


概 述
协同过滤作为集体智慧方法的典型代表作,在推荐系统的发展过程中占据着很高的位置,其简单容易理解的特性使其成为了大多企业的首要推荐方法,也带来了很好的推荐效果。但是作为集体智慧,其发挥的场景也往往受限,例如稀疏数据下的协同过滤就往往难以发挥很好的作用;协同过滤往往只采用了ID特征(或者评分特征)对其本身的一些信息特征很少利用;在协同过滤的实现过程中,矩阵分解采用的是dot计算,不符合inequality property,这很大程度上阻碍了其表现。针对这一系列的问题,我们将为大家介绍我们所验证过的协同过滤兄弟系列。其中不乏有些方法取得了state-of-the-art的结果。
传统的基于协同过滤的方法将用户对物品的评分作为单一信息源用于训练,生成推荐;但是在数据非常稀疏的情况下,会大大降低推荐的效果。
CTR(Collaborative topic regression,协同主题回归)是一个能将两种不同信息员紧密融合在一起的方法;但是,当辅助信息比较稀疏的时候,CTR训练得到的潜在表示并不是很有效。
因此,本文中采用了一个层次贝叶斯模型:CDL(Collaborative deep learning,协同深度学习),同时利用了内容信息的深度表示学习和评分(反馈)矩阵的协同过滤。
背景介绍
推荐系统中的现有方法主要有以下三大类:
-
基于内容的方法(content-based):利用用户画像或者产品介绍进行推荐
-
基于协同过滤的方法(Collaborative Filtering, CF):利用用户过去的行为或者偏好进行推荐
-
混合方法:组合基于内容的方法和基于协同过滤(CF)的方法进行推荐
目前,推荐系统主要面临以下问题:
-
获取用户画像比获取用户行为困难
-
基于协同过滤(CF)的方法有局限性:
▫ 当评分非常稀疏时,会严重影响预测精度
▫ 新用户或新物品的冷启动问题
因此,近些年混合的方法受到了越来越多的关注。
根据评分信息和辅助信息之间是否存在双向的交互,我们可以进一步把混合的方法进行划分:
-
松耦合方法:将辅助信息处理一遍之后,为协同过滤(CF)模型提供特征;由于信息流是单向的,因此评分信息无法为有用特征的提取提供反馈,对于这种分类,一般得依靠手动、冗长的特征工程流程来提高效果
-
紧耦合方法:允许双向交互。一方面,评分信息可以影响特征的学习;另一方面,提取的特征可以进一步提高CF模型(例如,基于稀疏评分矩阵的矩阵分解方法)的预测能力。通过使用双向交互,紧耦合方法可以自动从辅助信息中提取特征,并且自然地平衡评分和辅助信息的影响
CTR是一个最近提出的紧耦合方法,它是一个概率图模型,能够无缝地集成一个主题模型LDA(latent Dirichlet allocation,潜在狄利克雷模型)和一个基于模型的CF方法:PMF(probabilistic matrix factorization,概率矩阵分解)。但是,当辅助信息非常稀疏的时候,训练得到的潜在表示经常不够高效。
另一方面,深度学习模型最近在计算机视觉和自然语言处理应用的训练高效表示和实现高效性能方便展示了巨大的潜力。在深度学习模型中,可以使用监督式学习和非监督式学习特征。尽管由于深度学习模型可以自动学习特征,深度学习模型比简单模型更受欢迎;但是在获取和学习物品之间相似度和潜在关系方面,深度学习模型可能稍逊于简单模型(例如CF)。因此,需要通过协同进行深度学习来集成深度学习和CF。
但是,目前只有很少的尝试开发基于CF的深度学习模型。但是基本上的有一些问题:
部分方法实际上属于基于CF模型的方法,因为它们并没有融合基于内容的信息,而这些内容的信息对于精准推荐往往非常重要。
这些模型的深度学习组件都没有对噪音进行建模,因此它们非常不稳定;这些模型实现的性能提升主要是通过松耦合方法,而没有探究内容信息和评分之间的交互
为了解决上述问题,本我们调研了一种新颖的紧耦合推荐方法:CDL(collaborative deep learning,协同深度学习)。
符号表示
-
 :
:
 矩阵,是
