

今天Flood和大家分享一篇Meta Learning在NLP上应用的paper,这应该是我看到的第一篇。
Paper的名称是《Meta-Learning for Low-Resource Neural Machine Translation》,微信文章不方便放链接,所以感兴趣的朋友还是Google之。
在之前的博文中我说过,任何现有问题加上Few-Shot或者Fast Adaptation都可以直接变成Meta Learning问题,那么自然就可以用Meta Learning的方法加以处理。所以,这篇paper针对的是Neural Machine Translation神经机器翻译,可能还是叫文本翻译比较直接吧。那么就加个少样本呗,就变成了Low-Resource Neural Machine Translation。
那么在构建一个新问题的时候我们当然应该考虑一下有没有意义,也不是说任何问题都需要Few-Shot是吧。那么这里文本翻译有这个需求吗?我想当然是有,特别是一些小语种,可能收集的数据样本比较少,那么这个时候我们又希望这个翻译系统也能达到不错的效果,那就需要少样本了,或者说我们希望我们的这个翻译系统是通用的,我们让其学习很多其他语种的翻译,然后之后能够把这种翻译能力迁移Transfer到新的语种中。那么有了明确的动机,这篇Paper就是有的放矢,可以嗷嗷的用Meta Learning搞起来了。
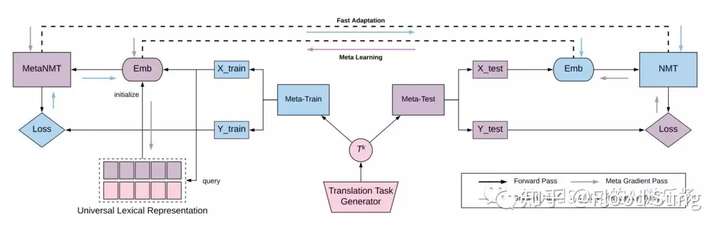
那这篇paper就是很直接的,就使用MAML来做,那么上图画的有够复杂的,真的是把一个简单的东西硬生生让你觉得很麻烦。简单的解释一下就是:
1)构造一个translation task generator用来生成不同的翻译task用于meta-train和meta-test,这就是一般Few-Shot Learning的构造。
2)将采集的task用于MetaNMT的训练,使用MAML训,目的就是为了得到一个好的初始化参数用于Meta-Test的task实现Fast Adaptation,也就是只要用少量样本训练,就能取得好的效果。
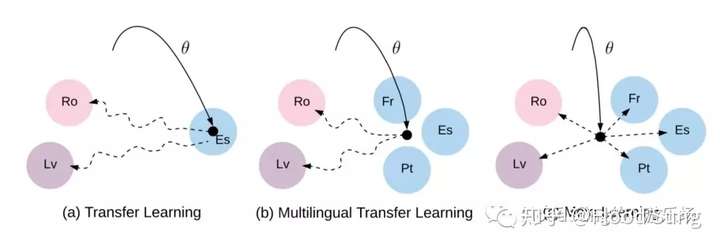
那么这里作者也稍微解释了一下Meta Learning的方法和之前的transfer learning方法的不同,Meta Learning这个训练相对一般的transfer learning它能得到一个更好的初始化参数,是独立于训练语种的,因为我们是按test的方式来train我们的meta learning网络的。
3)毕竟NMT有它的独特性,关键就是不同语种的输入输出的space不一样啊,那这个需要一点处理,这篇paper就是使用了一个Universal Lexical Representation 来表征不同的语种的特征,从而得到合适的embedding用于MetaNMT的训练。这部分可以算是NMT结合MAML创新的地方吧,也就是把不同的技术合在一起用。
那么整体来说就是也没有太多的创新点,但是就是把Meta Learning成功的在Low-resource NMT上做了应用,并且取得了更好的效果。
小结一下,这篇paper是第一篇使用Meta Learning在Few-Shot NLP问题上的paper,也是开了一个新的口子,意味着之后必然会有更多的相关的Meta Learning for NLP的paper。有兴趣的朋友确实是可以考虑去做一下。然后我们其实可以看到就是MAML在NLP上还是有一定优势的,比较简洁,要不然确实也可以搞个conditional neural network来做,比如之前分享的Deepmind做的文字转语音,就是用特定语音弄一个针对的embedding来处理。有时候我发现不管是人还是公司都倾向于使用自己搞的方法,而不是利用别人的做法。所以DeepMind就更多的在DQN,A3C上面发展,而OpenAI则是John Schulman搞的PPO,TRPO。
本文就分析到这里啦。
最后,欢迎大家关注本人公众号:FloodSung的AI游乐场,欢迎关注,本人所有文章都将先于公众号发布!谢谢!
