

本文转自公众号:FloodSung的AI游乐场
今天Flood和大家分享的是ICLR19最新的投稿文章《Meta Domain Adaptation:Meta-Learning For Few-Shot Learning Under Domain Shift》。
这篇文章做了什么事情呢?
就是给目前的Few-Shot Learning加点困难,让Meta-Train和Meta-Test的图像Domain不一样:
不过一开始在我看到这篇论文的标题时,我以为的Meta Domain Adaptation不是这样的设定。
我们先来看一下Meta Learning的基本组成:

在之前的博文中,我们更多的是关注Task里面Train和Test的不一样。比如上一篇博文讲无监督Meta Learning,就是Train是无监督学习,而Test是有监督学习。所以我初看标题以为这篇文章的设定是Task里面的Train和Test是不同domain,然而实际上是Task里面的Train和Test都是一样的domain,但是Meta-training和Meta-Testing的domain是不一样的。
这样也能做吗?按照标准Meta-Learning设定,这意味着我们在Meta-Training阶段对于Meta-Testing阶段的domain是一无所知的,这怎么adapt?所以这篇论文里的实现方法就直接在Meta-Training阶段使用了Meta-Testing阶段的数据,只不过是无监督的数据。
在分析方法之前我们先看看这篇论文的动机。论文中反复说现实情况下可能Meta-Testing Domain的数据是很少的,所以我们可以使用Domain数据多的做Meta-Training,然后Adapt到这个Domain数据少的上面。但是这个动机却和实际论文方法实现相违背,方法中并没有限制Meta-Testing Domain数据的使用。所以这篇文章动机有点问题。
下面我们来说说方法论。一句话说明就是简单粗暴的把Domain Adaptation的方法和Meta Learning的方法结合一下:
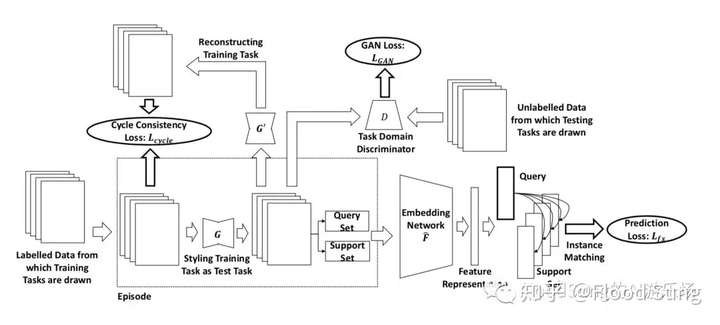
解释一下:作者还是考虑把Meta-Training里面的图像先能通过G转换为Meta-Testing里面的图像Domain,然后再做Meta Learning。而前面这部分转换工作就是完全的Domain Adaptation的方法,通过GAN来训练,所以这里不得不使用了Meta-Testing里面的数据,其实在我看来这个做法违背了Meta Learning的基本设定,意味你已经看到了Meta-Testing的数据,即使是无监督的,那也可以认为是Cheating了。然后作者额外的加了一个G'来反过来生成Meta-Training的图像Domain,然后加了一个与现有图像的对比作为Cycle Consistency Loss。这是GAN里面的常用操作。
然后论文里直接和完全没有domain adaptation的MAML和Prototypical Network做对比,这是完全不公平的,显然比不过。
从Reviewer的角度看,这篇论文的方法和动机有矛盾,并且在方法上直接在Meta-Training上使用了Meta-Testing的数据,这是不合理的。所以这篇论文的评价在我这里并不高。
那么,我们接着思考一下,是不是Task里面的Train和Test Domain不一样更合理呢?这样的问题设定就是说我们希望这个图像识别系统看到一个新物体比如说一只猫之后,不仅仅能识别照片的猫,还能识别卡通化的猫,或者油画的猫,那么这就意味着我们让这个图像识别系统自己学习了Domain Adaptation,能够更好的提取图像的有用特征。或许这是更好的问题,值得研究!
