

说在前面
RocketMQ在底层存储设计上借鉴了Kafka,但是也有它独到的设计,本文主要关注深刻影响着RocketMQ性能的底层文件存储设计,中间会穿插一些Kafka的内容以作为对比。
正文
(1) Case
要讲存储设计,我们先复习下RMQ中的文件及其作用。
Commit Log,一个文件集合,每个文件1G大小,存储满后存下一个,为了讨论方便可以把它当成一个文件,所有消息内容全部持久化到这个文件中;Consume Queue:一个Topic可以有多个,每一个文件代表一个逻辑队列,这里存放消息在Commit Log的偏移值以及大小和Tag属性。
假如集群有一个Broker,Topic为binlog的队列(Consume Queue)数量为4,如下图所示,按顺序发送这5条消息。
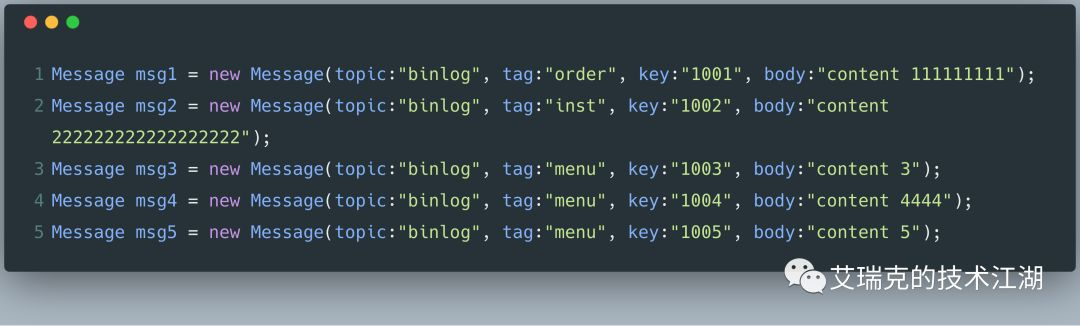
先关注下Commit Log和Consume Queue。
