

1 引言
CoRL (Conference on Robot Learning) 是去年才成立的机器人学习顶级会议,今年是第二届,会议主页是:
http://www.robot-learning.org/www.robot-learning.org这届会议收录了70多篇paper,其中包含了多篇机械臂相关的paper。在这篇Blog中,我们就来一起赏析一下这些paper,看看Robotic Manipulation/Grasping的最前沿到哪了。
2 Paper List
[1] Grasp2Vec: Learning Object Representations from Self-Supervised Grasping
[2] Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects
[3] Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation
[4] Reinforcement Learning of Active Vision for Manipulating Objects under Occlusions
[5] Qt-opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
[6] Sim-to-Real Reinforcement Learning for Deformable Object Manipulation
[7] Task-Embedded Control Networks for Few-Shot Imitation Learning
[8] SURREAL: Open-Source Reinforcement Learning Framework and Robot Manipulation Benchmark
[9] ROBOTURK: A Crowdsourcing Platform for Robotic Skill Learning through Imitation
3 Grasp2Vec: Learning Object Representations from Self-Supervised Grasping
这篇paper来自Google Brain和UC Berkerley的Sergey Levine团队。
https://sites.google.com/site/grasp2vec/sites.google.com这篇paper的任务是goal-conditioned grasping,也就是给机械臂一个物体的图作为goal,机械臂就要能抓取对应的物体。先抛开这篇paper的方法论不谈,单单从这个问题入手,其实我们有很直接的处理方法:
1)先对物体进行检测,把每个物体给框出来
2)根据goal的图片进行匹配,找到对应物体
3)根据输入的物体特征信息,训练机械臂抓取该物体
但是这种做法存在的麻烦之处就是需要大量的人工标注,非常的费时费力,采用现成的物体检测算法虽然也能做,但毕竟不是针对场景,肯定也有偏差。所以,这篇paper主要考虑的事情是有没有办法通过自监督的方式来学习这个物体的表征信息,从而有利于抓取。
那么想法可以说是很简单了:框里面也就是那么多物体,我们拿走一个,就少一个,我们就可以利用这种变化来实现自监督的表征学习representation learning:
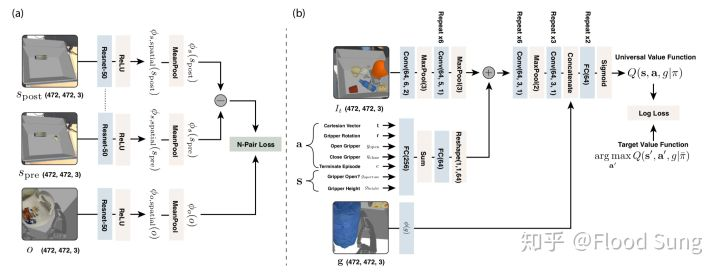
为了构造这个自监督的loss,作者做了一个很有意思的假设:

也就是抓取前的观察图像特征减去抓取后的图像特征正好等于机械臂夹取的物体特征。这是一个看起来不完全有道理的假设,但是实验证明这样做是ok的。
我们可以看到,这样做自监督学习就没有太多的标注成本了,只要反复做实验来获取数据就可以了。
训练完之后,作者通过heatmap给我们展示了自监督的效果,直接实现了物体检测加匹配所达到的定位效果:

基于这样的特征提取能力,后续就是采用一般的Q learning来训练了。
一点评价:
1)idea 创新度:⭐️⭐️⭐️⭐
2)实用价值:⭐️⭐️⭐️ 能够很大程度上减少人工打标签的工作,但是考虑到貌似人工标注数据也不是很贵,或许我们就人工打标签可以取得更好的效果
3)复现难度:⭐️ 非常难
我们知道,Google brain有一个机器人农场,所以它家出品的paper要复现是极其困难的,根本没有同等条件,至多在仿真上可以做一做。
4 Dense Object Nets: Learning Dense Visual Object Descriptors By and For Robotic Manipulation
这篇paper来自MIT,和上一篇paper的研究侧重点是一样的,都是关注物体的表征学习,但是这篇paper比上一篇更强,并且拿到了本届CoRL的best paper award,在之前就有相关媒体报道,还放出了代码。那我们这就来看看这篇paper有什么过人之处吧。
RobotLocomotion/pytorch-dense-correspondencegithub.com
下面我们来具体的看看方法论。
这篇paper的核心idea是去构建一个像素级别的图像描述,也就是Dense Visual Object Descriptor。有了这个图像描述,不管摄像头看到的图像角度如何变化,甚至物体本身如何变形,都能保持描述的不变性。有了这个基础,就可以利用其来做物体的抓取。
那怎么做呢?
