

本文内容主要参考优达学城”机器学习(进阶)“纳米学位的课程项目。
文章福利:使用优惠码027C001B减免300元优达学城课程学费。
1. 背景介绍
在本文中,笔者将带领大家对客户的年均消费数据进行分析。该数据来自于分销商,也就是说,分销商将不同类别的商品卖给不同的客户,商品包括新鲜食品、牛奶、杂货等等,客户有可能是饭店、咖啡馆、便利店、大型超市等等。
我们的目标是通过对数据的分析得到对数据的洞见,这样做能够帮助分销商针对不同类别的客户更好的优化自己的货物配送服务。
2. 读取数据集
数据集来自UCI Machine Learning Repository,本文删除了数据集中的Channel和Region 特征值,留下了其余有关产品的6个特征为了方便我们进行客户分类。
注:代码在数据集文件相同路径下运行
### 导入相关库
import numpy as np
import pandas as pd
data = pd.read_csv("customers.csv") #读取数据集
data.drop(['Region', 'Channel'], axis = 1, inplace = True) #删除'Region', 'Channel'特征
print("Wholesale customers dataset has {} samples with {} features each.".format(*data.shape))3. 数据探索
有了数据集,首先需要做的就是探索性分析,通过探索性分析首先对数据集有一个整体的直观理解,最简单直接的方式就是观察数据集中每个特征值的统计数据,包括最大最小值,均值,中值等。
from IPython.display import display
display(data.describe())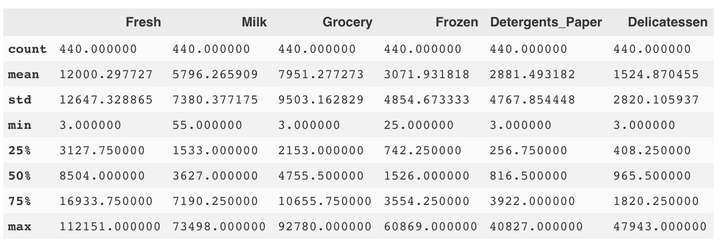
观察发现,一共有6个特征值,包括'Fresh', 'Milk', 'Grocery', 'Frozen', 'Detergents_Paper', 和 'Delicatessen'。分别代表'新鲜食物', '牛奶', '杂货', '冷冻食品', '洗涤剂和纸类产品', 和 '熟食'
我们可以发现,前五个特征,尤其'Fresh'和'Grocery'变化范围较大,'Delicatessen'变化范围较小。我们还可以通过对数据均值的观察,选取一些样本数据进行分析。
选择一些样本数据
为了更好的理解我们在分析过程中对数据做的一些转换,这里先采样一些样本数据用于观察。
indices = [3, 141, 340] # 样本的索引
samples = pd.DataFrame(data.loc[indices], columns = data.keys()).reset_index(drop = True) # 创建samples保存样本数据
print("从数据集中采样的数据包括:")
display(samples)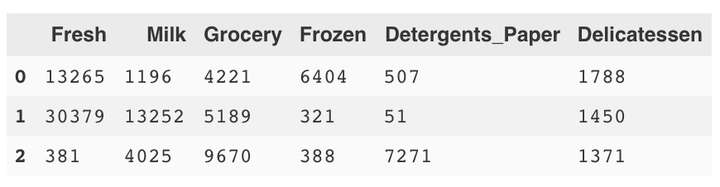
这时候观察我们采样的数据,对比我们之前得到的统计数据,可以对客户分类进行一些简单分析,以第一行数据为例,我们发现“新鲜食物”和“冷藏食品”的采购量较大,其他类别的采购量较小(相对于统计的均值来说),所以该客户很可能是餐饮饭店。
这里处于对原课程项目版权的尊重,只分析一个样本,读者可以按照我的思路分析其他的样本,或者推荐读者报名该课程进行学习。
特征值相关性