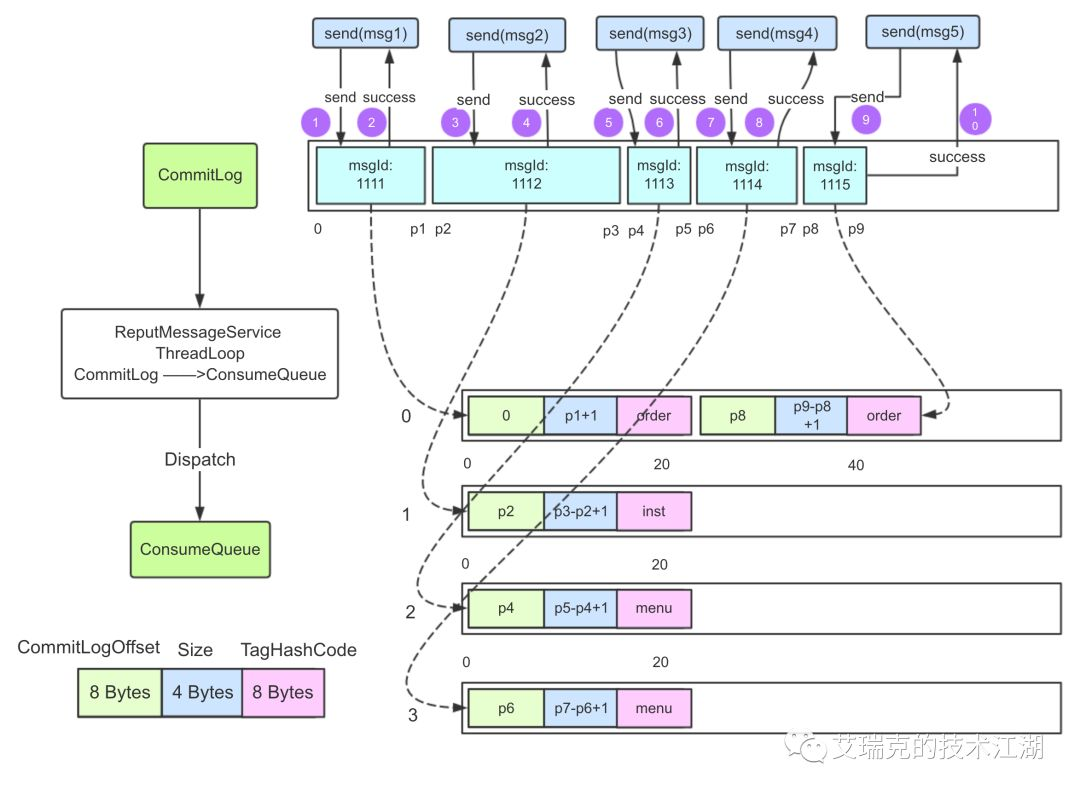
图片:RMQ文件全貌
RMQ的消息整体是有序的,所以这5条消息按顺序将内容持久化在Commit Log中。Consume Queue则是用于将消息均衡地按序排列在不同的逻辑队列,集群模式下多个消费者就可以并行消费Consume Queue的消息。现在我们对RMQ的各个文件有个大概的印象了。
(2) Page Cache
通常文件随机读写非常慢,但对文件进行顺序读写,速度几乎是接近于内存的随机读写,为什么会这么快,原因就是OS对文件IO有优化。OS发现系统的物理内存有大量剩余时,为了提高IO的性能,将一部分的内存用作Page Cache。
OS在读磁盘时会按照文件顺序预先将内容读到Cache中,以便下次读时能命中Cache,写磁盘时直接写到Cache中就写返回,由pdflush以某种策略将Cache的数据Flush回磁盘。