矩阵,是
 个物品的完整集合,第 j 行为物品 j
的词袋向量
个物品的完整集合,第 j 行为物品 j
的词袋向量
-
 :字典大小
:字典大小 -
:物品大小
-
 :评分矩阵,其中
:评分矩阵,其中
 的值为用户的评分或反馈
的值为用户的评分或反馈 -
 :用户大小
:用户大小
问题:给定 和中的部分评分,预测
和中的部分评分,预测
 中的其它评分。
中的其它评分。
矩阵为
SDAE的干净输入, 为有噪音的矩阵也是
。SDAE的输出层 l 表示为
为有噪音的矩阵也是
。SDAE的输出层 l 表示为
 ,是一个
,是一个
 的矩阵。与
相同,
的第
j 行表示为
的矩阵。与
相同,
的第
j 行表示为 。
。
 和
和
 分
别为第 l 层的权重矩阵和偏置向量。
分
别为第 l 层的权重矩阵和偏置向量。 表示
的第n列,
表示
的第n列,
 是层数。为了方便表示,以后使用
是层数。为了方便表示,以后使用
 来表示所有层的权重矩阵和偏置集合。注意:
来表示所有层的权重矩阵和偏置集合。注意:
 层
SDAE对应一个$L$层网络。
层
SDAE对应一个$L$层网络。
协同深度学习
Stacked Denoising Autoencoders
SDAE(Stacked Denoising Autoencoders,层叠降噪自动编码机,https://github.com/Syndrome777/DeepLearningTutorial/blob/master/6_Stacked_Denoising_Autoencoders_%E5%B1%82%E5%8F%A0%E9%99%8D%E5%99%AA%E8%87%AA%E5%8A%A8%E7%BC%96%E7%A0%81%E6%9C%BA.md)是一个前馈神经网络,通过在输出中学习预测干净输入来学习输入数据的训练表示(编码),如图1所示。一般说来,中间的隐层(例如,图中的
 )被限制为瓶颈,而输入层
是干净输入数据的脏数据版本。SDAE解决下面的优化问题:
)被限制为瓶颈,而输入层
是干净输入数据的脏数据版本。SDAE解决下面的优化问题:
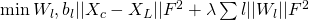
其中, 为归一化参数,
为归一化参数,
 为斐波拉契范式。
为斐波拉契范式。

图1: 一个 的2-层
SDAE
的2-层
SDAE
泛化的贝叶斯SDAE
假设可以观察到干净的输入和有噪声的输入
,与其它论文中介绍的相同,我们可以定义如下的生成过程:
-
对于SDAE网络中的每一层 l :
▫ 对于权重矩阵$W_l$中的每一列n:
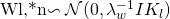
▫ 抽取偏置向量
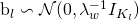
-
▫ 对于
的每一行
j : 公式1
公式1 -
对于每一个物品 j ,获得一个干净的输入:
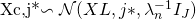
注意:尽管
干净输入
注意:当 趋向于无穷大时,公式1中的高斯分布将会变成一个中心点在
趋向于无穷大时,公式1中的高斯分布将会变成一个中心点在
 的Dirac
delta分布,其中
的Dirac
delta分布,其中 是一个sigmoid函数。模型将会降级为贝叶斯形式的SDAE,这就是我们称其为泛化SDAE的原因。
是一个sigmoid函数。模型将会降级为贝叶斯形式的SDAE,这就是我们称其为泛化SDAE的原因。
注意:网络的前层作为编码器,后
层作为解码器。后验概率的最大化等价于考虑权重衰减的重构误差的最小化。
协同深度学习
将贝叶斯SDAE作为一个组件,CDL的生成过程定义如下:
-
对于SDAE网络中的每一层 l :
▫ 对于权重矩阵$W_l$中的每一列 n :
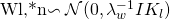
▫ 抽取偏置向量
-
▫ 对于
的每一行
j :
公式1 -