作者用ResNet构造一个Dense Object Net,输入图像维度是WxHx3,输出维度是WxHxD,D就是每一个像素点对应的特征表达维度。为了说明这个D的意义,我们先来看这么用这个WxHxD,然后再来看怎么训练。
我们构造一个距离来计算两个图片不同像素点之前的特征差距,也就是正常的L2 distance:
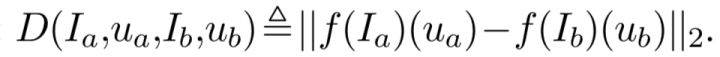
这里的f()即Dense Object Net,而f(I)(u)就是像素u对应的特征1x1xD。
由此,比如我们要实现特定位置抓取,也就是用户指定一个位置比如鞋后跟,然后机械臂就要从鞋后跟进行抓取。这个时候,我们可以把用户指定的图片位置的像素的特征与当前机械臂实时看到的图像的特征进行比较,找到距离D最小的像素位置,即认为是对应的鞋后跟位置。这就是Dense Object Descriptor的直接价值体现,可以实现超精准的定位,上一篇paper是做不到的。
那么怎么来训练这个Dense Object Net?
采用的思想比较简单,称为self-supervised pixelwise contrastive loss.也就是我们对同一个物体的两张不同图片寻找出对应的匹配点和不匹配点,让匹配点matches距离最小,不匹配点non-matches距离最大。
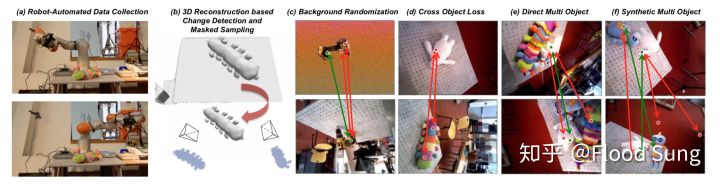
但是为了得到这些匹配点和不匹配点,我们就需要派上RGBD摄像头,先对物体进行一个三维重建,然后基于三维重建的物体来寻找这些点。这里的计算成本会比较大一些,所以要构造一个物体描述,需要先让机械臂绕着物体看一圈。这本身又是另外一个技术了,当然也比较成熟,所以在huawei mate 20 pro上也应用了。
然后这个方法很重要一点就是task-agnostic或者说generalization能力比较强,所以即使是新的物体甚至相同类的不同物体也可以区分。
一点评价:
1)idea 创新度:⭐️⭐️⭐️⭐⭐ 这个方法并不是直接构造点云point cloud数据,而还是针对2d图像构造对应的特征表达,很不一样,在像素级别上能够取得这样好的效果是有点难以置信的。
2)实用价值:⭐️⭐️⭐️⭐⭐ 一般基于深度学习的方法往往缺少精准度,我们只要求能把物体抓取来,至于怎么抓抓哪里都不要求的,但是这篇paper可以说给大家指出了一个很promising的方法,能够非常精准的定位。然后由于每一个物体都可以单独存一个特征描述,使得基于这个方法能够具备非常广泛的应用,所以价值是很高的。
3)复现难度:⭐️⭐️ 要完整复现整个流程还是比较困难的,从三维重建到获取匹配点到训练神经网络,需要较大的工程量。但是作者开源了后面的神经网络部分,也提供了匹配点的数据集,可以说已经给大家很大的帮助了。
5 Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects
这篇paper依然延续了前两篇paper的主题,核心都是在视觉上。所以,我们由此可以明白,目前计算机视觉在机器人上的应用还有很多发展空间。

机械臂抓取的问题简单的可以直接分成两部分:视觉端和机械端。Google 比较偏向于End-to-End,但是往往我们把问题单独区分出来做会有更好的效果。而且这其中可能视觉端的问题会更重要一些,毕竟只要我们能够把物体区分定位出来,机械端的部分用传统控制方法也可以实现。也因此,我们才会看到这么多纯视觉的研究。
回到这篇paper上,思路又不一样了:使用合成的仿真数据来学习物体的姿态估计。

