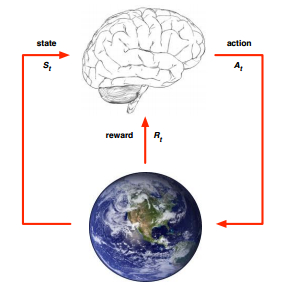
强化学习是代理面临的学习问题,它通过与动态环境反复交互试验从而学习到某种行为。它是机器学习的主要学习方法之一,智能体从环境到行为的学习,也就是如何在环境中采取一些列行为,才能使得回报信号函数的值最大,即获得的累积回报最大。
现在强化学习与深度学习结合的深度强化学习更加强大。
马尔科夫决策过程
在理解强化学习之前,我们先了解我们要解决什么样的问题。其实强化学习过程就是优化马尔科夫决策过程,它由一个数学模型组成,该模型在代理的控制下对随机结果进行决策。
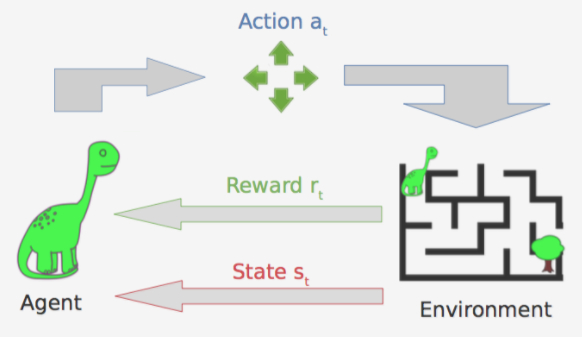
代理可以执行某些动作,例如上下左右移动,这些动作可能会得到一个回报,回报可以是正数也可以是负数,它会导致总分数变动。同时动作可以改变环境并导致一个新的状态,然后代理可以执行另外一个动作。状态、动作和回报的集合、转换规则等,构成了马尔科夫决策过程。
决策相关元素
- 状态集合,所有可能状态。
- 动作集合,所有动作,它能使某个状态转换为另一状态。
- 状态转移概率,特定的状态下执行不同动作的概率分布。
- 回报函数,从一个状态到另一个状态所得到的回报。
- 折扣因子,用于决定未来回报的重要性。
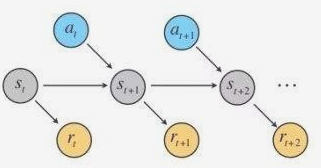
强化学习训练主要就是计算各个状态下不同动作的回报,并非瞬间完成的,而是要经过大量尝试。下一个状态取决于当前状态和动作,并且状态不依赖于先前的状态,没有记忆,符合马尔可夫性。
马尔科夫过程的优化
强化学习是agent与环境之间的迭代交互,需要考虑几点:
- 处于某种状态,决策者将在该状态下选择一个动作;
- 能随机进入一个新状态并给决策者相应的回报作为响应;
- 状态转移函数选择的动作将影响新状态的选择;
Q学习
Q学习即是学习不同状态下各个动作的质量,它定义为
它同样可以变换成Bellman Equation形态,
最优动作价值函数,
可以看到最大化当前的动作价值函数就是最大化当前回报和下一时刻状态的最优动作价值函数。
动作价值函数虽然能直接计算出Q值,但实际学习时并没有直接使用该Q值来更新,而是通过渐进的方式来更新。学习的方法可用如下伪代码说明,首先初始化Q学习的状态集和动作集组成的数组,然后观察初始状态,接着不断重复执行:选择一个动作,观察回报并转移到新状态,更新Q学习数组值,涉及迭代方式更新,由于我们不能知道下一刻状态的Q值,所以更新时用之前迭代的Q值来更新此次迭代的Q值,其中α表示学习率。
initialize Q[numstates,numactions] arbitrarily
observe initial state s
repeat
select and carry out an action a
observe reward R and new state s'
Q[s,a] = Q[s,a] + α(R + γmaxa'Q[s',a'] - Q[s,a])
s = s'
until terminated
小游戏
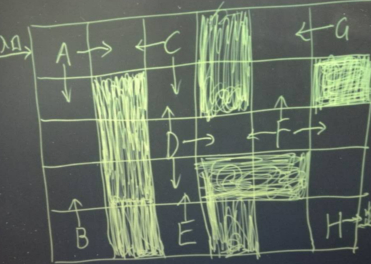
有个小游戏,如下图,进入入口后初始位置为A,阴影部分表示大炕,踩进去就没命了得重来,操作可以上下左右,最终走到H位置就算胜利。
实现Q学习
先定义地图的大小,以及大坑的位置、入口和出口。
ROWS = 5
COLUMNS = 6
ENTRANCE = (0, 0)
EXIT = (4, 5)
BARRIERS = list()
BARRIERS.append((1, 1))
BARRIERS.append((2, 1))
BARRIERS.append((3, 1))
BARRIERS.append((4, 1))
BARRIERS.append((0, 3))
BARRIERS.append((1, 3))
BARRIERS.append((3, 3))
BARRIERS.append((4, 3))
BARRIERS.append((3, 4))
BARRIERS.append((1, 5))
定义Q学习的一些参数设置,TIMES为尝试次数,R为随机因子,ALPHA为学习率,GAMMA为折扣因子,q_values为q值表,results为最终结果。
TIMES = 200
R = 0.05
ALPHA = 0.1
GAMMA = 0.9
q_values = dict()
results = list()
初始化q值表,按照行数列数和动作初始化所有q值。
def init_q_values():
for row in range(0, ROWS):
for col in range(0, COLUMNS):
state = State(row, col)
for action in Actions:
q = (state.row, state.col, action)
q_values[q] = 0
定义某个状态执行某个动作后得到的新状态,其中要考虑到地图的边缘。
def move(curr_state, action):
new_state = State(curr_state.row, curr_state.col)
# check borders
if action == Actions.up:
if (new_state.row - 1) >= 0:
new_state.row -= 1
elif action == Actions.down:
if (new_state.row + 1) <= (ROWS - 1):
new_state.row += 1
elif action == Actions.left:
if (new_state.col - 1) >= 0:
new_state.col -= 1
elif action == Actions.right:
if (new_state.col + 1) <= (COLUMNS - 1):
new_state.col += 1
return new_state
定义每一步的探索方法,分别执行不同动作找到最优的动作,此外还需要有一定概率的随机动作选择。
def explore(curr_state):
rand = random.random()
if rand <= R:
return random.choice(list(Actions))
else:
best = list()
best_action = Actions.up
best_value = -10000000
for action in Actions:
q = (curr_state.row, curr_state.col, action)
if q_values[q] > best_value:
best_action = action
best_value = q_values[q]
best.append(best_action)
# perhaps it has not only one best action
for action in Actions:
q = (curr_state.row, curr_state.col, action)
if action != best_action:
if q_values[q] == best_value:
best.append(action)
return random.choice(best)
定义更新状态操作,一旦选出最优的动作后将进行状态的更新,也就是更新q值表,如果到达出口则回报为0,如果掉入大坑则回报为-100。
def update(curr_state, last_action):
q = (curr_state.row, curr_state.col, last_action)
new_state = move(curr_state, last_action)
position = (new_state.row, new_state.col)
reward = -1
if position == EXIT:
reward = 0
elif position in BARRIERS:
reward = -100
old_value = q_values[q]
max_new = max([q_values[(new_state.row, new_state.col, a)] for a in Actions])
q_values[q] = old_value + ALPHA * (reward + (GAMMA * max_new) - old_value)
curr_state.row = new_state.row
curr_state.col = new_state.col
比如我们训练200次后,最终根据q值表就可以找到最佳的执行动作序列如下,说明经过这些动作操作后能成功到达出口。
Actions.right
Actions.right
Actions.down
Actions.down
Actions.right
Actions.right
Actions.right
Actions.down
Actions.down
Actions.down
github
-------------推荐阅读------------
我的开源项目汇总(机器&深度学习、NLP、网络IO、AIML、mysql协议、chatbot)
跟我交流,向我提问:

欢迎关注:

