

论文地址:Convolutional Sequence to Sequence Learning
这篇论文是由facebook AI 团队提出,其设计了一种完全基于卷积神经网络的模型,应用于seq2seq 任务中。在机器翻译任务上不仅比之前的方法好 (Transformer 没出来之前。。。),同时还大大提高了运行速度。
这几天看了知乎专栏“西土城搬砖日常”对这篇论文的笔记,感觉写的很好,很受启发。本篇文章大部分的内容都转载于此,只是加了我个人的 pytorch 实现 (我个人一直认为,如果看了一篇论文之后,不自己动手用 code 实现一下,那其实就和没看过一样)。
CNN-Seq2Seq 解决了什么问题
在以往的自然语言处理领域,包括 seq2seq 任务中,大多数都是通过 RNN 来实现。这是因为RNN 的链式结构,能够很好地应用于处理序列信息。但是,RNN 也有明显的缺点, 一是由于不能实现并行操作,导致运行速度慢;二是并不能很好地处理句子中的结构化信息,或者说更复杂的关系信息。
相比之下,CNN 的优势就很明显了。最重要的当然是 CNN 因为能够并行处理数据,所以计算更加高效。此外,因为 CNN 是层级结构 (可以通过叠加 CNN 的 layer 去进一步捕捉更远距离的词间依赖),与循环网络建模的链式结构相比,层次结构提供了一种较短的路径来捕获词之间远程的依赖关系,因此也可以更好地捕捉更复杂的关系。
模型结构分析
整体模型结构如下图,图中表示的从英语翻译到法语的过程。该模型依旧是 encoder-decoder + attention 模块的大框架:encoder 和 decoder 采用了相同的卷积结构,其中的非线性部分采用的是门控结构 gated linear units(GLM);attention 部分采用的是多跳注意力机制 multi-hop attention,也即在 decoder 的每一个卷积层都会进行 attention 操作,并将结果输入到下一层。
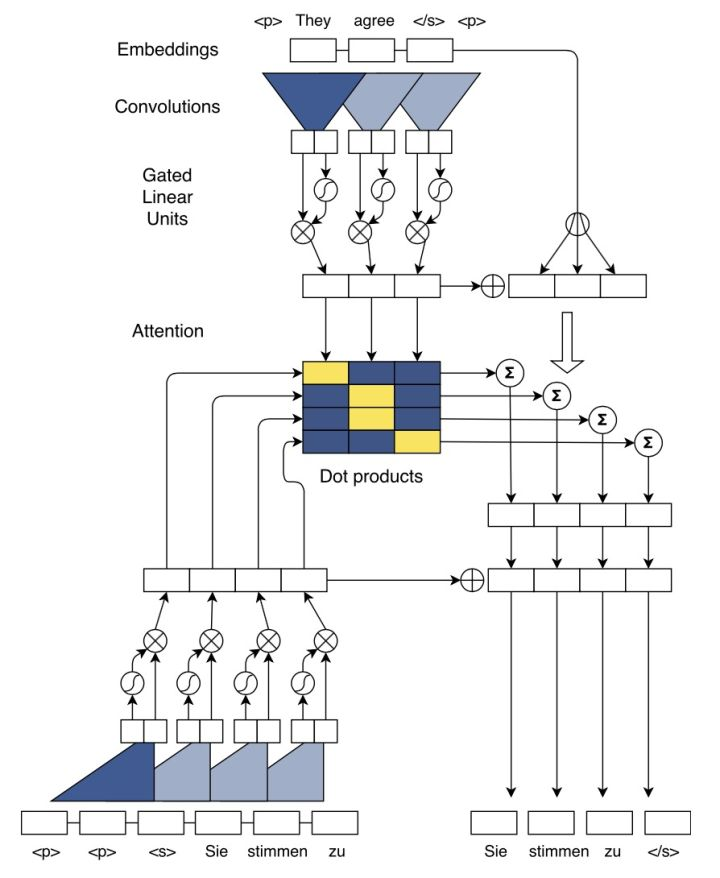
接下来分步讲解:
Position Embeddings
加入位置向量,给予模型正在处理哪一位置的信息,
词向量: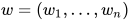
位置向量: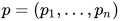
最终表示向量: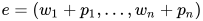 ,下文中用
,下文中用 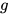 来表示
来表示
Convolutional Block Structure
encoder 和 decoder 都是由 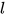 层卷积层构成,encoder 输出为
层卷积层构成,encoder 输出为 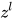 ,decoder输出为
,decoder输出为 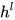 。由于卷积网络是层级结构,通过层级叠加能够得到远距离的两个词之间的关系信息。
。由于卷积网络是层级结构,通过层级叠加能够得到远距离的两个词之间的关系信息。
这里把一次 "卷积计算+非线性计算" 看作一个单元 Convolutional Block,这个单元在一个卷积层内是共享的。
卷积计算:在原始论文中,作者使用了 kernel size 为 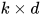 的 2 维卷积核,filter 的个数为
的 2 维卷积核,filter 的个数为 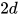 。其中
。其中 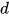 为词向量长度,
为词向量长度, 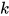 为卷积窗口大小,每次卷积生成两列
为卷积窗口大小,每次卷积生成两列 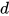 维向量
维向量 ![Y =[A,B]\in R^{2d}](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2018/12/16/167b65c985a22b35~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png) 。在下面的实现中,我实现的稍微有点不同,我用了 kernel size 为
。在下面的实现中,我实现的稍微有点不同,我用了 kernel size 为 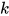 一维卷积核,filter 的个数同样为
一维卷积核,filter 的个数同样为 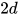 。
。
非线性计算:非线性部分采用的是门控结构 gated linear units (GLU)。GLU 不仅有效地降低了梯度弥散,而且还保留了非线性的能力,公式如下:
![v([A \, B]) = A \otimes \delta(B)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2018/12/16/167b65c9915b947d~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
其中,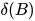 是门控函数,控制着网络中的信息流,即哪些能够传递到下一个神经元中。
是门控函数,控制着网络中的信息流,即哪些能够传递到下一个神经元中。
残差连接:每一层都有这样一个 short cut 的操作,把输入与输出相加,输入到下一层网络中。
![h^l_i =v(W^l[h^{l-1}_{i-k/2} ,...,h^{l-1}_{i+k/2} ]+b^l )+h^{l-1}_i](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2018/12/16/167b65c983deadeb~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
输出:decoder 的最后一层卷积层的最后一个单元输出经过 softmax 得到下一个目标词的概率。
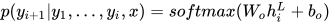
Multi-step Attention
原理与传统的 attention 相似,attention 权重由 decoder 的当前输出 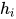 和 encoder 的所有输出共同决定,利用该权重对 encoder 的输出进行加权,得到了表示输入句子信息的向量
和 encoder 的所有输出共同决定,利用该权重对 encoder 的输出进行加权,得到了表示输入句子信息的向量 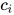 ,
