

今年深度学习和人工智能的发展, 一直以视觉为主线, 自然语言为侧翼, 而有一个十分基本但很少人提及的问题, 就是导航。 因为即使阿法狗可以打败李世石,机器靠自己的知觉来在一个空间寻找目标, 依然是比较困难的。
我们在深度学习的早期, 就知道, 越是人类看起来像空气一样存在的认知功能, 对于机器时间反而艰难, 比如之前的视觉, 这个问题远比让机器做计算,下象棋要困难, 也仅仅在2012年后得到突破。 空间里的探索和导航(当然还有更困难的意识和动机的产生等,在我们对知觉和运动都没搞清楚得情况,那些就更难了)是另一个例子。 我们司空见惯的空间概念由于已经刻画在我们的头脑里了, 所以我们不再觉得这件事情的非同寻常。 而一旦你闭上眼睛在屋子走一走,比如去找厕所, 你就会发现它是多么的不容易。
当然导航在高科技根本算不上人工智能问题,如果你有gps一切都只是一个路径规划问题。 但是没有, 问题就不再简单了,你想想古人类花了多少时间才走出非洲,走到世界?
这, 也就是我们今天的主题,在没有gps的情况下,如何让人工智能体同通过感知和行为,形成对空间的认知,然后达到目的地。
一 , 师法自然, 动物是如何导航的
我们围绕感知和运动来谈导航问题, 你要先有感知外界环境信号的能力才谈的上空间探索, 视觉当然是第一位的,但是其它的感知比如听觉, 磁场等也等可以作为好的信号。例如鱼类利于太阳感知,鸽子利用地磁场, 蜜蜂利用偏振光。 无论哪一点,空间的认识都是从感知作为起点。你就拿你自己为例, 你要去学校食堂, 其实基本上就是看到教学楼往右拐, 操场往左拐, 仅此而已, 这里的关键, 就是看。
除了看 ,第二个要素就是知道自己的运动, 动物需要知道自己在往哪里走, 走了多远, 而不能像喝酒的醉汉一样四处乱走而不知道走到了哪里。比如当你自己看导航去找目标, 你会看到前进300米往右, 500米往左这种, 那你能够完成这个过程 , 首先是要能够感知自己的运动, 知道自己在往哪个方向走,.
那么导航的第二个基础, 就是自己开始觉察到自己的运动,并且相对的度量它, 这里就自然包含了记忆,说白了就是得知道自己大概走了多远, 没有这个要素, 你是不能知道自己其实是向东走了500步.
这两个要素紧密结合, 你知道自己走了多少步, 并且感知到周围环境的变化, 把这个步数和相应的物体联系在一起, 你就可以得到一个概念, 那就是学校操场往右多少步是食堂, 往左多少步是教学楼, 这就好比一个心中的地图了。
这些要素就像机器学习所说的空间探索的基础元素, 而那个地图就是空间探索的高级特征。 就像像素是图像数据的基础元素, CNN从基础的像素里提取出构成图像的更有代表性的下一级特征,如纹理, 物体的不同性质的部分。 而此处,神经网络的挑战是从刚刚讲的感知和行为里提取出和空间有关的基础特征- 并构成某种程度一个虚拟和地图.
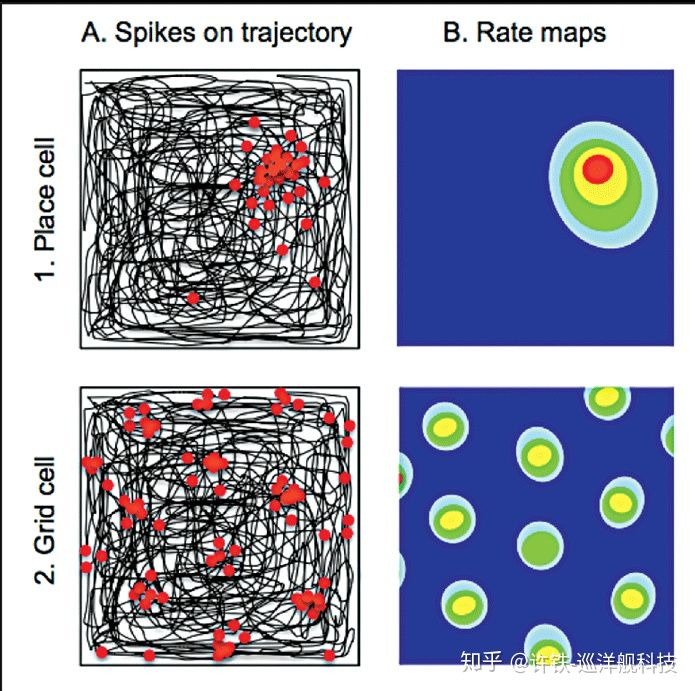
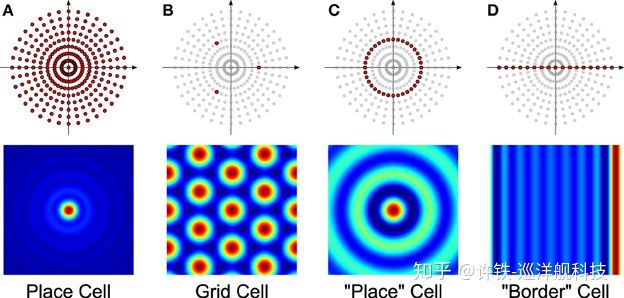