文件顺序IO时,读和写的区域都是被OS智能Cache过的热点区域,不会产生大量缺页(Page Fault)中断而再次读取磁盘,文件的IO几乎等同于内存的IO。
(3) 刷盘
刷盘分成:同步刷盘和异步刷盘
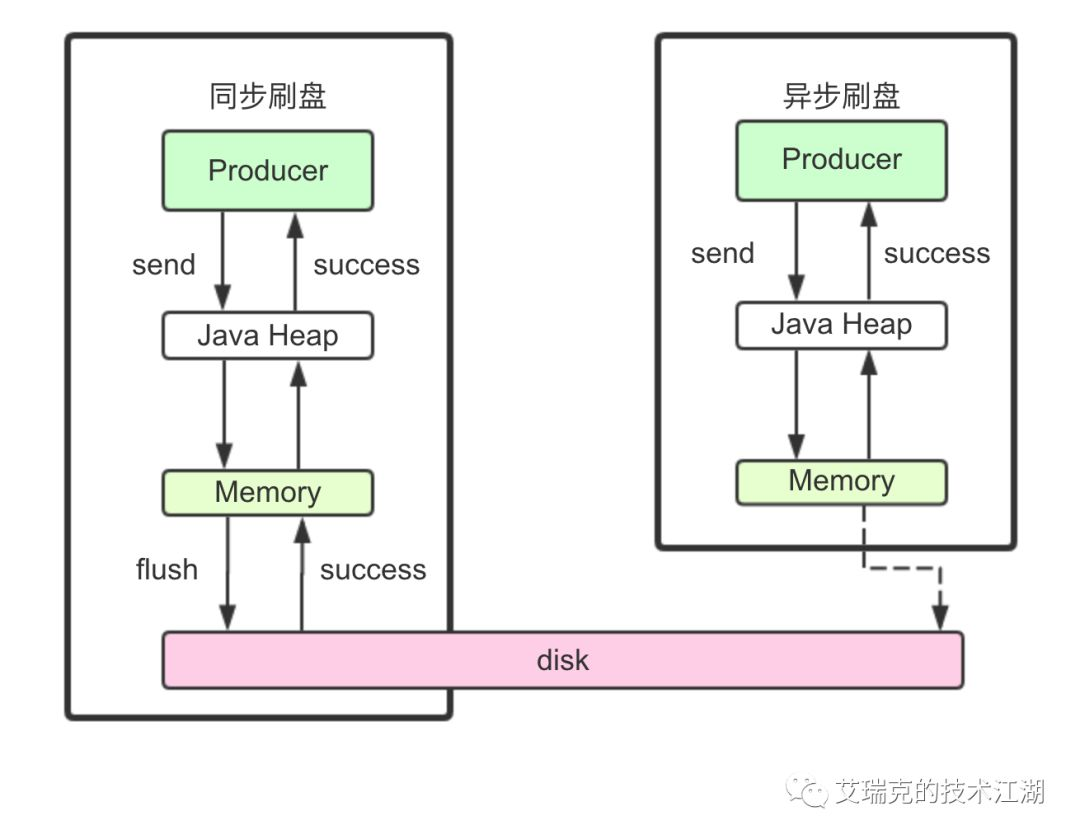
图片:刷盘方式总览
同步刷盘
在消息真正落盘后,才返回成功给Producer,只要磁盘阵列RAID5完好,消息就不会丢。一般只用于金融场景,这种方式不是本文讨论的重点,因为没有充分利用Page Cache的特点。
异步刷盘
读写文件充分利用了Page Cache,即写入Page Cache就返回成功给Producer。之后的内容全部以异步刷盘方式来讨论。
(4) RMQ发送消息
例子和原理回顾完,从消息发送和消息接收来看RMQ中被mmap后的Commit Log和Consume Queue的IO情况。
发送时,Producer不直接与Consume Queue打交道。上文提到过,RMQ所有的消息都会存放在Commit Log中,为了使消息存储不发生混乱,多线程对Commit Log写会上锁。