数据探索的另一个非常重要的步骤就是进行特征值相关性分析。
相关性分析也就是探索特征值之间是否有较强的相关性。
这里一个简单直接的方法就是,首先删除一个特征,然后使用其他数据训练一个学习器对该特征进行预测,然后对该学习器的效果进行打分来评估效果。
当然,效果越好,说明删除的特征与其他特征之间的相关性越高。
下面使用决策树作为学习器对特征Delicatessen进行预测。
new_data = data.copy()
new_data.drop(['Delicatessen'], axis = 1, inplace = True) # 删除特征值作为新的数据集
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(new_data, data['Delicatessen'], test_size=0.25, random_state=42) # 将数据集划分为训练和测试集
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor(random_state=0) # 创建学习器
regressor.fit(X_train, y_train) # 训练学习器
score = regressor.score(X_test, y_test) # 得到效果得分
print("决策树学习器得分:{}".format(score))读者可以替换删除每个特征,观察哪些特征与其他特征之间的相关性较高。
散布矩阵
另一个比较直观的观察特征值之间相关性的方法是使用散布矩阵(scatter_matrix)。
pd.scatter_matrix(data, alpha = 0.3, figsize = (14,8), diagonal = 'kde');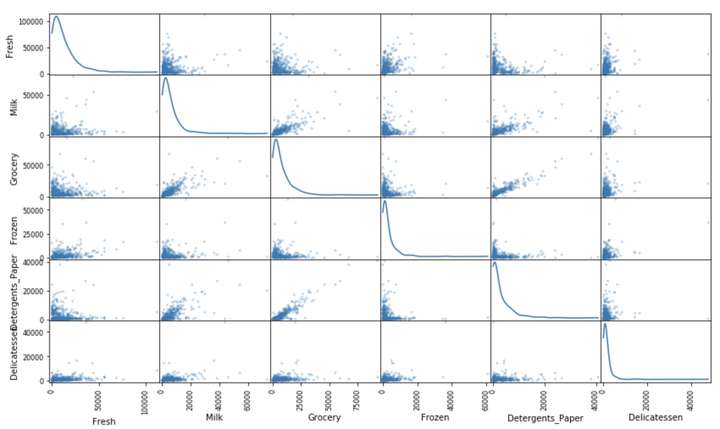
在图中能够看出某些特征具有较强的相关性,例如Milk和Grocery。
至于散布矩阵的原理,可以看这篇博文.
散布矩阵能以图形的形式“定性”给出各特征之间的关系,如要进一步“定量”分析,则需要使用相关系数。使用相关系数的一个简单的方法是使用seaborn库。
import seaborn as sns
ax = sns.heatmap(data.corr())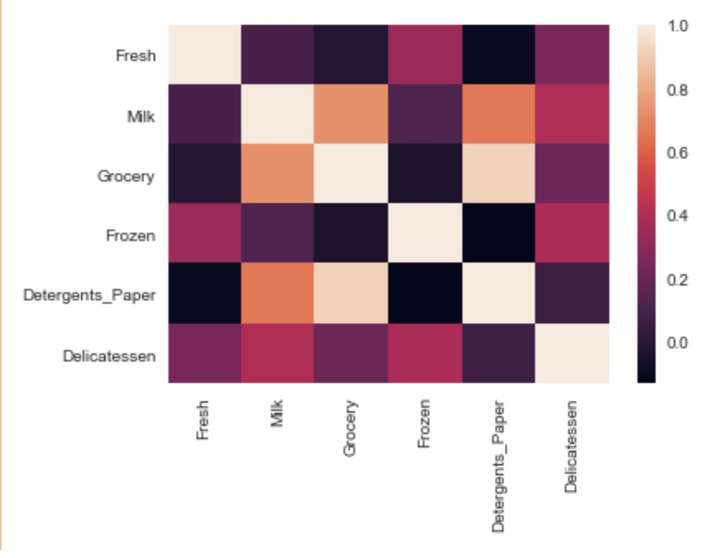
除了特征值间相关性之外,我们还能够看到每个特征的分布情况(对角线的图),很明显这些特征基本上都正偏分布,也就是说数据集中的一些比较极端的数据影响了分布。
4. 数据处理
特征缩放
当数据不是正态分布时,尤其当均值和中位数变化较大时(一般导致较大的偏差),一般应用非线性缩放——尤其对于金融数据。具体的算法,可以采用Box-Cox test,简单来说该方法计算使偏差最小化的非线性转换方法。
from scipy import stats
### 拷贝数据集
data_copy = data.copy()
samples_copy = samples.copy()
### 应用boxcox变换
for feature in data_copy:
data_copy[feature] = stats.boxcox(data_copy[feature])[0]
log_data = data_copy
for feature in data:
samples_copy[feature] = stats.boxcox(samples_copy[feature])[0]
