

Google最近在微信发布了第一款微信小程序——「猜画小歌」。一经推出,立刻反响不凡,在微信朋友圈可谓是掀起了一股热潮。
平日里一本正经谈工作,一把狗粮秀幸福的朋友们,一个个都回归童心,纷纷和AI玩起了绘画。「猜画小歌」童鞋,能够准确地识别出涂鸦画作的主题,已经得到了好多人的表扬认可。那么问题来了:
- AI能猜人的涂鸦,它自己能伪装成人涂鸦吗?
- 如果AI能伪装成人涂鸦,背后的算法是什么呢?
- 这个算法还有什么应用?
在这篇文章里,我们首先给AI一个更难的任务,根据不同的主题创作涂鸦,而且画风要和人类一样,不拘一格又不离其宗,目标是分辨不出画是人画的,还是电脑画的。然后,我们会展示画出的图片和背后的模型——生成对抗网络GAN。其次,我们会给一个冰山版的GAN原理简要说明。最后,我们再分享其它几个GAN的奇妙应用。
谷歌最新推出的「猜画小歌」是一个涂鸦游戏,玩家在20秒之内根据程序提示的词语作画,AI会在你画画的过程中猜测你画的内容,如果AI能够成功识别你的画作,游戏就能继续。

小程序一推出,立马得到了诸多微信用户的喜爱,在朋友圈,一场绘画大赛正在进行。虽然有些朋友的抽象艺术也让我不敢恭维,但是这个游戏中也涌现出了不少优秀的涂鸦作品。Google有一个网站,上面放了很多用户的绘画作品:https://quickdraw.withgoogle.com/data,大家可以欣赏一下:

1. 从猜画小歌到画家小歌,创作比判别更难
玩家与猜画小歌之间的互动就像是一个你画我猜的游戏,我们是画画的那个人,AI扮演着那个猜画的角色。猜画小歌能在短短的20秒时间里,根据用户绘画的内容,判断出用户绘画的主题,并且最终能有很高的判别准确率。这能力已经令好多玩家对它着迷不已了。
但是如果我们让游戏的角色反过来,AI有能力成为画画的那位吗?毫不夸张地说,画画相对于猜画是一个更困难的任务。
因为相较于创作,判别是容易的。往往我们只需要能够提取到几个特征,运用这几个特征就能完成判别,但是想要创作就需要运用好更多的信息。比如小孩子两三岁的时候,大人们带它去马路边认车,两个轮子的是自行车,三个轮子是三轮车,四个轮子长得像个大大的长方形的是公交车,四个轮子的小盒子是小轿车,四个轮子前半段高后半段低的是卡车,不到一个小时肯定已经能够熟练地认清。但是回到家里,让孩子简单几笔勾勒个小汽车,画出来的却不知又是个什么奇怪的东西。
创作也更接近「理解」的本质。正如伟大的物理学家费曼所说:
What I cannot create I do not understand
类似,浙大生物学教授王立铭也说:
关于生命,如果我们能够在实验室从无到有地制造出,一个哪怕是非常粗糙简陋的有机生命,能够存活、繁衍、和环境互动,那我们就可以骄傲地说,我们已经知道得足够多了。
那么,有没有办法,能教AI超越判别,直逼创作,像人类一样涂鸦呢?这样的画作既清晰明了又不失豪放随性,既紧密围绕主题又不失图片的丰富多样?生成对抗网络,这一AI领域的当红炸子鸡,就可以帮助我们可以完美地训练出一位「画家小歌」。它的英文是Generative Adversarial Networks,简称GAN。
(以车轱辘数和车的形状判别车类型的模型、通过识别图像的某些特征判断主题的猜画小歌,这类模型被称为判别式模型。而GAN是一类先通过对数据的本质建模,然后再通过训练来学习模型中的参数的模型,属于生成式模型。)
2. 嘿,不要等,就是GAN!
话不多说,我们就用GAN训练了一个「画家小歌」。直接先展示两张结果图。


上面的图A和图B,各有50幅涂鸦汽车,其中一幅图中的50辆车是通过Google猜画小歌收集到的人类作品,另一幅图中的50辆车全是GAN模型的创作。
亲爱的冰友,不知道你觉得图A图B哪幅画是人类的创作呢?(文末会公布答案哦)
当然了,除了画车,它还会画些别的。有的画得像一些,比如斧子:

有的依稀可辨,比如棒球:
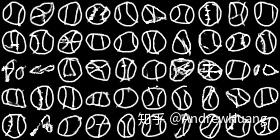
可是,如果人类的画作教材都不靠谱,AI就会画得不知所云。你能看出这是长城吗?