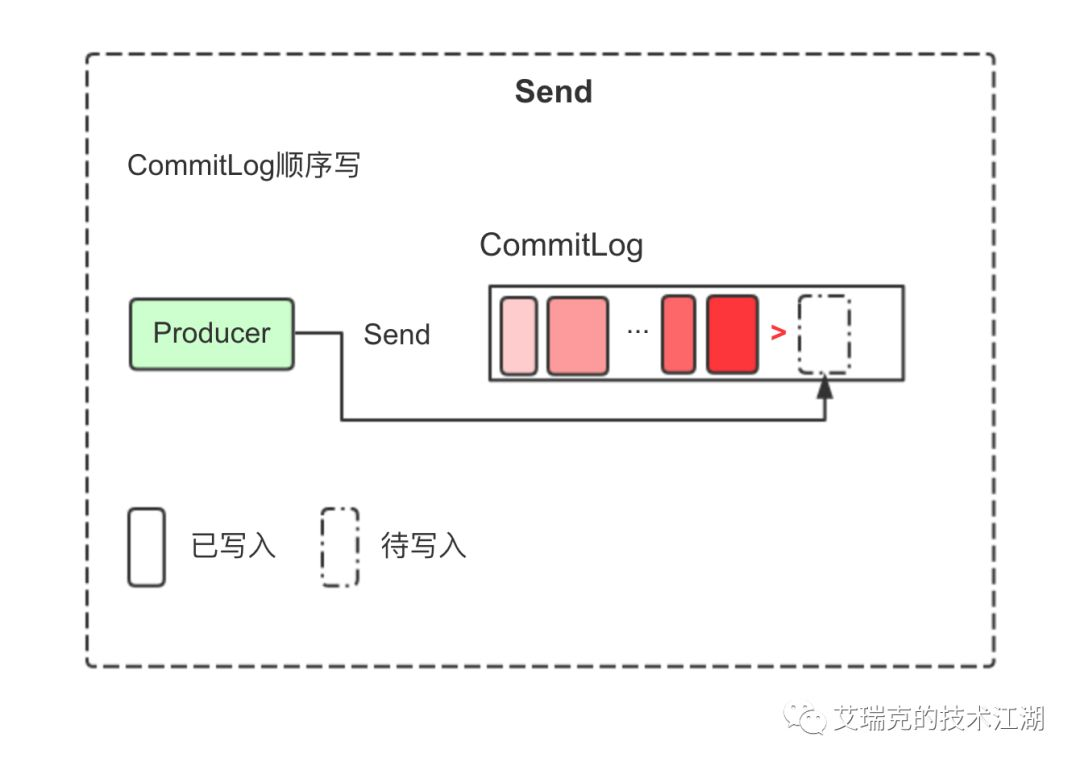
图片:Commit Log顺序写
消息持久被锁串行化后,对Commit Log就是顺序写,也就是常说的Append操作。配合上Page Cache,RMQ在写Commit Log时效率会非常高。正因为写Commit Log很快,RMQ也大胆提供了自旋锁以提高性能。
Commit Log持久后,Broker会将消息逐个异步Dispatch到对应的Consume Queue文件中。
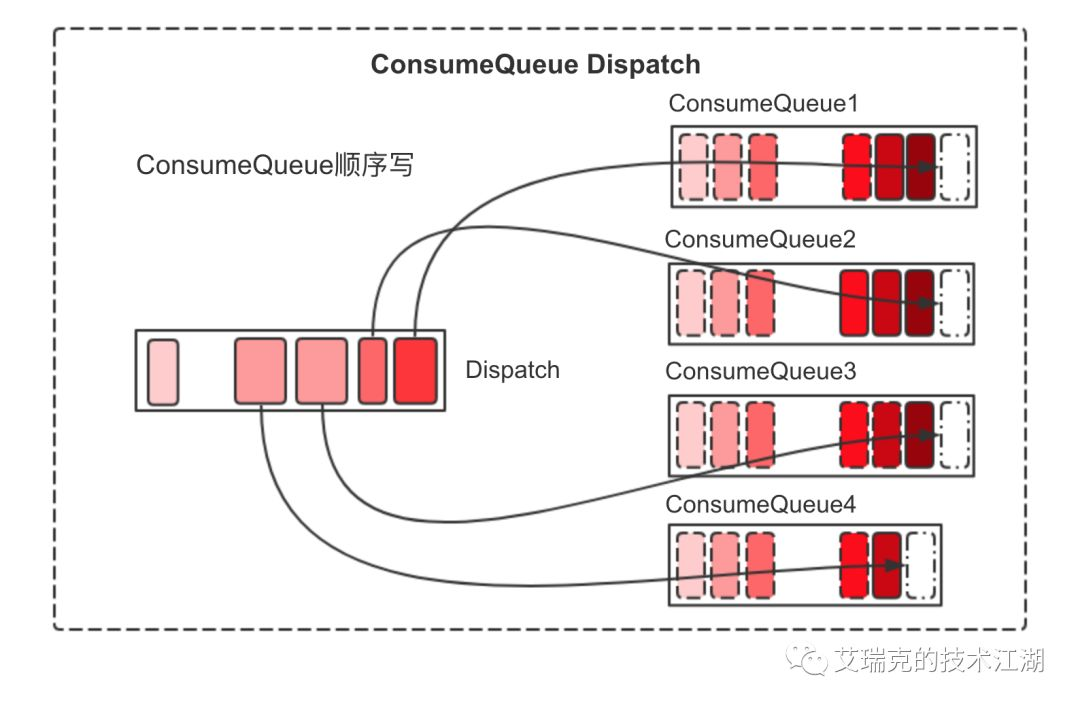
图片:Consume Queue顺序写
每一个Consume Queue代表一个逻辑队列,是由ReputMessageService在单个Thread Loop中Append,如上图所示,每一个Consume Queue显然也是从左往右高效顺序写。