这么paper的核心贡献主要是在于photorealistic仿真图像的使用,说白了就是仿真程度更高,所以效果更好。至于神经网络的训练细节,我们这里就详细分析了。
1)idea 创新度:⭐️⭐️ 可能谈不上太多的创新,但是有效果就好。
2)实用价值:⭐️⭐️⭐️⭐⭐ 这篇的实用价值也是很高的,毕竟只要我们有无穷无尽的高度仿真数据,我们就不需要费尽心思来考虑怎么做自监督了
3)复现难度:⭐️⭐️⭐️⭐ 这篇文章算法上没有太大问题,主要是数据集。有数据,一切都好办。
6 Reinforcement Learning of Active Vision for Manipulating Objects under Occlusions
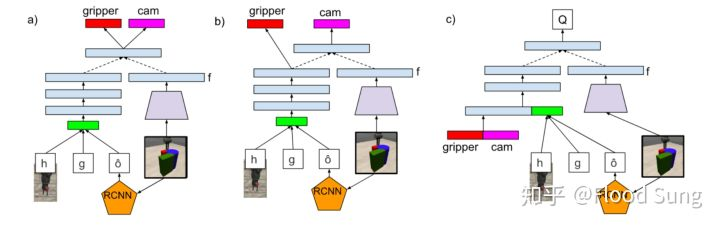
这篇paper和前面的研究方向不一样了。做research一种就是前面的积极研究大家都在考虑的问题,另一种就是构造新问题。在机器人学习领域,新问题非常容易创建出来。这篇paper就是一个例子。一般我们只研究机械臂动的情况,那么是不是摄像头也可以动呢?我们会想说这摄像头动有什么意义?有,比如在物体被遮挡的情况下。既然有意义,那就可以研究了。这种研究大抵是标准水文的套路,方法上实际上没太多创新,但是把问题稍微改改也就是创新了。另一种标准水文的套路则反过来,问题不变,方法论稍微改改。这篇paper在方法上使用标准的actor-critic,只是在输入输出上因为要控制摄像头和机械臂,做了点改动,这里就不详细分析了。
1)idea 创新度:⭐️⭐️
2)实用价值:⭐️⭐️⭐️
3)复现难度:⭐️⭐️⭐️⭐
7 Qt-opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
这篇paper获得了CoRL的Best Systems Paper Award,我们在之前的blog中已经有分析,这里就不再重新分析。
Flood Sung:闲谈机器人抓取的前沿到哪了?zhuanlan.zhihu.com
这篇paper之所以能引起关注不在于方法上有多创新,而是通过大规模的End-to-End训练使得抓取效果达到了非常高的水平。我们会考虑说为什么机械臂需要神经网络加持?采用传统控制有什么劣势?通过这篇paper我们可以看到使用神经网络可以学习到传统控制学习不到的控制策略,这就足够了。从长远看,End-to-End必然比非End-to-End的好。
1)idea 创新度:⭐️⭐️⭐️⭐️
2)实用价值:⭐️⭐️⭐️⭐️⭐️
3)复现难度:⭐️
8 Sim-to-Real Reinforcement Learning for Deformable Object Manipulation
这篇paper和Reinforcement Learning of Active Vision for Manipulating Objects under Occlusions类似,都是研究一个不一样的问题。这篇paper研究的是可变形物体的抓取,比如毛巾。
实现的效果还不错,采用ddpg的改进版本,包括了:
1)Prioritised Replay
2)N-Step returns
3) DDPGfD
4) Behavioural Cloning
4) Reset to demonstration
5) TD3
6) Asymmetric actor-critic
可以说基本上用上了Deepmind开发的最好的off-policy continuous control 的rl算法。
1)idea 创新度:⭐️⭐️
2)实用价值:⭐️⭐️⭐️
3)复现难度:⭐️⭐️⭐️⭐️
