

为什么散列表和链表经常会一起使用?
数组占据随机访问的优势,却有需要连续内存的缺点。
链表具有可不连续存储的优势,但访问查找是线性的。
散列表和链表、跳表的混合使用,是为了结合数组和链表的优势,规避它们的不足。
我们可以得出数据结构和算法的重要性排行榜:连续空间 > 时间 > 碎片空间。
因此散列表和链表会一起来使用。
举例
LRU缓存淘汰算法
之前用链表实现,它的时间复杂度是O(n)。 利用散列表和链表可以优化到O(1)。
- 首先根据缓存数据的插入顺序进行排序,形成一个双向链表。
- 根据缓存数据data创建一个散列表,冲突的解决方式采用链表的形式。
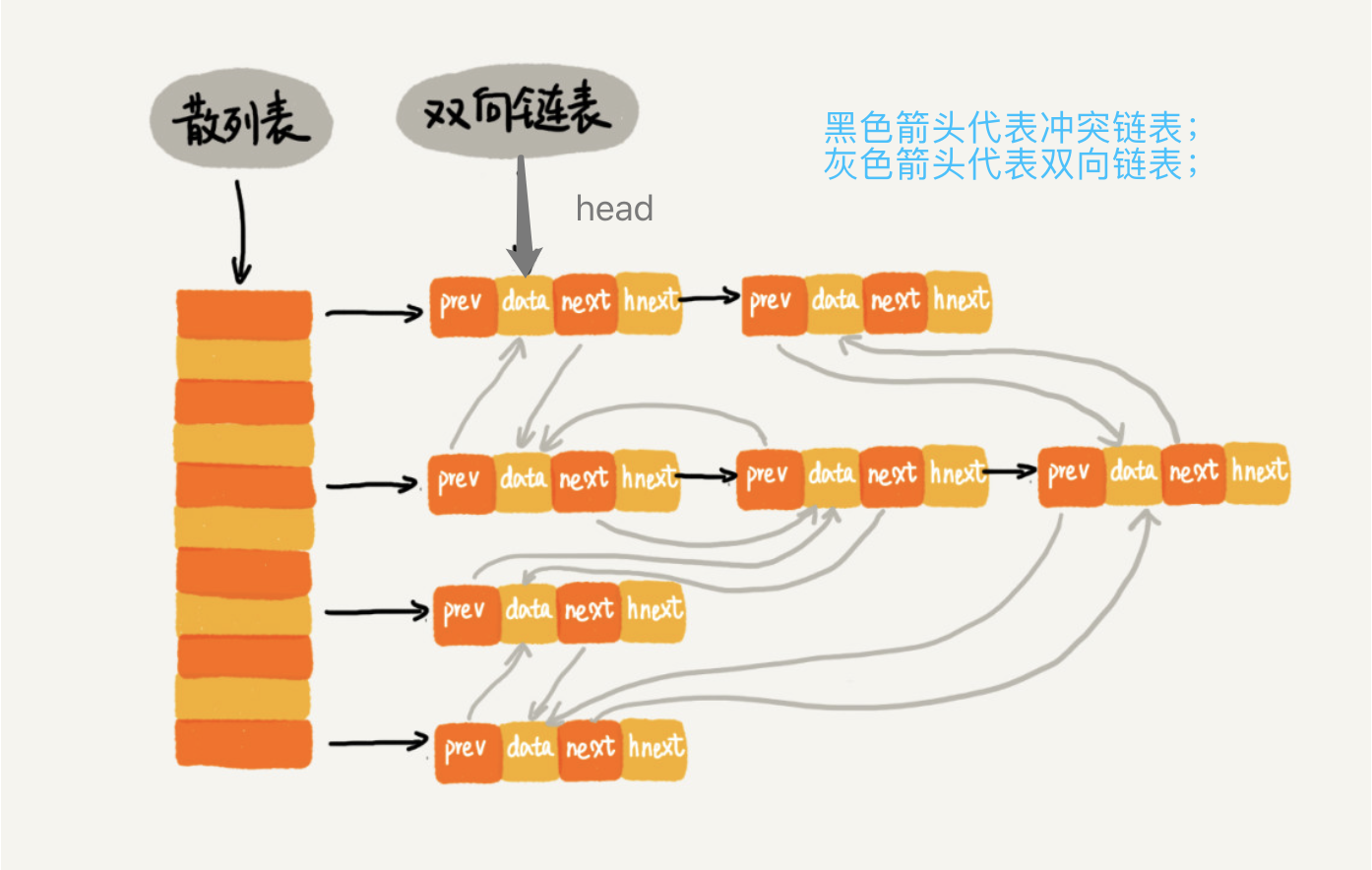
hnext指针是为了连接散列表中的冲突链表; prev和next指针是双向链表的前继和后继指针。
这样在查询、插入、删除操作的时间复杂度都是O(1)。
Redis有序集合
对学生(id、name、score)对象数据集合进行一下操作:
- 添加一个学生对象;
- 按照id来删除学生对象;
- 按照id来查找学生对象;
- 按照score区间查找数据,如score在[100,356]之间的学生对象;
- 按照score从小到大排序学生对象。
这时就可以结合散列表、双向链表、跳表来实现。 使用双向链表对学生对象以score进行排序,结合跳表。在使用id作为key实现散列表。
iOS YYMemoryCache 利用散列表和双向链表实现内存缓存。 散列表的实现:直接使用系统提供CFMutableDictionaryRef
