

本系列的前文见我的专栏:
技术备忘录zhuanlan.zhihu.com
在本系列的 (2),介绍了一种极其简单的生成模型。
在本文中,我们先不考虑它的复杂化。我们考虑能不能更简单,简单的极限到底在哪里。
我的观点是,生成模型的奥秘,不在于什么“分布积分来积分去”,在于 Deep Image Prior:
Deep Image Priordmitryulyanov.github.io
Deep Image Prior 说的事情,从实验的角度看很简单。但是,从理论的角度看,比“分布的积分”复杂得多,所以还没见过有谁去理论分析。
大家都只在拼命算"分布的积分",不得要领。
在本文中我们做一些小实验。让我们看看生成模型的极限到底在哪里。
1. 生成模型到底可以有多简单?
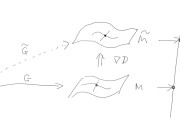
生成模型,最有趣的地方,在于从 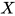 到
到 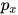 。
。
没有人说得清 是啥。即使给定了一批图像 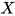 ,显然它们仍然可以来自几乎任何 。
,显然它们仍然可以来自几乎任何 。
但是我们可以加入 prior,然后就可以估计了。
卷积网络是一种极好的对于自然图像的 prior。这是 DL CV 的核心之核心所在。
考虑下列生成模型,不妨称为 DGN,Direct Generative Network:
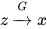
你没看错。它就长这样。啥都没有。
2. 训练最简单的生成模型
我说 G 是个生成模型。因为它首先可以保证几乎完美地生成每一个样本 X,一个都不拉下。
如此基本的要求,是目前的 GAN / VAE / Flow 系列甚至都不能保证的。现在的生成模型,问题太大了,连原始数据集都还原不了。
那么,DGN 怎么训练?例如两种方法:
- 最笨的方法。随机采样一批 z,然后我们硬性随机指定每个 z 对应哪个 x。没错,就是这么粗暴。
- 稍微聪明一点的方法,每次训练 G 后,也算一下 z 的梯度,让 z 也流动起来。
这里的 1,是不是让大家想起了 [1611.03530] Understanding deep learning requires rethinking generalization ?
没错,G 真的可以硬学会一切。我们等下看。
3. 所谓样本分布,到底是什么?
有人会问,你怎么知道 G 生成的分布符合那个神秘的 ?
例如,这样做 z 插值出来的图像,真实吗?随机生成的 z,真实吗?
那么,我问你,你告诉我 是啥?有啥评判标准?
- 如果你说 IS FID 之类,为何我们不干脆直接把这个加入训练过程,作为训练目标?
- 重新搞几个 D/E 之类,有啥意义?本质上还不是在做一样的事情,只不过可以满足"算积分发论文"的需求罢了。而且还很不稳定,整天崩掉,只能缝缝补补,我跟你说,补不完的。
- 是的,我跟你说,现在这种输出 1 个数字的 D,永远有漏洞,永远补不完。原因见我 1 年多前写的文章:
- 对于那种简单的 toy 数据集(例如那种一群gaussian排列的,大家都知道,论文里面喜欢用),可以补完漏洞,但没有任何意义。
- 如果你说 D 是无监督出来的,我们完全可以用更好的办法来做,例如直接做图像的精细模型(就像语言模型),这种模型,加的约束是非常高维的,因此解决了我在"几何图景"提出的问题。这无疑会比现在这些残废的 D 要普适得多,稳定得多,有意义得多。难道不是吗?
如果你希望改进 DGN,没有必要训练一个和某个特定 G 紧密耦合的 D。应该另训练一个普适的 D。
直接用 deep image prior 把样本分布估计出来,难道不是最简单,最合理,最准确的吗?做这么多花样,有什么意义呢?
4. 做点实验
台式机的 bug10 懒得修了,用笔记本跑吧。找了一个之前知友做的头像数据集,跑一下吧。网络架构就用最原始的 DCGAN 的 G,filter 为 512 / 256 / ...。
为了看看 DL 的死记硬背能力有多强,我们就用最笨的训练方法,连 shuffle 都不做,就挑一批头像,先随机采样生成固定的 z,然后每次按顺序训练 x。首先 z 也只取 50 维。
先挑 64 个试试。Batch 也 64(因此可以说一切都是最笨了)。优化器用 DCGAN 里面的 Adam,参数完全一样。
第 0 步:
第 100 步:

第 200 步:

第 500 步:

第 900 步:

除了有点噪点之外,和原数据集一模一样。网络成功记忆了一切。
请注意,这个甚至都不是 SGD,是 GD。再次证明了,足够大的网络根本就不在意什么"local minimum"问题。
那么。加点数据量。加到 5*64=320 张图片。Batch 仍然 64。还是不做 shuffle。
第 200 步:

第 900 步:

仍然几乎完美地还原所有图片。
再多样本也一样。越多样本学得越慢,也会慢慢没这么准确。至于怎么改善,大家也知道。总之确实很粗暴。
5. 思考
这里已经有很多值得思考的问题,我先把文章发出来,大家可以自己去实验和思考。
例如:
- 对于常见数据集,最好的 DGN 架构到底是什么?
- 对于不同数据集,正确的 z 维数怎么确定?理论上,其实 1 维的 z 就可以覆盖所有样本。当然,覆盖不了 。
- 加入 z 的流动后,得到的 z 会有意义吗?
- 可以生成合理的插值和新样本吗?加入前文提到的辅助网络后,效果又如何?