,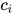 和
和 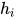 相加组成新的
相加组成新的 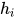 。计算公式如下:
。计算公式如下:
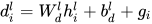
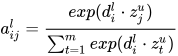
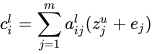
这里 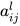 是权重信息,采用了向量点积的方式再进行 softmax 操作,这里向量点积可以通过矩阵计算,实现并行计算。
是权重信息,采用了向量点积的方式再进行 softmax 操作,这里向量点积可以通过矩阵计算,实现并行计算。
最终得到 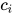 和
和 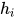 相加组成新的
相加组成新的 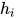 。如此,在每一个卷积层都会进行 attention 的操作,得到的结果输入到下一层卷积层,这就是多跳注意机制 multi-hop attention。这样做的好处是使得模型在得到下一个注意时,能够考虑到之前的已经注意过的词。
。如此,在每一个卷积层都会进行 attention 的操作,得到的结果输入到下一层卷积层,这就是多跳注意机制 multi-hop attention。这样做的好处是使得模型在得到下一个注意时,能够考虑到之前的已经注意过的词。
代码实现
代码实现按照之前描述的步骤,总体结构和一般的 seq2seq 模型一样,具体如下。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Encoder(nn.Module):
"""
Args:
input: batch, seq_len
Returns:
attn: batch, seq_len, hidden_size
outputs: batch, seq_len, hidden_size
"""
def __init__(self, opt, vocab_size):
super(Encoder, self).__init__()
self.vocab_size = vocab_size
self.embedding_size = opt.embedding_size
self.hidden_size = opt.hidden_size
self.in_channels = opt.hidden_size * 2
self.out_channels = opt.hidden_size * 2
self.kernel_size = opt.kernel_size
self.stride = 1
self.padding = (opt.kernel_size - 1) / 2
self.layers = opt.enc_layers
self.embedding = nn.Embedding(self.vocab_size, self.embedding_size)
self.affine = nn.Linear(self.embedding_size, 2*self.hidden_size)
self.softmax = nn.Softmax()
self.conv = nn.Conv1d(self.in_channels, self.out_channels, self.kernel_size, self.stride, self.padding)
self.mapping = nn.Linear(self.hidden_size, 2 * self.hidden_size)
self.bn1 = nn.BatchNorm1d(self.hidden_size)
self.bn2 = nn.BatchNorm1d(self.hidden_size * 2)
def forward(self, *input):
# batch, seq_len_src, dim
inputs = self.embedding(input)
# batch, seq_len_src, 2*hidden
outputs = self.affine(inputs)
# short-cut
_outputs = outputs
for i in range(self.layers):
# batch, 2*hidden, seq_len_src
outputs = outputs.permute(0, 2, 1)
# batch, 2*hidden, seq_len_src
outputs = self.conv(outputs)
outputs = F.glu(outputs)
# batch, seq_len_src, 2*hidden
outputs = outputs.transpose(1, 2)
# A, B: batch, seq_len_src, hidden
A, B = outputs.split(self.hidden_size, 2)
# A2: batch * seq_len_src, hidden
A2 = A.contiguous().view(-1, A.size(2))
# B2: batch * seq_len_src, hidden
B2 = B.contiguous().view(-1, B.size(2))
# attn: batch * seq_len_src, hidden
attn = torch.mul(A2, self.softmax(B2))
# attn2: batch * seq_len_src, 2 * hidden
attn2 = self.mapping(attn)
# outputs: batch, seq_len_src, 2 * hidden
outputs = attn2.view(A.size(0), A.size(1), -1)
# batch, seq_len_src, 2 * hidden_size
out = attn2.view(A.size(0), A.size(1), -1) + _outputs
_outputs = out
return attn, out
def load_pretrained_vectors(self, opt):
if opt.pre_word_vecs_enc is not None:
pretrained = torch.load(opt.pre_word_vecs_enc)
self.word_lut.weight.data.copy_(pretrained)
class Decoder(nn.Module):
"""
Decoder
Args:
Input: batch, seq_len
return:
output: seq_len, vocab_size
"""
def __init__(self, opt, vocab_size):
super(Decoder, self).__init__()