(5) RMQ消费消息
消费时,Consumer不直接与Commit Log打交道,而是从Consume Queue中去拉取数据
 图片:Consume
Queue顺序读
图片:Consume
Queue顺序读
如上图所示,拉取的顺序从旧到新,每一个Consume Queue都是顺序读。
光拉取Consume Queue是没有消息真实内容的,但是里面有对Commit Log的偏移值引用,所以再次映射到Commit Log获取真实消息数据。
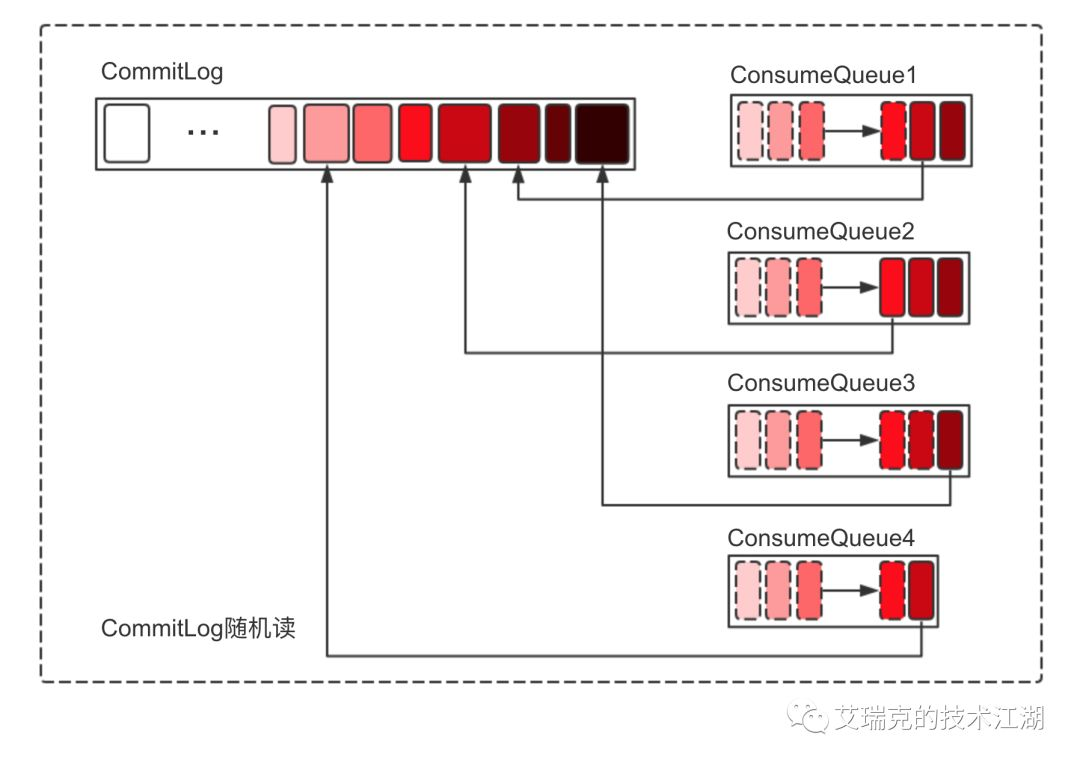
图片:Commit Log随机读
问题出现了,从上图可以看到,Commit Log会进行随机读。
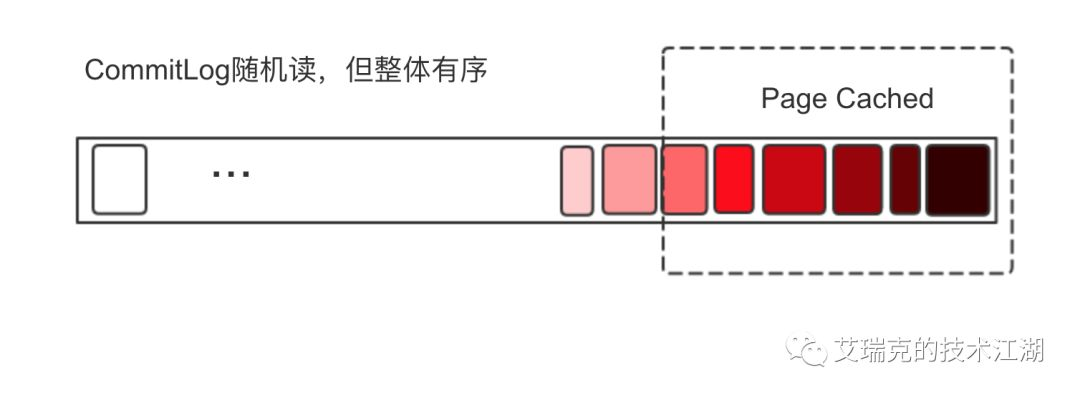
图片:Commit Log整体有序随机读
虽然是随机读,但整体还是从旧到新有序读,只要随机的那块区域还在Page Cache的热点范围内,还是可以充分利用Page Cache。