log_samples = samples_copy
# 画图
pd.scatter_matrix(data_copy, alpha = 0.3, figsize = (14,8), diagonal = 'kde');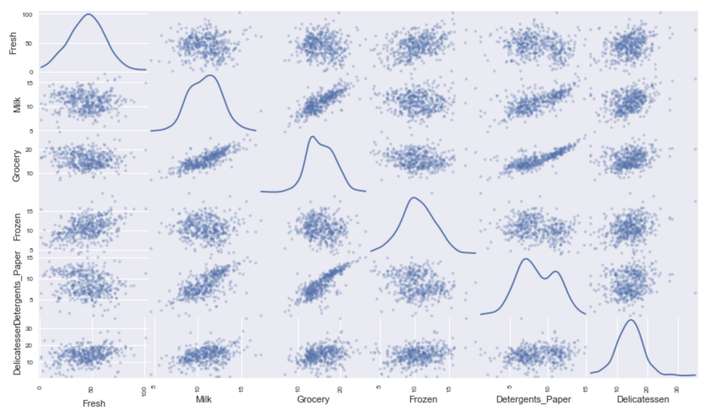
经过变换后的数据接近正态分布,特征之间的相关性也更加明显了。
这时候我们可以再来观察一下样本数据。
display(log_samples)我们发现数据值已经发生了变化,最明显的变化是都变小了,因为之前的特征都是正偏差。
异常值处理
完成了数据缩放,还要异常值处理。为什么要进行异常值处理,因为异常值是引起数据分布产生偏差的重要原因。
第一个问题是,如何检测异常值?这里我们使用的方法是Tukey's Method,简单来说就是首先计算异常值步进,即1.5倍的四分位数范围( interquartile range,也叫做IQR)。然后将所有IQR外超过异常值步进的数据定义为异常值。
for feature in log_data.keys():
Q1 = np.percentile(log_data[feature], 25)
Q3 = np.percentile(log_data[feature], 75)
step = 1.5 * (Q3 - Q1)
print("特征'{}'的异常值包括:".format(feature))
display(log_data[~((log_data[feature] >= Q1 - step) & (log_data[feature] <= Q3 + step))])
outliers = [95, 338, 86, 75, 161, 183, 154] # 选择需要删除的异常值
good_data = log_data.drop(log_data.index[outliers]).reset_index(drop = True) #删除选择的异常值这里我们选择并删除了一些异常值,遵循以下原则:
- 不符合前面观察到的特征之间相关性趋势的点。
- 一些极大或者极小值点。
如何选择是否删除一些异常值?还是保留?可以参考这篇文章。
5. 特征转换
应用PCA
PCA也就是主成分分析(principle component analysis),用于降维。简单来说就是通过计算得到一定数量的成分(component),每个成分能够解释一定比例的数据。
来看看对我们的数据应用PCA得到什么。
from sklearn.decomposition import PCA
pca = PCA(n_components=6) # 创建PCA
pca.fit(good_data) # 训练pca
pca_samples = pca.transform(log_samples) #对样本数据应用pca
pca_results = vs.pca_results(good_data, pca) #展示结果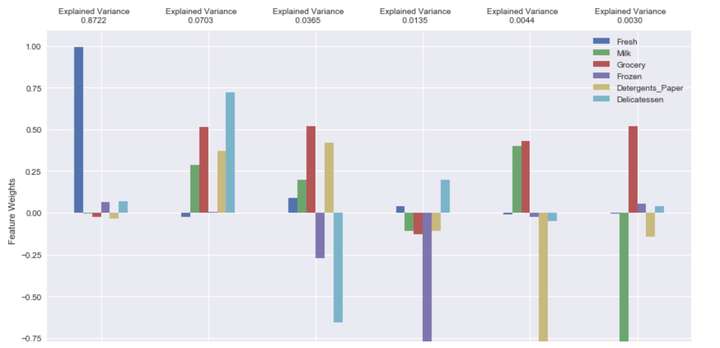
图中得到了6个成分的对应的特征权重值和方差解释。
我们以第一个成分和第三个成分为例说明。第一个成分的方差解释是0.8722,也就是说该成分能够解释87.22%的数据,如何解释?通过权重组合各特征值。我们看到,fresh特征有非常大的正权重,其他特征值的权重较小,所以第一个成分通过组合较多的fresh特征和较少的其他特征就可以解释87.22%的数据。换句话说我们可以将原来的6维特征数据降为1维特征数据,依然能够对原数据的87.22%进行解释。
再来看第三个成分,该成分的grocery和detergens_paper具有较大的正权重,frozen和delicatessen具有较大的负权重。这两部分的组合主要解释了第三个成分。该成分代表负权重部分特征的减少和正权重部分特征的增加。
一般来说前几个主成分既可以解释数据集的90%以上,这样就达到了降维的目的。
我们再观察采样数据。
display(pd.DataFrame(np.round(pca_samples, 4), columns = pca_results.index.values))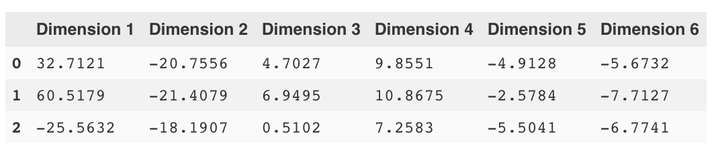
首先,采样数据原来的6个特征已经被新的特征(成分)取代了,新的成分代表原特征的某种组合。
现在我们可以将PCA应用到数据集中,将原来的6维数据降维2维。
pca = PCA(n_components=2)
pca.fit(good_data)# 训练pca
reduced_data = pca.transform(good_data) #转换数据
pca_samples = pca.transform(log_samples) #转换采样数据
reduced_data = pd.DataFrame(reduced_data, columns = ['Dimension 1', 'Dimension 2'])# 使用2维主成分代替原特征6. 聚类
经过前面的一系列转换,数据已经准备好用来聚类,这里我们选择使用k-means算法进行聚类。
k-means算法的好处是简单快捷,而且只需要调整一个主要参数,那就是簇的数量,如何确定簇的数量呢?
一个方法是,计算每一个数据的轮廓系数(silhouette coefficient),该系数是聚类是否合理、有效的度量。轮廓系数的取值范围是[-1,1],-1代表完全不相似,1代表完全相似。所以越接近1,代表该数据的聚类效果越好。
也就是说,我们可以尝试不同的簇的数量,然后计算轮廓系数,选择轮廓系数好的簇的数量作为k-means算法的参数。
这里我们给出簇的数量是2时,如何计算轮廓系数
from sklearn.cluster import KMeans
from sklearn import metrics
clusterer = KMeans(n_clusters=2, random_state=0).fit(reduced_data)# kmeans算法
preds = clusterer.predict(reduced_data)
# 得到预测结果
centers = clusterer.cluster_centers_
# 得到簇中心位置
sample_preds = clusterer.predict(pca_samples)
# 采样数据的预测结果
score = metrics.silhouette_score(reduced_data, preds, metric='euclidean')# 计算轮廓系数的均值
print(score)读者可以尝试使用不同的簇的数量,判断簇的数量是多少时数据的分类效果最好。
分类效果可视化
最后,我们可以将对客户的分类可视化.
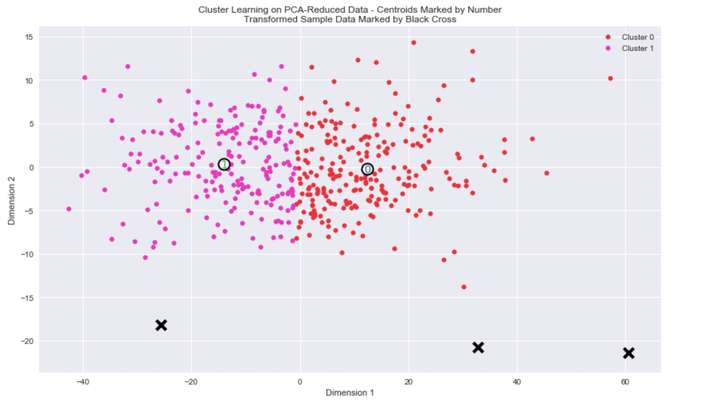
我们观察图中的结果,客户被分为了两类。
至此,我们的客户分类任务完成,后续可以根据不同的客户类别,提供不同的货运服务,或者通过A/B test来测试不同的客户对不同的服务的反应,以此来改善经营,提高效率。
