


本文经作者张文娟授权发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
概述
随着容器技术的发展,容器服务已经成为行业主流,然而想要在生产环境中成功部署和操作容器,关键还是容器编排技术。市场上有各种各样的容器编排工具,如Docker原生的Swarm、Mesos、kubernetes等,其中Google开发的kubernetes因为业界各大巨头的加入和开源社区的全力支撑,成为了容器编排的首选。
简单来讲,kubernetes是容器集群管理系统,为容器化的应用提供资源调度、部署运行、滚动升级、扩容缩容等功能。容器集群管理给业务带来了便利,但是随着业务的不断增长,应用数量可能会发生爆发式的增长。那在这种情况下,kubernetes能否快速地完成扩容、扩容到大规模时kubernetes管理能力是否稳定成了挑战。
因此,结合近期对社区kubernetes性能测试的调研和我们平时进行的k8s性能测试实践,和大家探讨下kubernetes性能测试的一些要点,不足之处还望大家多多指正!
测试目的
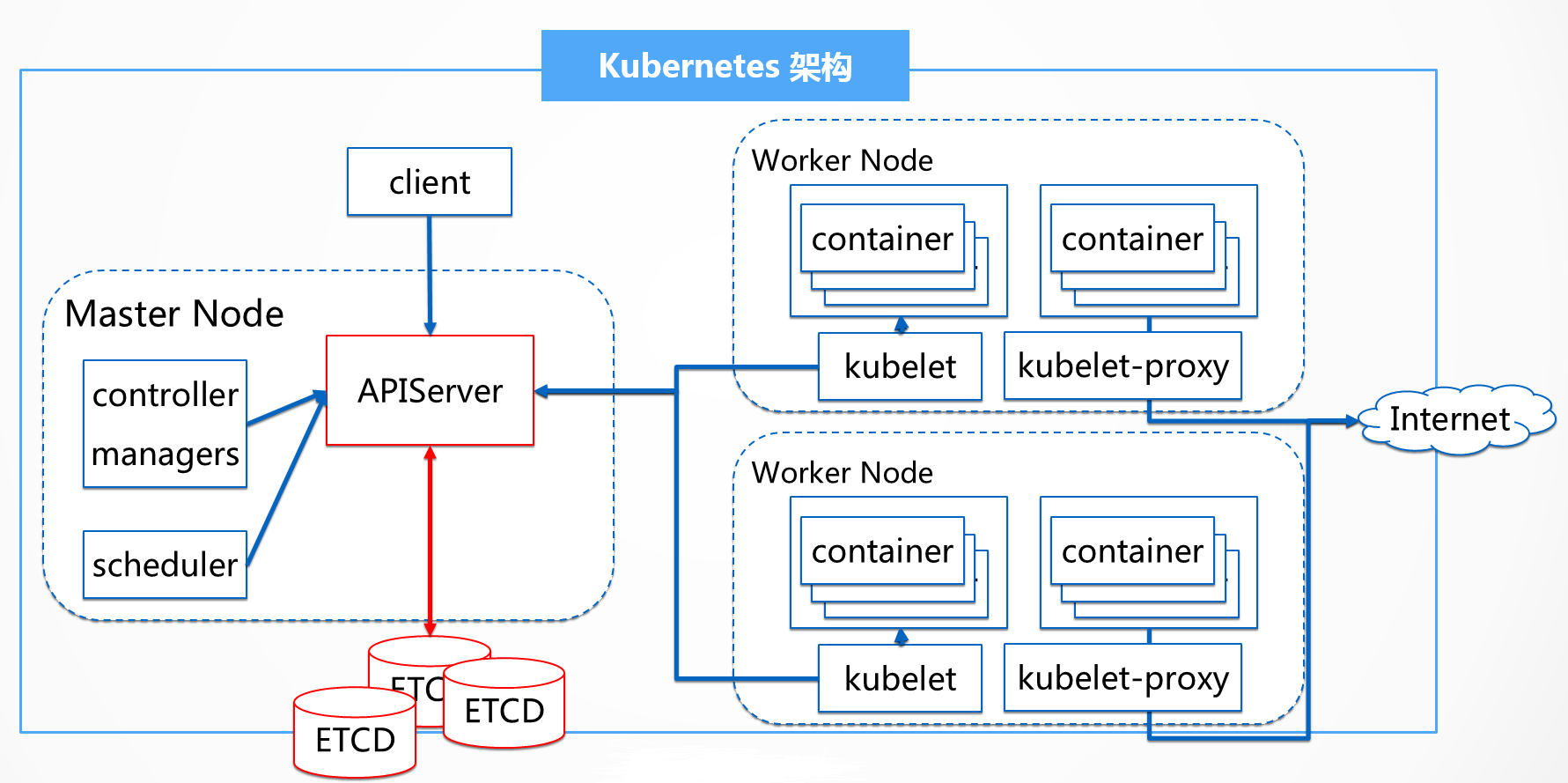
如上kubernetes架构图所示,无论外部客户端,还是kubernetes集群内部组件,其通信都需要经过kubernetes的apiserver,API的响应性决定着集群性能的好坏。
其次,对于外部客户而言,他只关注创建容器服务所用的时间,因此,pod的启动时间也是影响集群性能的另外一个因素。
目前,业内普遍采用的性能标准是:
API响应性:99%的API调用响应时间小于1s。
Pod启动时间:99%的pods(已经拉取好镜像)启动时间在5s以内。
“pod启动时间”包括了ReplicationController的创建,RC依次创建pod,调度器调度pod,Kubernetes为pod设置网络,启动容器,等待容器成功响应健康检查,并最终等待容器将其状态上报回API服务器,最后API服务器将pod的状态报告给正在监听中的客户端。
除此之外,网络吞吐量、镜像大小(需要拉取)都会影响kubernetes的整体性能。
测试要点
一、社区测试kubernetes性能的关键点
当集群资源使用率是X%(50%、90% 、99%等不同规模下)的时候,创建新的pod所需的时间(这种场景需要提前铺底,然后在铺底基础上用不同的并发梯度创建pod,测试pod创建耗时,评估集群性能)。在测试kubernetes新版本时,一般是以老版本稳定水位(node、pod等)铺底,然后梯度增加进行测试。
当集群使用率高于90%时,容器启动时延的增大(系统会经历一个异常的减速)还有etcd测试的线性性质和“模型建立”的因素。调优方法是:调研etcd新版本是否有解决该问题。
测试的过程中要找出集群的一个最高点,低于和高于这个阈值点,集群性能都不是最优的。
组件负载会消耗master节点的资源,资源消耗所产生的不稳定性和性能问题,会导致集群不可用。所以,在测试过程中要时刻关注资源情况。
客户端创建资源对象的格式 —— API服务对编码和解码JSON对象也需要花费大量的时间 —— 这也可以作为一个优化点。
二、网易容器服务k8s集群性能测试关键点总结
集群整体
不同的集群使用水位线(0%,50%, 90%)上,pod/deployment(rs 等资源)创建、扩缩容等核心操作的性能。可以通过预先创建出一批dp(副本数默认设置为3)来填充集群,达到预期的水位,即铺底。
不同水位对系统性能的影响——安全水位,极限水位
容器有无挂载数据盘对容器创建性能的影响。例如,挂载数据盘增加了kubelet挂载磁盘的耗时,会增加pod的启动时长。
测试kubernetes集群的性能时,重点关注在不同水位、不同并发数下,长时间执行压力测试时,系统的稳定性,包括:
系统性能表现,在较长时间范围内的变化趋势
系统资源使用情况,在较长时间范围内的变化趋势
各个服务组件的TPS、响应时间、错误率
内部模块间访问次数、耗时、错误率等内部性能数据
各个模块资源使用情况
各个服务端组件长时间运行时,是否出现进程意外退出、重启等情况
服务端日志是否有未知错误
系统日志是否报错。
apiserver
关注api的响应时间。数据写到etcd即可,然后根据情况关注异步操作是否真正执行完成。
关注apiserver缓存的存储设备对性能的影响。例如,master端节点的磁盘io。
流控对系统、系统性能的影响。
apiserver 日志中的错误响应码。
apiserver 重启恢复的时间。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
关注apiserver在压力测试情况下,响应时间和资源使用情况。
scheduler
压测scheduler处理能力
并发创建大量pod,测试各个pod被调度器调度的耗时(从Pod创建到其被bind到host)
不断加大新建的pod数量来增加调度器的负载
关注不同pod数量级下,调度器的平均耗时、最大时间、最大QPS(吞吐量)
2. scheduler 重启恢复的时间(从重启开始到重启后系统恢复稳定)。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
3. 关注scheduler日志中的错误信息。
controller
压测 deployment controller处理能力
并发创建大量rc(1.3 以后是deployment,单副本),测试各个deployment被空感知并创建对应rs的耗时
观察rs controller创建对应pod的耗时
扩容、缩容(缩容到0副本)的耗时
不断加大新建deployment的数,测试在不同deployment数量级下,控制器处理deployment的平均耗时、最大时间、最大QPS(吞吐量)和控制器负载等情况
2. controller 重启恢复的时间(从重启开始到重启后系统恢复稳定)。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
3. 关注controller日志中的错误信息。
kubelet
node心跳对系统性能的影响。
kubelet重启恢复的时间(从重启开始到重启后系统恢复稳定)。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。
关注kubelet日志中的错误信息。
etcd
关注etcd 的写入性能
写最大并发数
写入性能瓶颈,这个主要是定期持久化snapshot操作的性能
2. etcd 的存储设备对性能的影响。例如,写etcd的io。
3. watcher hub 数对k8s系统性能的影响。
网易云容器服务为用户提供了无服务器容器,让企业能够快速部署业务,轻松运维服务。容器服务支持弹性伸缩、垂直扩容、灰度升级、服务发现、服务编排、错误恢复及性能监测等功能。
相关文章:
【推荐】 一“脚”到位-淋漓尽致的自动化部署
【推荐】 MySQL Group Replication数据安全性保障
【推荐】 Hive中文注释乱码解决方案