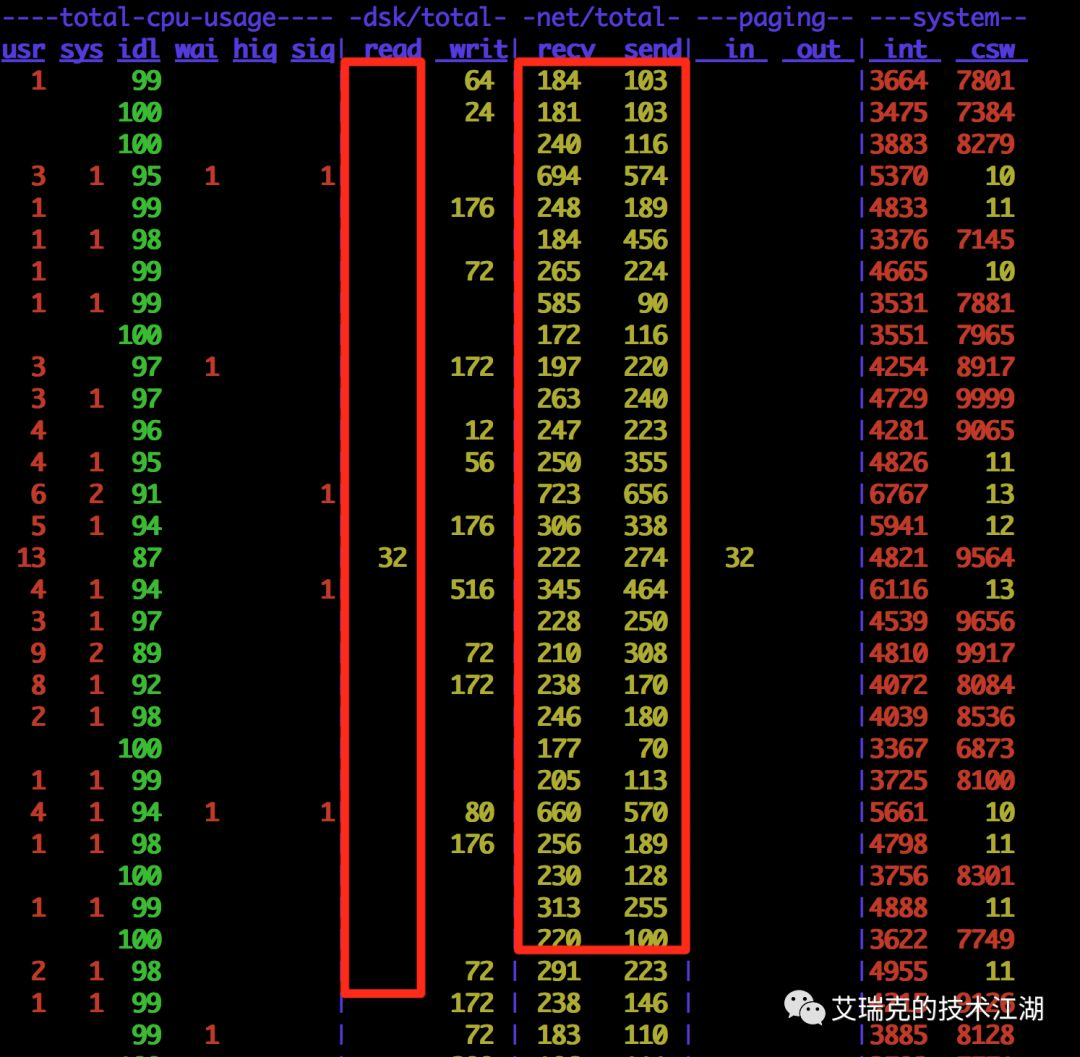
图片:运行中的RMQ磁盘与网络情况
在一台真实的MQ上查看网络和磁盘,即使消息端一直从MQ读取消息,也几乎看不到RMQ进程从磁盘read数据,数据直接从Page Cache经由Socket发送给了Consumer。
(6) 对比Kafka
文章开头就说到,RMQ是借鉴了Kafka的想法,同时也打破了Kafka在底层存储的设计。
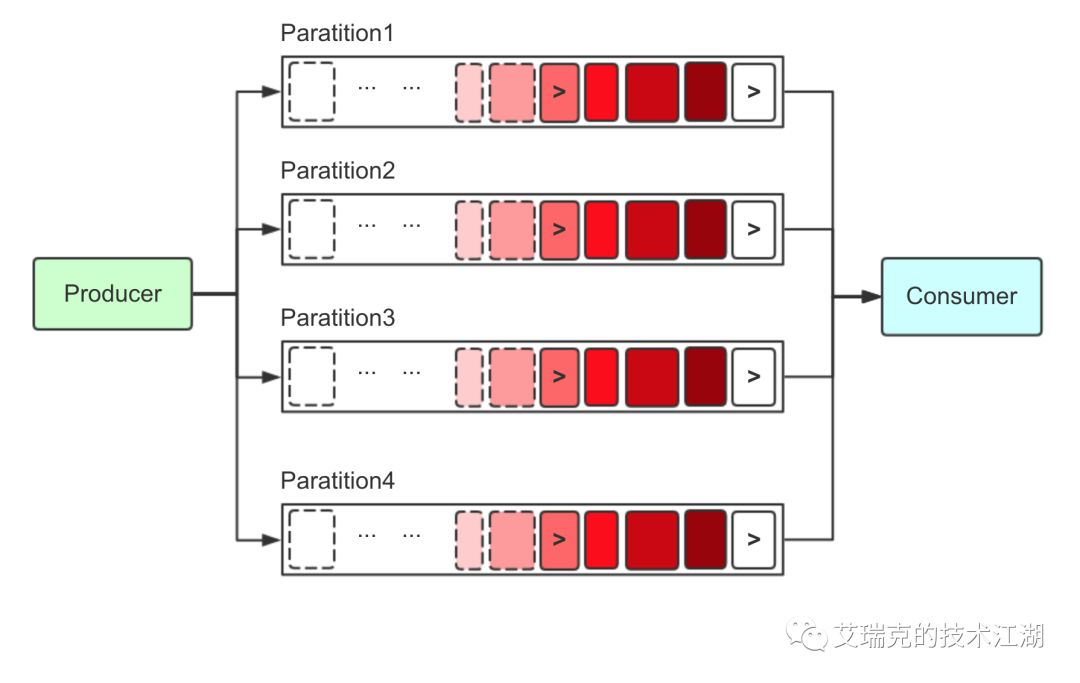
图片:Kafka分区模型
Kafka中关于消息的存储只有一种文件,叫做Partition(同一个Partition的多个Segment按一个Partition讨论),它履行了RMQ中Commit Log和Consume Queue公共的职责,即它在逻辑上进行拆分存,以提高消费并行度,又在内部存储了真实的消息内容。