看看生物神经网络是怎么做的, 科学家一直觉得这个虚拟的地图应该存在在生物神经网络之中,还就真的发现了在小鼠海马体及其周边组织, 存在一组叫做place cell的细胞群,这个东西简直就是一个地图, 小鼠走到哪里, 就有一个对应那个位置的细胞(及其周边细胞)开始fire。神经科学家任务这个虚拟的大脑地图是小鼠能够在迷宫里不至迷惑的关键了。

这还不是全部, 神经科学家接着在这组细胞的上游(输入端)发现了一组叫做grid cell的细胞,中文名译作栅格细胞。 什么叫栅格细胞? 我们通常用感受野来描述细胞的发放, 也就针对不同的信号输入的每个细胞的平均放电率(衡量细胞的敏感性)。 这里的不同信号就是位置, 科学家发现: 栅格细胞的感受野所呈现的形状是一种类似与六边形栅格的结构,它们不像placecell那样仅仅对一个地点放电,而是对空间里周期性排布的位置进行放电,犹如一张展开的六边形网络。 可以说具有非常明显的空间周期性。(也就是说当你在一个空间里行走,某个细胞会依次在你往特定方向行走了特定距离后开始放电)。 整个栅格细胞层里的细胞每一个细胞都具有不同的空间周期性(边长不同), 但是排布的形状都是六边形 。 而且这样的空间周期很稳定, 即使小鼠在一个黑暗的环境里 ,这层栅格细胞也可以准确的反应, 而当换到一个新的环境以后, 它又会根据新的环境产生新的感受野, 虽然每个细胞对应的位置变了, 但是栅格的整体形状不变 。 不同的栅格细胞对应不同周期的栅格, 整个栅格网络层就成为一个具有很多不同周期的六边形网络的集合。
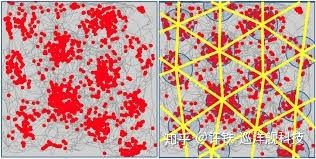
这个栅格细胞说的是每个细胞只对特定的空间位置敏感,把这些敏感位置组合起来(红色点),形成一个六边形的网状结构。
一个需要验证的科学假设, 就是这组神秘的栅格网络, 正是构成由place cell“位置” 这个高层概念的基底(底层特征), 如同图像物体这样的高级特征是由边角轮廓这样的底层特征构成是相似的。 事实上这一点是有着强大的物理基础的。 我们可以对空间域信号进行和时间域信号类似的傅里叶分解, 那么一个对空间某个固定位置敏感的细胞(place cell)分解之后正好得到一个个不同频率的周期栅格 (详情看傅里叶分解), 反过来,就是把不同频率的傅里叶级数(grid cell)加和起来就可以得到一个定点的信号。
为什么要这么麻烦? 你不是表示一个位置就得了吗? 还要一个六边形? 这里得关键是我们得位置细胞不仅要对一个环境中的特定位置编码, 更要对所有可能环境中的位置编码。 比如说你的某个细胞既要能表达北京王府井又要表示上海东方明珠。 这样我们就需要一个强大有效的特征表示, 可以很快的对新的环境空间重新进行位置编码, grid cell 构成的六边形基地正是这个表示, 某种程度,它们代表了空间的基础性质, 是从完全真实空间里抽象来的.
这个原理其实有点像量子力学里, 任何具有特定位置的质点都可以看作不同周期的波函数叠加而来, 这些波一组基底。 此处, 冥冥之中,量子力学和神经科学在握手。
二.,关于deepmind的那个人工智能体
好了 , 我们来说说AI吧, 关于deepmind这次做成的人工智能体,其实故事没有那么精彩, 因为它无非是之前建立好的神经导航模块上加入了这个类似动物的栅格细胞群落, 然后得到了更好的导航性能。
如果要你来设计这样一个人工智能体, 你会如何做呢?
