

2018年10月25日凌晨5点20分,李咏因癌症在美国去世。。
咏哥就这样悄无声息地永远离开了我们。回想起自己的童年时光,多少个周六的晚上是在咏哥灿烂的笑容和风趣幽默的节目中欢乐地度过的,他短暂的一生,给观众朋友带来了欢乐和温暖,在冥冥之中亦为我们增添一份福分。咏哥,一路走好。
本文利用python爬虫技术,爬取豆瓣上《幸运52》和《非常6+1》观众短评,分析一下大家对 咏哥最经典的两个节目评价,缅怀咏哥。
from bs4 import BeautifulSoup
import urllib
import urllib.request
import pandas as pd
import numpy as np
## 短评
comment=[]
url_bas='https://movie.douban.com/subject/25949771/comments?start='
for i in range(0,180,20):
url=url_bas+str(i)+'&limit=20&sort=new_score&status=P'
html=urllib.request.urlopen(url)
soup=BeautifulSoup(html,'html.parser')
obj=soup.find_all('span',class_='short')
for i in obj:
comment.append(i.text)
## 评论时间
date=[]
url_bas='https://movie.douban.com/subject/25949771/comments?start='
for i in range(0,180,20):
url=url_bas+str(i)+'&limit=20&sort=new_score&status=P'
html=urllib.request.urlopen(url)
soup=BeautifulSoup(html,'html.parser')
obj=soup.find_all('span',class_='comment-time')
for i in obj:
date.append(i.text)
import re #去掉空格
date_re=[]
for i in date:
date_re.append(re.findall('2.*',i))
date_str=[] #脱出列表
for i in date_re:
date_str.append(i[0])
## 支持数
support=[]
url_bas='https://movie.douban.com/subject/25949771/comments?start='
for i in range(0,180,20):
url=url_bas+str(i)+'&limit=20&sort=new_score&status=P'
html=urllib.request.urlopen(url)
soup=BeautifulSoup(html,'html.parser')
obj=soup.find_all('span',class_='votes')
for i in obj:
support.append(i.text)
## 获得《非常6+1》评论
data=pd.DataFrame({'date':date_str,'comment':comment,'support':support})
data['showName']='非常6+1'
data.sort_values('date',ascending=True)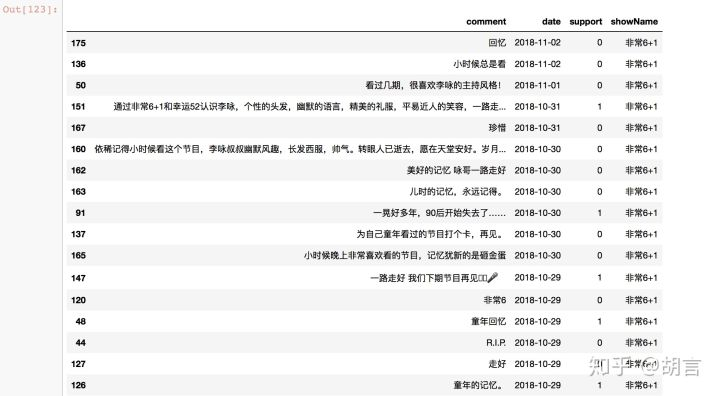
以上为《非常6+1》的近期短评,大家在咏哥离去后,在豆瓣里留下了对咏哥的缅怀和不舍。咏同样的方法可以爬取悼《幸运52》的近期评论,如下:
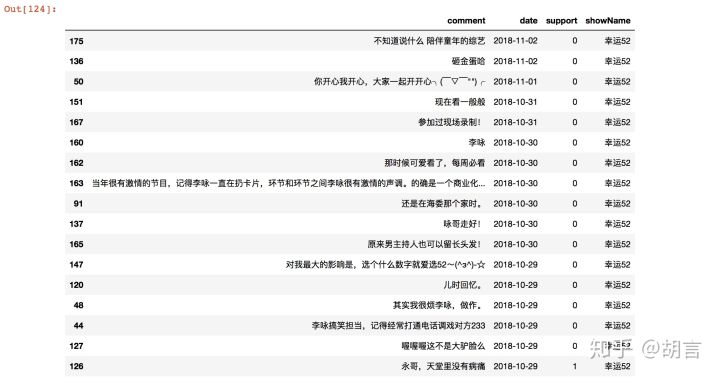
以上最近期的评论,有若干条让人很不舒服,不知道这几位观众为何在咏哥走后特意来说这些不好的话,也从侧面反映出《非常6+1》比《幸运52》对网友的影响可能更大一些。
接下来不妨用词云的方式来看一下两个节目的评论,需要用到分词技术:
from os import path
from wordcloud import WordCloud, ImageColorGenerator
import jieba
import pandas as pd
import numpy as np
from scipy.misc import imread
from PIL import Image
# jieba分词
line=','.join(comment) #将list转化为str
word_list=jieba.cut(line,cut_all=False)
word_cut=','.join(word_list)
#word_cut=list(word_list)
len(word_cut)
# wordcloud绘制,用咏哥的头像作为背景
cloud_mask = np.array(Image.open('/Users/huxugang/Github/liyong.png'))
back_color = imread('/Users/huxugang/Github/liyong.png')
image_colors = ImageColorGenerator(back_color)
wd=WordCloud(font_path='/Users/huxugang/Github/TTF/Bemoji.ttf',#Bemoji #kaiti #Simhei
background_color='white',max_words=500,
max_font_size=50,
random_state=15,
width=2000, # 图片的宽
height=1000, #图片的长
mask=cloud_mask)
WD=wd.generate(word_cut)
import matplotlib.pyplot as plt
WD.to_file('非常6+1.jpg')
# 显示词云图片
plt.figure(figsize=(10,10))
plt.axis('off') #去掉坐标轴
plt.imshow(WD.recolor(color_func=image_colors))
#plt.show()
《非常6+1》评论中占比最大的是“金蛋”,哈哈,可见砸金蛋的活动在观众心中记忆最深刻,
《幸运52》中更多的字眼是“童年”、“回忆”、“小时候”等字眼,暖暖的感动。

谨以此文献给我们永远的李咏大哥,祝咏哥在天堂幸福快乐。
桃李无言,歌咏有悼咏哥,一路走好。。