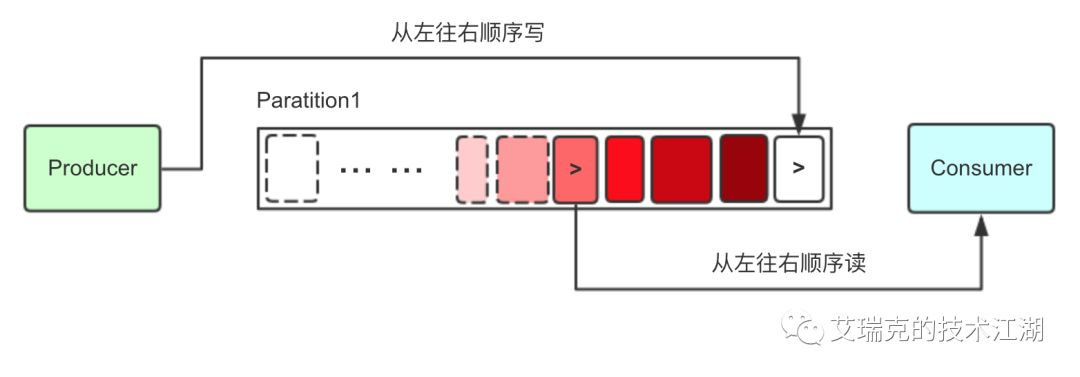
图片:Partition顺序读写
这样看上去非常完美,不管对于Producer还是Consumer,单个Partition文件在正常的发送和消费逻辑中都是顺序IO,充分利用Page Cache带来的巨大性能提升,但是,万一Topic很多,每个Topic又分了N个Partition,这时对于OS来说,这么多文件的顺序读写在并发时变成了整体随机读写。
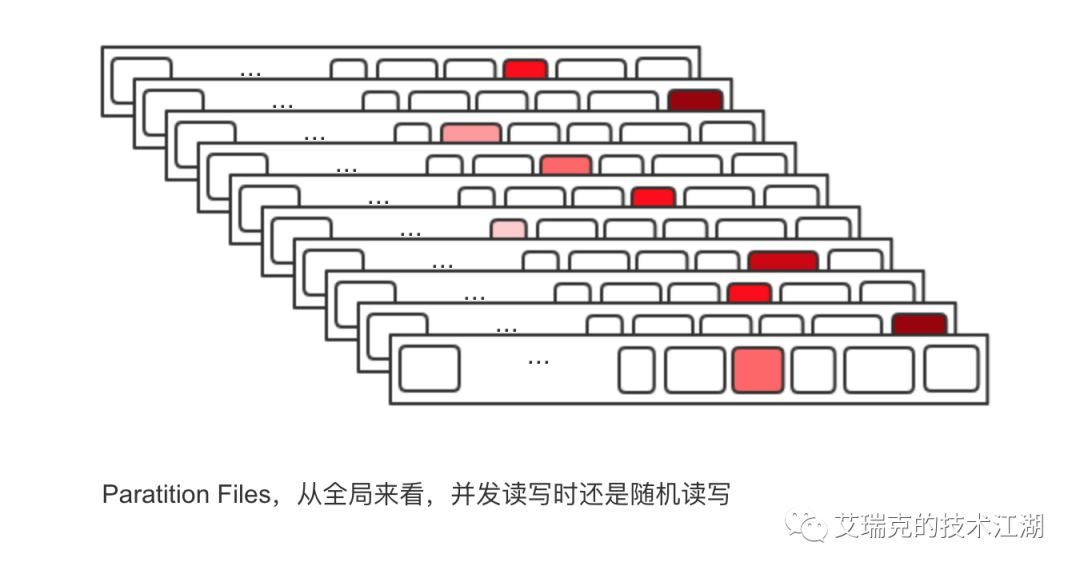
图片:Kafka Partition随机读写情况
突然想起了「打地鼠」这款游戏。对于每一个洞,我打的地鼠总是有顺序的,但是,万一有10000个洞,只有你一个人去打,无数只地鼠有先有后的出入于每个洞,这时终究还是随机去打,同学们脑补下这场景。
(7) 总结
不管是RMQ还是Kafka,基本的原理都是类似的