对了, 设计一个虚拟的大脑 – 神经网络, 让他做和生物类似的处理, 刚刚讲的探索的两个要素 - 视觉感知, 运动记忆, 要用我们的深度神经网络来综合在一起, 然后用强化学习来训练, 如同训练动物一样。
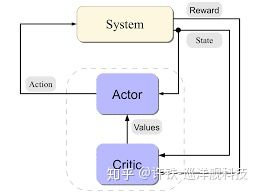
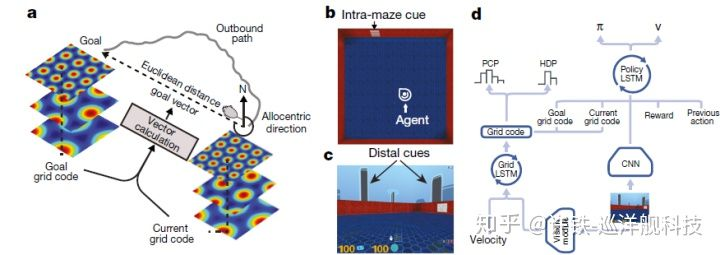
这个模型就是深度学习与极强悍的强化学习框架 – actor-critic的结合. 。 强化学习就是根据奖励学习, 这与训练小鼠在迷宫里行走得设定其实是相似的, 你要得到隐藏在空间某个角落里的奶酪, 就是学习空间导航。 强化学习就要有状态(观测),行为,策略,奖励。从观测到行为的过程是由人工智能体配备的人工神经网络完成的, 也就是这个虚拟生物的神经中枢。 它根据行为体对四周的观测(视野内的物体),得到一个决策行为(速度),比如向北走50米这种。这个神经网络一开始只知道进行随机游走,而只有在规定时间达到目标的时候它才会得到奖励, 通过强化学习的过程, 它可以学习到在空间里综合各种感知和运动信息的正确行为的方法。
这个方法被称为actor-critic, 是深度强化学习里一种非常强大的方法,所谓的actor- 行为者, 指的是一个产生人工智能体行为的神经网络, 它不停的对每个时刻所观测到的信息得到最优的行为(概率表示),而这个行为, 要被另一个神经网络- 所谓的critic检验, critic评估每个行为最终可能得到的收益,好比一个批评家。 并根据每一步骤下奖励的情况调整这个收益的估计(TD学习)。 两者结合起来, actor不停的大胆提可能的最优行为, 然后critic不停的指出这个行为到底是好是坏,两者的一个动态博弈将导致行为越来越优化, 这个方法可谓结合了强化学习两大分支策略梯度和态函数的重大优势。当你的行为产生一个后果(奖励或惩罚), 行动者actor和批评者critic都会被改进。 比如当某一次人工智能体成功得到了奖励, 行为者会直接提高中间所有行动的权值, 而评估者会提高中中级过程那些动作的评估分数, 这些最终都体现在神经网络权重的更新上.
所谓的深度强化学习, 是除了训练方法外, 神经网络的基础都是深度学习的基础工具. 我们所强调的空间导航的第一要素视觉, 它看到周围的环境, 这个图像由CNN卷积网络解决, 它得到的图像特征, 和人工智能运动的速度一起, 输入到下一个网络. 这就是我刚刚描述的导航需要视觉和运动两方面信息综合的思想. 大家能否猜到这个网络究竟是何物呢? 它就是用于自然语言处理的利器 - 时序神经网络RNN。 RNN具有记忆功能, 因此它满足我们刚说的导航第二要素 - 运动记忆。 我们在此处使用了RNN的加强版 – LSTM 了. LSTM一方面收集运动的速度, 一方面收集由CNN传过来的感知信号.
如此, 是否我们的”虚拟老鼠” 可以像真的老鼠一样走迷宫呢? 答案是否定的, 单纯的强化学习能够让agent进行空间探索, 但是其行为确显得有点笨拙, 比如说如果空间里出现了一条新的捷径到达目标, 它是比较难使用这样的信号的.
