

生成模型,绕不开 VI,这是一个在 ML 届经常出现的词。
这个,扫一眼,就可以看出,没有数学,只是算积分。为了给大家节省时间,我给大家读一下。教科书 TLDL。这篇看上去不错: 请解释下variational inference? 这里加入计算过程。
~~~~~~~~~~~~~~~~~~~~~~~~
我的理解,他们的意思是这样,为了逼近分布 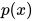 :
:
- 引入一堆
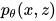 ,
,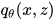 之类。
之类。 - 还有一些先验,例如
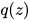 之类。
之类。 - 选一个散度,衡量逼近的程度(选哪个散度,实际看心情)。
- 于是,得到一个最优化问题:通过调节
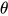 ,最小化散度,就完成了分布的逼近。
,最小化散度,就完成了分布的逼近。 - 这个问题,很难解析解(除非做很多简化)。
- 于是,用 EM / GD / SGD / 二阶方法 等等,总之都是贪心法,暴力求解。
~~~~~~~~~~~~~~~~~~~~~~~~
下面看公式。如果,希望用 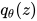 逼近
逼近 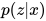 ,取 KL 散度,优化问题是:
,取 KL 散度,优化问题是:
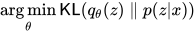
自然的问题是,为什么不把两项倒过来?因为 KL 散度有缺陷,选散度就是这么写意。
然后有个看上去好像说了什么,实际什么都没有:最小化 KL 散度 = 最大化 ELBO,即:
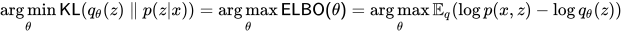
~~~~~~~~~~~~~~~~~~~~~~~~
让我们看看这个有多无聊。KL 散度的定义:
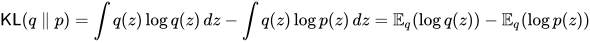
于是:
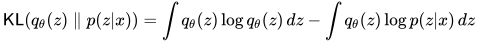
由于:
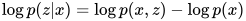
且这项和 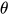 无关,可以忽略:
无关,可以忽略:
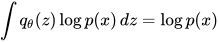
因此,优化过程,等价于:
![\mathop{\arg\min}_\theta \Big[ \int q_\theta(z) \log q_\theta(z) \, dz - \int q_\theta(z) \log p(x,z) \, dz \Big]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2018/12/4/167796ed28b38137~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
即:
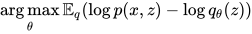
~~~~~~~~~~~~~~~~~~~~~~~~
再看优化过程,我们需要算:
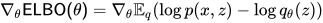
这个也特别简单,直接带进去就可以算:
![\begin{align} \frac{\partial}{\partial \theta} \int q_\theta(z) \Big (\log p(x,z) - \log q_\theta(z) \Big) \, dz &= \int \frac{\partial}{\partial \theta} \Big[ q_\theta(z) \Big (\log p(x,z) - \log q_\theta(z) \Big) \Big] \, dz \\&= \int \frac{\partial}{\partial \theta} \Big( q_\theta(z) \log p(x,z) \Big) - \frac{\partial}{\partial \theta} \Big( q_\theta(z) \log q_\theta(z) \Big) \, dz \\&= \int \frac{\partial q_\theta(z)}{\partial \theta} \log p(x,z) - \frac{\partial q_\theta(z)}{\partial \theta} \log q_\theta(z) - \frac{\partial q_\theta(z)}{\partial \theta} \, dz \end{align}](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2018/12/4/167796ed35247498~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
由于:
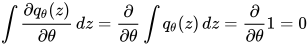
因此:
![\begin{align} \nabla_\theta \mathsf{ELBO(\theta)} &= \int \frac{\partial q_\theta(z)}{\partial \theta} \Big( \log p(x,z) - \log q_\theta(z) \Big) \,dz \\&= \int q_\theta(z) \frac{\partial \log q_\theta(z)}{\partial \theta} \Big( \log p(x,z) - \log q_\theta(z) \Big) \,dz \\&= \int q_\theta(z) \nabla_\theta \log q_\theta(z) \Big( \log p(x,z) - \log q_\theta(z) \Big) \,dz \\&= \mathbb{E}_q [ \nabla_\theta \log q_\theta(z) (\log p(x,z) - \log q_\theta(z)) ] \end{align}](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2018/12/4/167796ed2ce329cc~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
然后写成 SGD,就是所谓 Black Box Variational Inference (BBVI)。
后面还有很多花样,有空时慢慢补充。