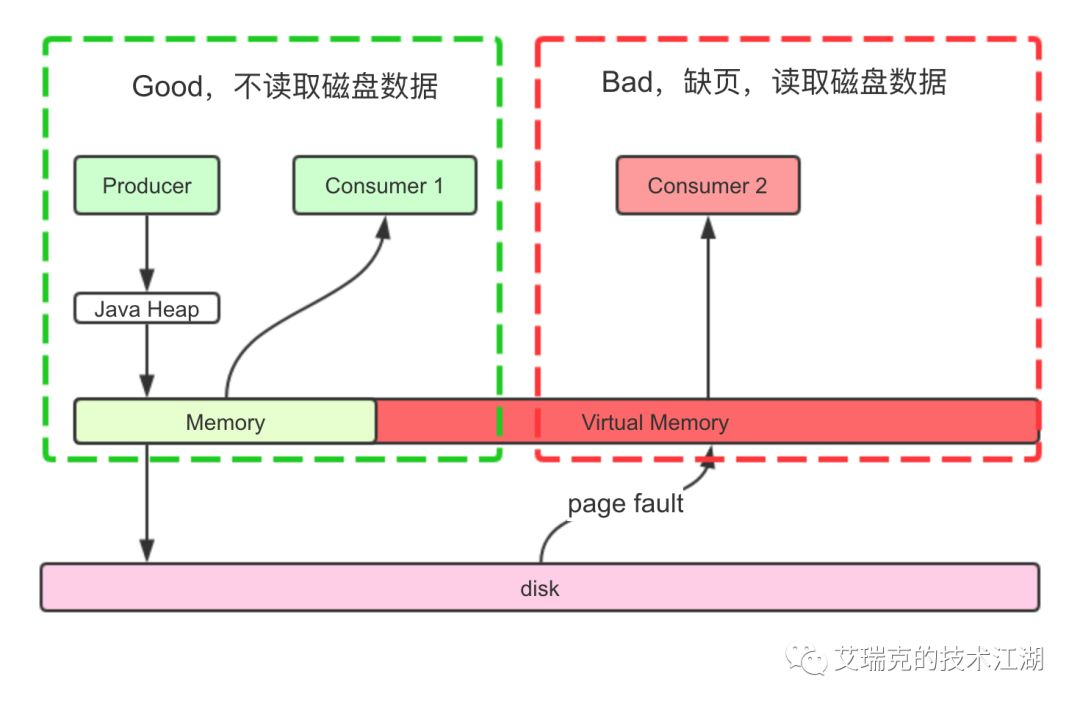
图片:RMQ消费场景对性能的影响
总结下来就是,发送消息时,消息要写进Page Cache而不是直接写磁盘,依赖异步线程刷盘;接收消息时,消息从Page Cache直接获取而不是缺页从磁盘读取,并且Cache本身就由内核管理,不需要从程序到内核的数据Copy,直接通过Socket传输。
说在后面
公号由于篇幅太长会影响阅读体验,可以点击阅读原文,我在简书上有对这个主题更加丰富的讨论。
各位同学应该已经慢慢开始熟悉我公号文章的风格了,自己画的图很多,源码贴得比较少。之所以自己画图,一方面是大部分的图内容是我原创的,网络上没有,即使是小部分在网络上可以看到的,也因为字体或尺寸不合适放公号阅读而被我重画。希望不管在移动环境或者在PC上,我的文章给阅读的同学带来比较好的体验。
目前微信对新开的公号都没有开放评论功能,可以直接在公号内给我留言。如果喜欢本文,请收藏后点个赞,咱们江湖再见。