9 Task-Embedded Control Networks for Few-Shot Imitation Learning
这篇paper比较值得讲一讲,因为它研究了一个很重要的问题Few-Shot Imitation Learning。这个问题之前被Chelsea Finn的MAML刷了一波。但是MAML无法支撑大规模网络及不方便训练的问题非常bug,所以这篇paper算是把MAML的方法打了下去,关键是方法非常简单,采用基于deep metric learning的方法,对于每一个task构造一个embedding:
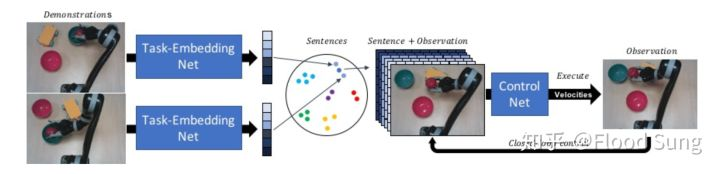
让不同task的embedding尽量分离,让相同task的embedding尽量靠近。同样的,demo只需要图像state数据,不需要对应的action数据。在我刚看到这篇paper的方法时,我是有疑问的,我的疑问在于如何输入一长串的demo数据到网络里面呢?
结果,这篇paper竟然仅使用demo开头和结束两帧的图像,想想这个Few-Shot Imitation Learning构造的task实在是太简单了,也就是把一个物体放到一个碗里面,改改物体的类型和碗的样式,至于中间怎么抓取根本无所谓。所以与其说这是一个task,不如说是一个goal。实际上只是一个goal embedding,那就不涉及太多的imitation learning的问题了。
所以,很有意思的事情出现了:Few-Shot Imitation Learning目前的实验设计并不好。有必要设计更复杂的实验,至少需要让机器人观察demo的中间过程才能完成。要不然谈不上imitation了。
1)idea 创新度:⭐️⭐️⭐️
2)实用价值:⭐️⭐️⭐️
3)复现难度:⭐️⭐️⭐️⭐️
总的来说,这篇paper最大的意义不在于说其效果打败了MAML,毕竟MAML在Few-Shot Learning是已经被虐成渣渣了,而在于说1)Few-Shot Learning的方法是有办法迁移到机器人的应用上的 2)这个问题还非常前沿,以至于实验设计过于简单,有很大的发展空间。
10 SURREAL: Open-Source Reinforcement Learning Framework and Robot Manipulation Benchmark
11 ROBOTURK: A Crowdsourcing Platform for Robotic Skill Learning through Imitation
最后两篇paper都出自Fei-Fei Li的研究,非常有她的特色,就是造平台。

实际上机器人学习问题确实很缺这样的benchmark。特别是这个ROBOTURK,大规模的收集imitation learning的数据,还采用了非常酷的方法,确实是很有意思。目前,Fei-Fei Li 也已经专门成立了机器人实验室,值得关注:
12 一点小结
以上基本上分析了目前Robotic Manipulation领域最前沿的paper,从中我们可以看到
1)目前研究的水准至少都是针对任意物体,而不是固定类型的物体。那么这一块有计算机视觉深度学习的加持,相信可以进一步提升。
2)研究平台正在改善,越来越多的大佬会进入到机器人学习的领域,毕竟这会是下一个爆点。目前比如Google Brain的研究甚至连复现所需的硬件条件都很难达到,就很难让大家一起搞了。
3)算法层面上面并没有大的改进,但是这并不影响效果的提升。目前平台的因素还很大层面上制约了算法的发挥。
总的来说这个领域的发展还是很让人兴奋的,也期待下一步的发展!