对于每一个物品j,获得一个干净的输入:
▫ 获取一个干净的输入:
▫ 获取一个潜在的物品偏移向量
 ,然后将潜在物品向量设置为:
,然后将潜在物品向量设置为:
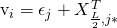
-
针对每个用户获取一个潜在用户向量:
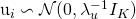
-
针对每一个用户物品对
 ,可以获得评分
,可以获得评分
 :
:
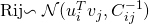
其中, 、
、
 、
、
 、 和
、 和
 是超参,而
是超参,而
 是置信度参数,与CTR中的类似(如果
是置信度参数,与CTR中的类似(如果
 ,那么
,那么
 ;否则的话
;否则的话
 )。注意:中间层
)。注意:中间层
 为评分和内容信息之间的桥梁。中间层以及潜在偏移
为评分和内容信息之间的桥梁。中间层以及潜在偏移
 是使得CDL能够同步学习有效特征表示和获取物品(用户)之间相似性和潜在关系的关键所在。与泛化的SDAE相同,为了方便计算,我们可以将
看做无穷大。
是使得CDL能够同步学习有效特征表示和获取物品(用户)之间相似性和潜在关系的关键所在。与泛化的SDAE相同,为了方便计算,我们可以将
看做无穷大。
当接近正无穷的时候,CDL的图形模型如图2所示,其中,为了表示的方便性,我们分别使用
 ,
,
 ,
来替代
,
来替代
 ,
,
 ,
,
 。
。

图2:左边是CDL的图模型。虚线部分的长方形部分表示一个SDAE。
上图展示了一个 的SDAE示例。右边是退化的CDL图模型。虚线部分的长方形表示SDAE的编码。
的SDAE示例展示在右边。注意:尽管L仍然是2,但是SDAE的解码消失了。为了避免混乱,我们省略了图模型中
的SDAE示例。右边是退化的CDL图模型。虚线部分的长方形表示SDAE的编码。
的SDAE示例展示在右边。注意:尽管L仍然是2,但是SDAE的解码消失了。为了避免混乱,我们省略了图模型中
 除了
除了
 和
和
 以外的所有变量。
以外的所有变量。
最大化后验估计
基于上面描述的CDL模型,所有的参数都可以看做是随机变量,因此完全可以使用例如MCMC(Markov chain Monte Carlo,马尔科夫链蒙特卡洛)或者变量估计方法。但是,这些方法一般会造成高计算复杂度。此外,由于本文中使用CTR作为我们的主要基线进行比较,使用类似于CTR中使用的方法进行计算是合理的。因此,我们在下面将会推导一个EM(Expectation Maximum,最大期望)风格的算法来获得MAP(Maximum Posteriori Probability,最大后验概率)。
和CTR中一样,最大化后验概率等价于在给定 的条件下,最大化
的条件下,最大化
 联合对数概率:
联合对数概率:
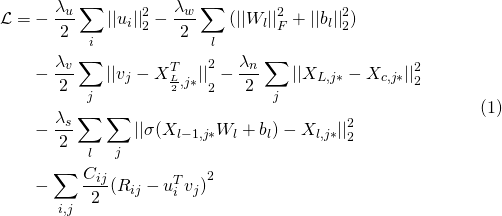
如果 趋向于正无穷,概率就会变成:
趋向于正无穷,概率就会变成:
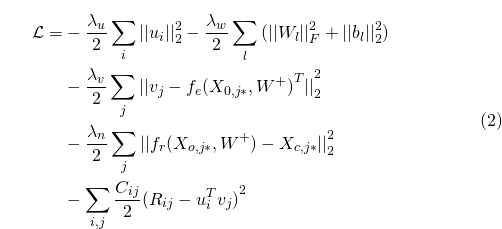
公式 2
其中,编码函数 将物品
j 有噪音的内容向量
将物品
j 有噪音的内容向量 作为输入,然后计算物品的编码,
作为输入,然后计算物品的编码,
 也将
作为输入作为输入,计算编码然后重构物品j的内容向量。例如,如果层数
也将
作为输入作为输入,计算编码然后重构物品j的内容向量。例如,如果层数
 ,
是第三层的输出,而
是第六层的输出。
,
是第三层的输出,而
是第六层的输出。
从优化的观点看,上面目标函数2中的第三个变量等价于使用潜在物品向量 作为目标的多层感知机;而第四个变量等价于一个SDAE最小化重构误差。从NN(Neural
Networks,神经网络)的观点来看,当接近于正无穷时,图1中CDL的概率图模型的训练将会降级到同时训练公用一个通用输入层(有噪音输入)、但有不同输出层的两个神经网络(如图3所示)。
注意:由于包含评分矩阵,第二种网络比典型的神经网络更加复杂。
