

本文转发自 微信公众号:FloodSung的AI游乐场
这是FloodSung的AI游乐场的第一篇文章!
微信的语音转文字我们都用过,那么反过来,文字转语音呢?
想像这样的场景:
你正在开会很无聊,就和朋友聊天,朋友在给你发语音,但是你却不方便说话。于是你这边将语音转文字,然后你输入文字,而你朋友却能听到你的声音,关键是,朋友还不知道这声音不是你说的,会不会很酷?
再想象一个场景,年轻的妈妈因为不幸突然丧失了发音能力,可爱的孩子再也听不到妈妈的声音了,这是多么的遗憾。那么如果能够文字转语音的话,并且转成的语音就是原来妈妈说话的声音,那会多么美妙。如果未来还能直接通过脑电波解码要说的话,我们就可以用机器完全代替我们的声带了。
所以,文字转语音真是一个很有价值的技术。这个技术近年来由于Google Deepmind WaveNet的发展,文字转语音已经到了人很难分辨的程度了,但是我们上面说的功能要实现,需要能够利用我们特定少量的声音就能高度复制还原我们特定的声音,这个难度就大多了,也神奇很多。
现在能实现了吗?
答案当然是Yes!
作为FloodSung的AI游乐场的开篇文章,当然是给大家爆料最新最强的技术啦。
DeepMind在ICLR2019的投稿文章中有一篇是《Sample Efficient Adaptive Text-to-Speech》,前天才在arxiv上放出来。
在这篇文章中,Deepmind以WaveNet做基础,基于Meta Learning技术(今年上升势头最猛的领域),初步实现了这个功能,大家可以上 https://sample-efficient-adaptive-tts.github.io/demo/ 感受一下这个技术。仅使用非常少的语音样本,就能在新的文字转语音中高度还原说话人的声音。按照paper里面的说法,Deepmind实现的这个系统骗过了目前最先进的说话人识别系统,也就是机器分辨不出来这是你说的还是机器说的,真的很牛逼!
谈完技术谈商业,Deepmind实现的这个技术恐怕明年就可以嵌入到Android系统上了。对于国内公司来说,貌似WaveNet技术Google已经申请了专利,所以想要直接拿来主义恐怕不行。但是除掉WaveNet技术,Meta Learning技术方法就多了,随便改吧改吧都可以和Deepmind不一样,倒是有点机会。
说到商业当然也要说到道德了。因为文字转语音是一个双刃剑,既可以用在好的地方,也可以用在坏的地方。比如以后你将无法确定对面打来的电话是不是真人,如果他模仿你最好朋友的声音找你借钱你给不给呢?由于视频也同样可以合成,未来远程聊天只能先生物识别确认一下了,否则一切都可能是假的。想到这,未来的世界又没有那么美好了。
今天的AI爆料就基本说完啦,知道这个最新进展的朋友就可以开心的关掉页面啦。但是,FloodSung的AI游乐场绝对不是那些一般AI媒体,只是简单介绍或者翻译一下这些成果,我们还想要Detail细节!所以,下面我们就花点时间说说DeepMind到底是怎么实现的吧!
====================================================
下面的文字会涉及比较专业的知识,不了解的朋友可以略过。
先说说Meta Learning,今年ICLR2019的投稿文章中Meta Learning的数量特别多,好几十篇,Meta Learning也不再仅仅做图像的Few-Shot Learning少样本学习了,而是延伸到各个领域,就如我们今天介绍的文字转语音。Meta Learning到底是什么?在我看来就是深度学习的涡轮增压器,加上去,让学习速度变快!适应能力变强!Meta Learning可以有多火?或者说Meta Learning的坑有多大?只要把任何一个现有的CV,NLP的问题加上Few Shot都可以变成新问题,简直就是一个金矿。
Ok,我们回到Deepmind这篇Paper,到底对WaveNet做了什么呢?简单一句话就是训练一个Multi-Speaker WaveNet做为一个prior,然后基于此做few shot adaptation。
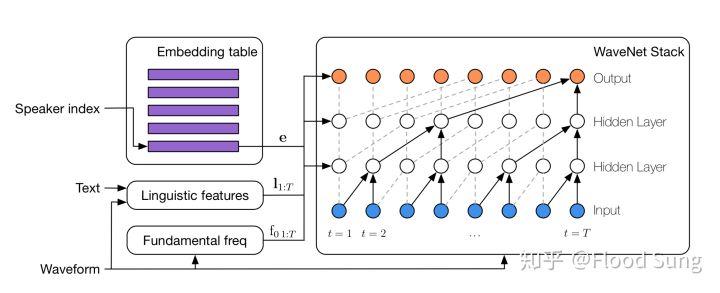
Embedding Table里面就是不同Speaker的Embedding,额外加上Linguistic features (输入的text信息)及Fundamental freq,作为condition输入到WaveNet中进行训练。
那么怎么做Few-shot adaptation呢?Paper里面给出了多种方法。
1)第一种,预训练好整个multi-speaker WaveNet后,拿到一个新的说话人样本,我们先固定WaveNet Stack的参数,然后随机化Embedding,用新样本来训练这个embedding。
2)第二种,最最简单粗暴的做法,直接用新样本finetune整个网络。
2)第三种,额外训练一个encoder network,输入新的说话人样本,然后就能预测新的embedding。这样训练完之后,拿到新的说话人样本,我们就可以不用接着训练,直接通过encoder network就得到了对应的embedding,从而产生新的声音,这个方案不需要finetune,所以很省时间。
大家看到上面几种方案一定会疯掉,怎么这么简单?Meta Learning在哪里?其实简单的说,conditional neural network就是Meta Learning的最基本实现方式,而且效果很不错哦。
接下来说说实验。有了上面三种方法,Paper里面使用一个公开的数据库LibriSpeech,包含了2302个说话人样本,不算多。然后测试的时候,Deepmind使用了10s和5min两种测试方法,使用的样本时间很短。但只要这么短(甚至只是10s)的时间,取得的效果就可以被评价为Good 第4级 (指标分5等)。然后第二种全部做finetuning的做法效果是最好的,不过这个finetuning所需的时间也最多了。
小结一下,Deepmind这篇Paper用最简单的Meta Learning方法,在Text-to-Speech这个新Few-shot learning问题上取得了SOTA,当然Deepmind也指出,目前的实验使用的样本是高度简单纯粹的,现实环境有噪声的情况可以作为未来的下一步研究。
本文就说到这,以上分析也包含了很多个人观点,欢迎大家批评指正!
最后,欢迎各位感兴趣的朋友关注我新开的公众号 FloodSung的AI游乐场 ,相比于知乎专栏,我可以更快速的为大家分享最前沿AI,谢谢!https://github.com/floodsung/songrotek.github.io/blob/master/gallery/qrcode.jpggithub.com
公众号二维码在这里:
