

博主在一开始学习数据科学时,没有人带路,没有一条直接的路径。因此各种信息都接收,一开始比较混乱,后来接触的多了,渐渐开始了解到关于数据科学无非分为 数学中的统计学、计算机中的 python 和机器学习算法、项目中对业务的理解三大块。在学习方法和知识获取上也多走了弯路,浪费了很多时间,现在将它们进行一遍梳理,多为根据自己的理解进行输出与再学习,如果对想探索数据科学的你有一点用,还请点击文末的赞与收藏,给个鼓励。
数据科学系统学习这个专题将从这三方面进行整理,下面进入正文。
关于数据科学的概述
数据分析首先是基于某个行业的,然后在这个基础上有一定目的性的去采集、处理、分析并解释数据,最后得出有一定价值信息的过程。
其中,行业需求最大的是金融/电商行业,对数据进行处理就需要用到统计方法,最后通过提取有价值的信息来改变业务决策,提高利润指标。
总的来说,用数据科学的知识来完成一个项目,需要进行数据分析和数据挖掘两步。
数据分析和数据挖掘的区别总结如下:

统计方法的分析方法分为:描述性统计方法,回归分析,对应分析,因子分析,方差分析等。 数据挖掘的分析方法分为:聚类分析,分类分析,关联规则,回归分析等。
关于统计学的应用
描述性分析就是从总体数据中提炼变量的主要信息,即统计量。这类分析只要明确分析的主题和可能的影响因素,确定可量化主题和影响因素的指标,根据这些指标的度量类型选择适用的统计表和图进行信息呈现。
由于统计推断的算法是根据分析变量的度量类型定制开发的,这就需要分析人员对各类指标的分布类型有所认识,合理选择算法。而深度学习算法是通用的,可以在一个框架下完成所有任务。在数据科学体系中,统计推断的算法往往是数据挖掘算法的基础,比如特征工程中大量使用统计推断算法进行特征创造与特征提取。
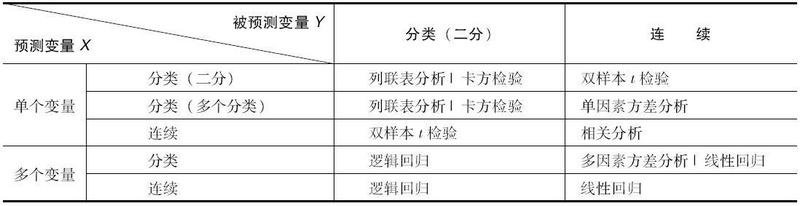
统计推断与建模方法如下表:
关于数据挖掘的应用
数据挖掘的方法分为描述性与预测性两种。它们都是基于历史数据进行分析,不同的是,预测性模型从历史数据中找出规律,并用于预测未来;描述性模型用于直观地反映历史状况,为后续的分析提供思路。
描述性数据挖掘也被称为模式识别,建模数据一般都具有多个属性或变量,属性用于描述各个观测的特征。用于描述现有的规律,常见的算法如下:
- 聚类分析:根据观测值之间相似度的大小将观测值进行聚类,常见的有客户分群、市场细分。
- 关联规则分析:发现强关联规则的物品组合,常用于商品的交叉销售。
- 因子、主成分分析:发现变量之间的相关性,将多维数据降维,并对降维后的数据进行解释。
预测性数据分析的数据有明确的预测变量与相应的因变量,用于预测未来将发生什么,使用的模型算法有以下几种:
- 线性回归:对连续型预测变量进行回归预测分析。
- 逻辑回归:对二元预测变量进行回归预测分析。
- 神经元网络:模拟神经元工作原理,依据数据进行训练和预测。
- 决策树:模拟人类决策过程,依据一定规则生成树状图并进行预测。
- 支持向量机:将低维数据映射到高维空间并进行分类预测。
不足之处,欢迎指正。