self.vocab_size = vocab_size
self.embedding_size = opt.embedding_size
self.hidden_size = opt.hidden_size
self.in_channels = opt.hidden_size * 2
self.out_channels = opt.hidden_size * 2
self.kernel_size = opt.kernel_size
self.kernel = opt.kernel_size
self.stride = 1
self.padding = (opt.kernel_size - 1) / 2
self.layers = 1
self.embedding = nn.Embedding(self.vocab_size, self.embedding_size)
self.affine = nn.Linear(self.embedding_size, 2 * self.hidden_size)
self.softmax = nn.Softmax()
self.conv = nn.Conv1d(self.in_channels, self.out_channels, self.kernel_size, self.stride, self.padding)
self.mapping = nn.Linear(self.hidden_size, 2*self.hidden_size)
self.fc = nn.Linear(self.hidden_size * 2, vocab_size)
self.softmax = nn.Softmax()
# enc_attn: src_seq_len, hidden_size
def forward(self, target, enc_attn, source_seq_out):
# batch, seq_len_tgt, dim
inputs = self.embedding(target)
# batch, seq_len_tgt, 2*hidden
outputs = self.affine(inputs)
for i in range(self.layers):
# batch, 2*hidden, seq_len_tgt
outputs = outputs.permute(0, 2, 1)
# batch, 2*hidden, seq_len_tgt
outputs = self.conv(outputs)
# This is the residual connection,
# for the output of the conv will add kernel_size/2 elements
# before and after the origin input
if i > 0:
conv_out = conv_out + outputs
outputs = F.glu(outputs)
# batch, seq_len_tgt, 2*hidden
outputs = outputs.transpose(1, 2)
# A, B: batch, seq_len_tgt, hidden
A, B = outputs.split(self.hidden_size, 2)
# A2: batch * seq_len_tgt, hidden
A2 = A.contiguous().view(-1, A.size(2))
# B2: batch * seq_len_tgt, hidden
B2 = B.contiguous().view(-1, B.size(2))
# attn: batch * seq_len_tgt, hidden
dec_attn = torch.mul(A2, self.softmax(B2))
dec_attn2 = self.mapping(dec_attn)
dec_attn2 = dec_attn2.view(A.size(0), A.size(1), -1)
# enc_attn1: batch, seq_len_src, hidden_size
enc_attn = enc_attn.view(A.size(0), -1, A.size(2))
# dec_attn1: batch, seq_len_tgt, hidden_size
dec_attn = dec_attn.view(A.size(0), -1, A.size(2))
# attn_matrix: batch, seq_len_tgt, seq_len_src
_attn_matrix = torch.bmm(dec_attn, enc_attn.transpose(1, 2))
attn_matrix = self.softmax(_attn_matrix.view(-1, _attn_matrix.size(2)))
# normalized attn_matrix: batch, seq_len_tgt, seq_len_src
attn_matrix = attn_matrix.view(_attn_matrix.size(0), _attn_matrix.size(1), -1)
# attns: batch, seq_len_tgt, 2 * hidden_size
attns = torch.bmm(attn_matrix, source_seq_out)
# outpus: batch, seq_len_tgt, 2 * hidden_size
outputs = dec_attn2 + attns
outputs = F.log_softmax(self.fc(outputs))
return outputs
def load_pretrained_vectors(self, opt):
if opt.pre_word_vecs_enc is not None:
pretrained = torch.load(opt.pre_word_vecs_enc)
self.word_lut.weight.data.copy_(pretrained)
class NMTModel(nn.Module):
def __init__(self, encoder, decoder):
super(NMTModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, source, target):
# attn: batch, seq_len, hidden
# out: batch, seq_len, 2 * hidden_size
attn, source_seq_out = self.encoder(source)
# batch, seq_len_tgt, hidden_size
out = self.decocer(target, attn, source_seq_out)
return out启发
从现在的视角来看这篇论文,有很大的启发意义。这可能是一个 Attention + CNN 结构慢慢反杀传统 RNN 的号角。
Facebook 的科学家将 CNN 成功应用于 seq2seq 任务中,发挥了 CNN 并行计算和层级结构的优势;也从另一方面证明了 CNN 的层级结构可以发现句子中的结构信息,这是传统 RNN 不能比拟的。
