pip install -i http://pypi.douban.com/simple scrapy
// -i http://pypi.douban.com/simple 为加速安装
scrapy startproject ArticleSpider //会在当前路径创建项目 ArticleSpider为项目名
cd ArticleSpider && genspider example example.com //创建爬虫模板 example为spider名称 example.com为网站域名
scrapy.cfg //项目配置
ArticleSpider/settings.py //工程配置
ArticleSpider/pipelines.py //数据存储
ArticleSpider/middlewares.py 存放自定制的middlewares
ArticleSpider/items //保存格式
spilers //具体的爬虫
import scrapy
class XXX(scrapy.Spider):
name = 'xxx' //名字
allowed_domains = ['example.com'] //域名
start_urls = ['http://example.com'] //起始url
def parse(self, response): //具体的爬虫逻辑
pass
--- main.py ---
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","xxx"])
scrapy shell url
//然后回进入终端,使用response参数获取爬取的内容如:
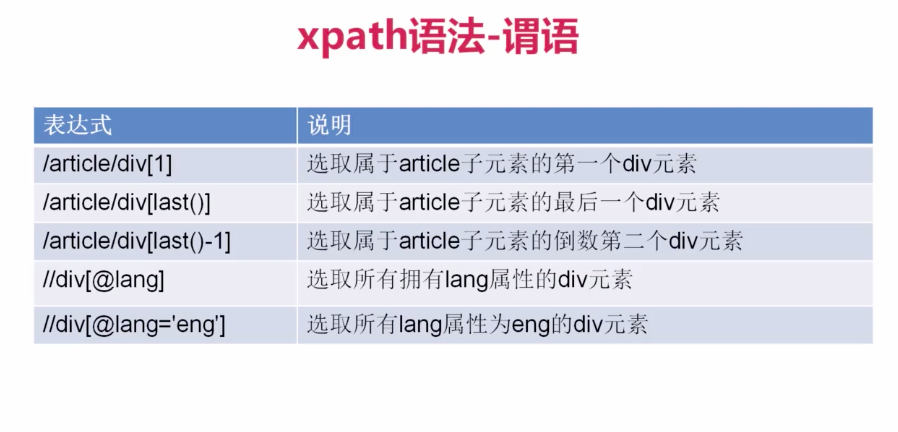
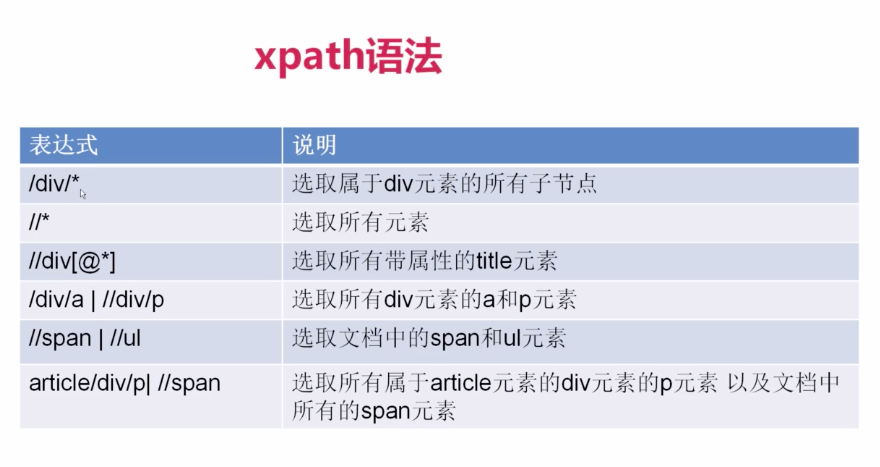
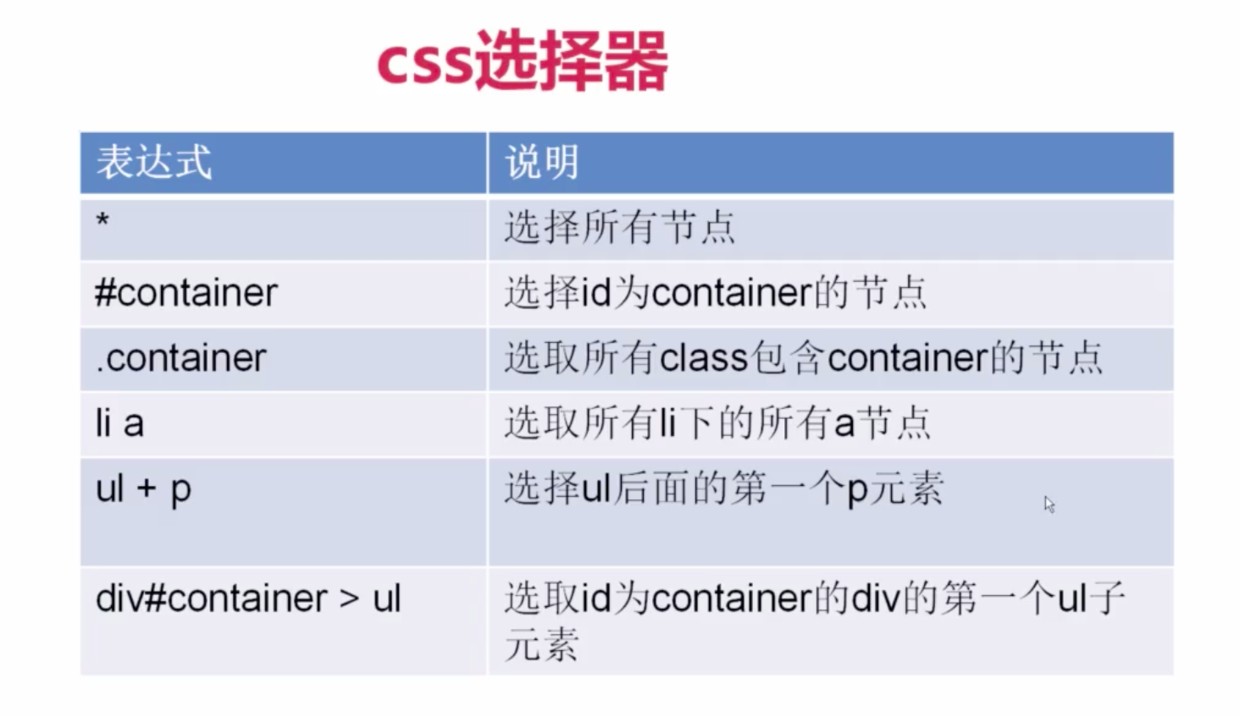
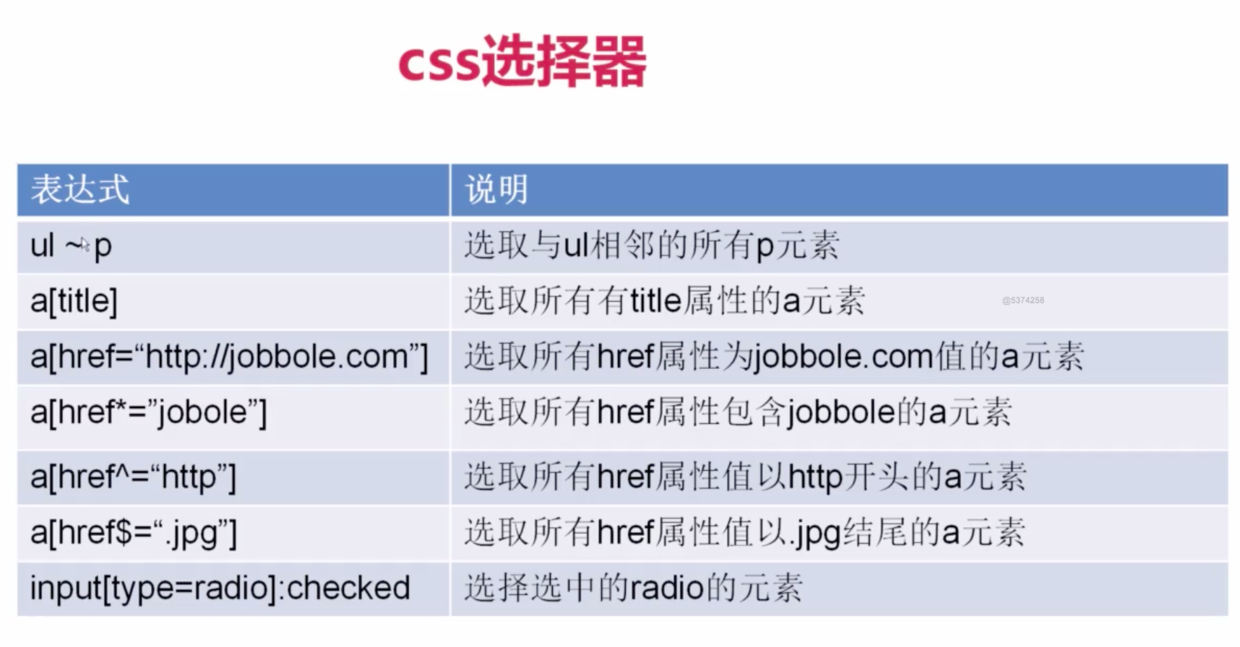
response.xpath()