

1. 简单回顾 MLE
让我们从最大似然估计(MLE)说起。
令样本为 ,我们希望用
模型拟合样本的分布。这里
是模型的参数。
若模型认为 的概率为
,且样本的采样为独立事件,那么,这样的模型参数
可最大化总概率:
这等价于:
若样本的实际分布是 ,那么上式最终是:
其中最大化的,无疑就是负交叉熵损失。
2. MLE 的问题,与 Bayes 估计
到此似乎是最基础的知识。但依我说,MLE 的优化目标,到此可能已经错了。
为什么?例如这种情况:
由于 MLE 只看最大概率,它可能走入一个深而窄的谷里面,这往往就是过拟合。很多文章也提到过,"平坦"的局部极小值,可能比全局最小值更好。
这里已经在暗中用了 Bayes 的观点。在 Bayes 观点下,简单的 MLE 就是错的。这里隐藏的先验分布和 有关。
那么,是否可以用类似下面的方法估计 (这是后验期望估计,是一种 Bayes 估计):
或者给出不同置信度下的 估计,等等?
但是,这样仍然有问题。例如下面的情况下,就容易会去对两个谷对应的 取平均,那么得到的会是很差的参数。
可以做得更精细一些,例如考虑 的稳定性等等。但总而言之,这里的问题是
的"正确" metric / 分布并不明确。
所以我们最好再用一个网络去学 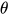 的情况。现在的很多生成模型就有这样的意思,后续再讨论。
的情况。现在的很多生成模型就有这样的意思,后续再讨论。
3. 生成模型
样本 并非随机,它来自于物理过程。之前在这篇文章介绍过一些类似的话题:
令样本的“物理生成模型”为 ,生成过程大致是这样:
根据 采样一个
-维的编码
,送入生成模型,生成样本
。
那么,经典的问题是,这样得到的样本分布 是怎样的?
如果 可逆可导(此时
),答案是:
这时我们有几点观察:
- 其实,对于普通的采用 +/-/*/ReLU 的深度网络,即使
,也可以算出来
。这个稍后看看是否算一下。
- 可逆的生成模型
有很多好的性质(例如编码也很简单),但这时
的空间非常大,因为需要
。关于此,OpenAI 做过值得一读的研究,其中的思路很明确,降低计算 Jacobian 的计算量,同时在损失函数中要求维数尽可能坍塌:
Glow: Better Reversible Generative Models
Glow: Better Reversible Generative Modelsblog.openai.com- 更进一步的问题,是生成网络
对
的拟合过程。我的一点感觉,常用的转置卷积在此是有问题的,配合 attention 后有改善,但还是有问题。
- 我们需要多思考自己的
到底在生成什么(例如从前 CoordConv 的研究方法),而不是盲目地只看训练和测试效果。
- 其实d=k有它的道理!因为大部分编码对应噪音,我们需要噪音,因为图像本来就有噪音,没有噪音就模糊。这个问题我们后续继续谈,我有一个办法可以解决这种维数的诅咒!