而让这个笨拙变得聪明的最关键一步, 也是deepmind新论文的亮点,是加入了类似于海马栅格细胞这样的空间表示,最终得到了十分类似真实动物走迷宫的那种能力。 这就真的是在师法自然了。
但是这个装配动物栅格细胞的过程可不是直接复制粘贴就可以, 我们依然用学习的方法, 把普通的神经网络训练成栅格网络. 这个想法也是十分合理的, 如果栅格网络这个东西是生物导航的依靠, 那么它很可能从空间预测有关的学习里自发的演化出来. Deepmind 设定了这样一个任务, 就是让人工智能的虚拟生物不停的在迷宫里行走, 但这次它不需要寻找奖励, 而是直接预测它自己所在的位置, 这个预测工作同样是由主管时序记忆的神经网络– LSTM + 一层普通的前向网络构成的, 这个LSTM的输入是每一时刻人工智能体的速度, 然后最终由前向网络输出当下的位置. 明眼人一下子就看出来这实际需要的就是个路径积分啊, 你需要把每个时刻的速度加和在一起,就得到新的位置. 在这个任务之上, 这个前向网络居然演化出了和自然界的grid cell(栅格细胞)真假难辨的感受野。
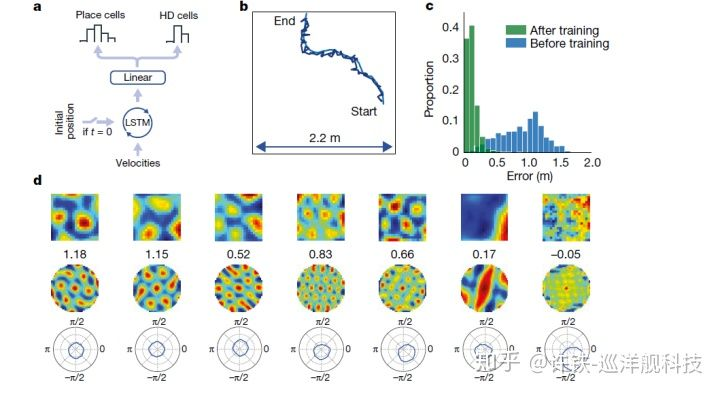
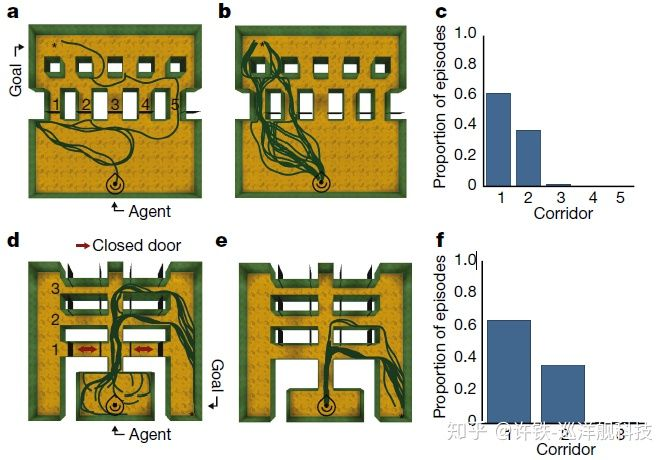
加入grid之后的人工智能再多方面都显得更为聪明, 一个很有意思的行为现象是, 装配了空间表示的人工智能体可以很好的利用空间里的“捷径” , 就如同人类可以通过走小路来抄近路,这个现象证明了人工智能体具有某种对空间的“理解“。 这个抄小路的能力, 就有点像导航界的图灵测试。
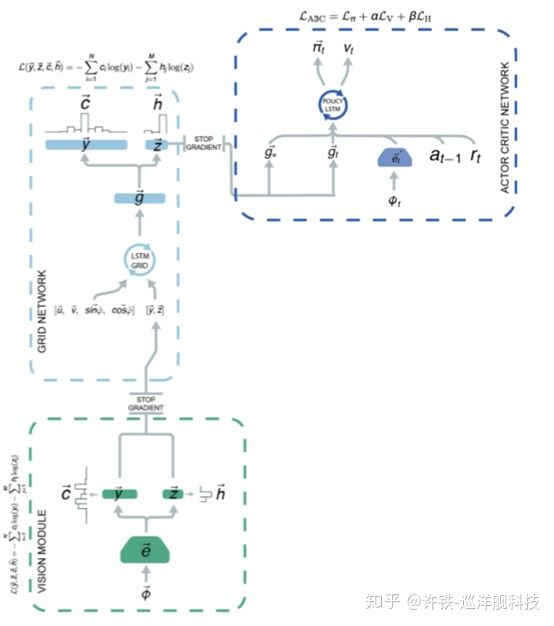
此处我们就可以把整个任务的流程图拉出来了, 视觉由CNN承担, 然后, 栅格细胞组的LSTM负责接收速度, 得是包含位置信息的神经编码,再和之前说的另一个LSTM, 那个决定下一步速度的决策中枢(actor-critic), 结合在一起, 这就是整个过程。
这篇文章的精彩处在于我们利用监督学习得到了和生物真实使用类似的关键特征, 然后在用一个深度强化学习得到正确的行为, 可谓把认知和决策完美结合了起来.
整个流程可以牛逼哄哄的被一个端对端的计算图表达.
虽然被吹的玄乎其玄, 我们其实就是在做一个空间运动有关的特征工程, 所谓对位置信息恰当的神经编码, 给决策网络来使用, 这样, 无论这个agent到了什么样的环境里 ,它都可以利用它学到的这个绝技, 来对陌生的空间进行定位和学习,适应那些环境的新变化, 利用捷径等.
这样的一门技术在现实的应用之大是显然的, 比如所有的机器人运动控制问题. 而这个方法也启示我们, 那些辛苦神经生物博士所做的看起来用处不大的研究里, 对人工智能的启发可以多么巨大。