作为目标的多层感知机;而第四个变量等价于一个SDAE最小化重构误差。从NN(Neural
Networks,神经网络)的观点来看,当接近于正无穷时,图1中CDL的概率图模型的训练将会降级到同时训练公用一个通用输入层(有噪音输入)、但有不同输出层的两个神经网络(如图3所示)。
注意:由于包含评分矩阵,第二种网络比典型的神经网络更加复杂。

图 3:降级CDL的NN表示
当 的比例接近正无穷时,它会退化到一个两步的模型,使用
SDAE训练得到的潜在表示将会直接输入到CTR中。另外一个极端是:当的比例接近0时,SDAE的解码器本质上消失了。图2中的右侧为当
的比例接近0时,退化的CDL的图模型。而在实验中,作者们发现:这两种极端情况都会极大地影响预测的精准度。
的比例接近正无穷时,它会退化到一个两步的模型,使用
SDAE训练得到的潜在表示将会直接输入到CTR中。另外一个极端是:当的比例接近0时,SDAE的解码器本质上消失了。图2中的右侧为当
的比例接近0时,退化的CDL的图模型。而在实验中,作者们发现:这两种极端情况都会极大地影响预测的精准度。
给定当前的,我们可以计算
 相对于
相对于
 和
的梯度,然后将它们设置为0,得到下面的更新规则:
和
的梯度,然后将它们设置为0,得到下面的更新规则:
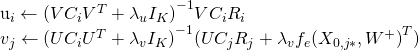
其中 ,
,
 ,
,
 是一个对角矩阵,
是一个对角矩阵,
 是一个行向量,包含用户i的所有评分,
是一个行向量,包含用户i的所有评分,
 体现了由a和b控制的置信度。
体现了由a和b控制的置信度。
给定U和V之后,我们可以使用后向传播的算法来计算每层的权重和偏置
。针对
和
,似然的梯度为:
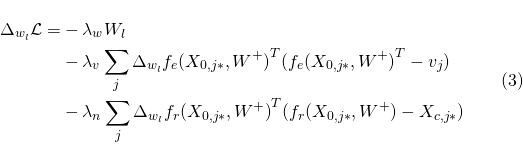
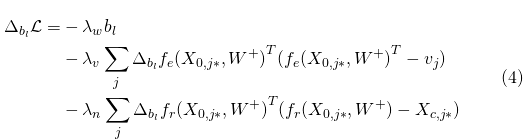
通过调整 、
、
 、
和 的更新,我们可以找到
的局部最优值。可以使用一些通用的技术来缓解局部最优问题。
、
和 的更新,我们可以找到
的局部最优值。可以使用一些通用的技术来缓解局部最优问题。
预 测
假设 为可观测到的测试数据。作者使用了
,
和
的点估计来计算预测的评分:
为可观测到的测试数据。作者使用了
,
和
的点估计来计算预测的评分:
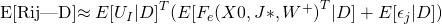
其中, 表示期望操作。换句话说,使用下面的公式预测评分:
表示期望操作。换句话说,使用下面的公式预测评分:
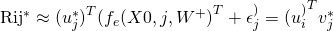
注意:对于训练数据中没有任何评分的新物品 j ,它的偏置 将会为0。
将会为0。
总 结
本文我们系统的介绍了如何使用协同深度学习的方法学习到评分矩阵的内容信息以及协同过滤信息。而后续可以通过使用一些更加合适的文章内容表示来替代文中使用的词袋模型。此外,也可以考虑融合生成推荐的其它上下文信息(例如,时间、地点等)。

【出浅入深聊聊推荐系统算法】系列文章共有10篇,本文为该系列的第一篇。请保持关注我们的公众号,后续会继续推送该系列的文章。以下是本系列文章的目录:
出浅入深聊聊推荐系统算法丨目录
推荐系统中协同过滤的葫芦兄弟(1)—— 协同深度学习模型
推荐系统中协同过滤的葫芦兄弟(2)—— 基于CAE的协同过滤模型
推荐系统中协同过滤的葫芦兄弟(3)—— Metric Factorization
推荐系统中协同过滤的葫芦兄弟之实现篇
推荐系统之NLP系列算法 — 文本分类
推荐系统之NLP系列算法 — 主题模型
推荐系统之NLP系列算法 — 关键词抽取
推荐系统之NLP系列算法 — 词向量、句向量和文章向量
推荐系统之NLP系列算法 — 新词发现
推荐系统之用户画像系列
福利来啦
转发本篇推文到朋友圈,无分组,保留3小时及以上
截图发送至微信后台
将有机会获得我们送出的程序员专属编程日历
一共有5个名额哦