其实,创作涂鸦画只是这个GAN模型的「冰山一角」,它还有其它很多奇妙的应用。GAN的底层是一个精妙无比又符合直觉的设计,它得到深度学习的奠基人Yann LeCun毫无保留的赞誉:
Adversarial training is the coolest thing since sliced bread
对抗性训练是自切片面包发明以来最酷的事儿
嘿,在英语的语境里,「自切片面包发明以来」的大意就是——「有史以来」。
3. 为什么说GAN是一个精妙的设计?一个冰山版的GAN原理简单解释
GAN的模型往简单了说,两个神经网络,一个负责努力画画,一个负责判别画出来的像不像人画的。这两个神经网络是GAN最重要的部件,它俩互相对抗,就能训练出很好的图片生成器。所以叫生成对抗网络。
GAN里面这哥儿俩的对抗是这么玩的:
- 每张图是高维空间上的一个点
- 高维空间的点可以用低维参数来表达
- 生成器通过变换低维参数在高维空间内尽情创作
- 判别器通过比较生成器创作的画作和人类画作,训练提高判别画作的准确率
- 生成器利用判别器的监督,提升生成能力
- 以上第四第五点需要交替重复进行,从而不断提高生成器的生成能力和判别器的判别能力
(1) 一张图怎么是一个点呢?好烧脑啊。
咱们头上顶个冰袋降着温说。每一张图片都可以看成一个高维数据点,它的维度数等于像素数,每个维度的取值是这个像素的颜色值。比如,一张28x28像素的256级灰度图片,就是784维空间中的一个点,每个维度都有一个在0-255之间的灰度值。
(2) 这么高维的一个点,怎么能降维表达呢?
如果没规律,不行。如果有规律,就可以。
某一种类型的画是有规律的。举一个有规律的规则图形的降维例子帮助理解:
比如28x28画布上有脸、有眼睛、有嘴的笑脸图案,规律是一个圆圈、两个点、一个圆弧。它们的特征可以抽象成几个参数:脸的大小、眼距、眼高、嘴弧半径、嘴弧弧度、和嘴高。有了这六个参数,我们就可以映射到784维空间上,表达不同的笑脸。
瞧,在笑脸这个规则图形的规律下,我们把784维降到6维实施打击。
这里必须澄清,让电脑涂鸦,解决的不是简单规则图形的问题。AI通过学习,找到高维图形与指定低维空间的映射关系,虽然这个低维空间不一定能像笑脸图形6参数一样被人理解,但是降维打击的思路是一样的。
(3) 通过改变低维到高维的映射,我们就可以让生成器开始瞎画了。
举个一维空间直接映射的例子:假设我们要画的图片主题是一只笔直的蚯蚓,每只蚯蚓只有长度不同,其它都完全相同,那么一条蚯蚓就能用一个长度数值来表示了。现在我们要画一只新的蚯蚓,我们有一个长度值,就能画出一条蚯蚓,这很容易。
但是28x28画布上的784维空间怎么办?我们能用一个低一点的维度来画吗,比如64维?这个很难。64维到784维是一个复杂映射。那好,我们就用一个神经网络来完成这个复杂映射。这个神经网络就是GAN模型里的生成器(Generator)。它的输入是一个低维空间中的一个点,输出是高维空间的一个数据点,一张28x28的图片。
其实这就像人类的DNA和表达出的细胞和器官关系,DNA是一个相对低维的序列,而复杂的细胞和器官是低维DNA数据在高维上的表达。
(4) 现在我们的生成器会画了,但还只是瞎画,为了能更好地指导生成器画画,我们请判别器来当裁判——不过嘛,得先给判别器做入职培训。
你可能会想问了:我们的生成器不是已经会画了吗?为什么要引入一个判别器?那是因为之前我们的生成器只是学会了如何生成一个784维空间的数据点,可能只是乱生成一通,我们也不知道它生成的图片像不像人类画的。为了更好地监控这个作画的结果,我们请判别器(Discriminator) 来当个裁判,给出像不像的衡量标准。判别器的输入是一个784维的数据,输出就一个0和1之间的实数数值,如果数越接近1,代表判别器认为这画越像是真人画的,如果数字越接近0,代表判别器认为这画越像是生成器生成的。有了一个好的判别器,我们就可以回过头和生成器说「你画得不像,你得改改」或是「你画得挺像,继续这么画。」
但判别器一开始也是一个小白,我们要对它进行培训,使他成为好的裁判。具体的方法是,让生成器生成一大批画,同时我们拿一批人类画的画,把两批画混合起来丢给判别器,让它去判断每张画属于哪批。等他判别完了,告诉它「刚这里面,哪些你判错了哪些你判对了,你得思考总结一下规律,提升一下判别能力吧?」判别器经过这样的入职培训,判别的准确率会有提升。
(5) 判别器监督生成器的训练,提升生成器作画能力。
等到判别器这个裁判培训成功了(能够准确判别画像是生成器创作的还是人类画的),其实也就成了一个能监督生成器训练的好伙伴。因为这时候生成器每画一张画,判别器能立马给出反馈:「我觉得这画像人画的」或「我觉得这画不像人画的]。生成器得到了反馈,就能思考总结一下规律,提升一下生成能力了。它改进自己的作画,目标是蒙骗过判别器,让判别器区分不出生成器的画作和真实的画作。因为如果达成了这个目标,生成器的画作也就更像人类的手笔了。
对了,刚刚说的思考总结一下规律,提升一下XX能力,其实对应的是神经网络的后向传播算法,这个我们不详细解释,有兴趣的冰友可自行了解。
(6) 最后的这两个步骤要重复很多遍。
由于一开始生成器和判别器都是小白,(4)给判别器做入职培训(5)让判别器监督生成器的训练,这两个步骤只进行一次是不够的。这个原因其实不难想象,以画涂鸦汽车为例,因为一开始的生成器是个小白,它画的可能都是一些乱七八糟的图形线条,一点都不像车,我们把这样的图和一堆人类的汽车涂鸦作为判别器入职培训的习题,训练出来的判别器其实不一定有多好。可能它只要学到:扁长的图形就是车,就已经可以通过入职培训了。可想而知,在这样的判别器的监督下训练出来的生成器,也不会多好。所以,这个过程要循环往复很多次,双方互相对抗,共同进步,才能保证最终训练的质量。这就是对抗训练的过程。
展示一下模型的训练过程
说完了精彩的对抗训练机制,在对抗的过程中,生成器的能力是不是真的在不断提高?不信我们就来瞧瞧。以下是对抗性训练的过程中,不同时间节点截取的生成器涂鸦画作:

对抗训练100次以后,让此时的生成器画50张汽车涂鸦,可以看出这时的生成器大概只知道汽车是个扁扁的东西,也没意识到汽车涂鸦可以是多样的。

而当训练进行到1000次,生成器已经大概知道了汽车是个什么形状的东西。就如同不同人画的汽车可能是不同形状的,生成器生成的形状也有了不同。

对抗10000次以后,生成器对细节的把控有了很大的提升,比如汽车出现了前轮后轮。汽车的样式各有不同,且笔触比较清晰简洁,这些都比较像人画画时的手笔。

等到对抗训练完100000次以后,笔触就更为清晰了,图片也有了更好的细节。大部分图像以假乱真。考虑到原始数据中就有一些网友的胡乱创作,这样的训练结果已经比较令人满意。
是不是能看到生成器的能力在持久地提高呢?
这样的过程,是不是让你想起了小时候自己学习写字?一开始的字写得什么都不像,后来写得有点像样但是张牙舞爪,连笔画都常常不连贯。在这个过程中,老师一直拿着课本和自己的示范告诉你「你看你写的和我给你看的不一样,我这才是正确的写法」。然后你的字开始渐渐收敛,慢慢端正。在这个层面上,GAN和我们的学习过程还真的有些相似。
4. 更多精彩的GAN模型
虽然AI在画涂鸦画这个任务上表现已经非常突出,但这不过是GAN的能力最简单的应用罢了。在更多的领域,GAN已经有了很多更为深入的应用。
先看这篇CVPR2018的论文,Progressive Growing of GANs for Improved Quality, Stability, and Variation (作者为NVIDA公司的Tero Karras等,此文中的模型以下简称PG-GAN),就做到了用生成了人脸。把大量的真实人脸图像作为数据输入,PG-GAN就能创作出无数的人脸,这些人脸极其逼真,个别还有些俊俏抑或是有点性感。必须强调的是,这些极其逼真但又千变万化的脸,没有一张是真实存在的。
以后机器人需要伪装成人类,说不定就用这个技术生成的人脸。这不禁让我想起聊斋里的画皮。


另一个例子,用SR-GAN(论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 作者为Christian Ledig等)可以把低像素的图片高清化,或者把打码的图片去码:

从左到右前三张图片分别是三个不同的模型(bicubic interpolation,SRResGAN,SR-GAN)把低清图片高清化后的处理结果,最后一张图片是高清原图。其中,SR-GAN的把低清像素还原后的结果最为清晰,并且已经非常接近原图。
当然也免不了有人用此技术公然开车,比如下面这位——提高驾驶技术:用GAN去除(爱情)动作片中的马赛克和衣服 https://www.leiphone.com/news/201706/feaYeOeyO7ZVvbuZ.html
GAN也可以实现风格迁移(通过学习两类图像,能够实现在两类图像间的风格迁移),比如能够把莫奈的画转化为现实中的图片,也可以把现实中的图片转变为莫奈的风格。这是论文Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (简称Cycle-GAN)的展示研究成果,作者为Jun-Yan Zhu等。

是不是酷到没朋友!?
除此之外,GAN还有很多奇妙的应用,比如训练生成二次元妹子的头像,根据配图标题生成图片,又或者是结合GAN和强化学习制作对话系统……
5. 揭晓答案
在文章的最后,我们先来公布一下文中抛出的那个问题的答案,图A图B到底哪幅图中的汽车不是人画的?
答案就是:

不论你有没有猜对,值得肯定的是,不管是图A还是图B,都笔触清晰且构图丰富多样。真的很难看出到底哪张是人画的哪张是AI画的。
作者不是GAN的专业研究者,却啃了遍原理又造了个小画家,兴趣使然。在此抛砖引玉,只是想把这个令很多人拍案叫绝的模型介绍给更多的读者。就像大家都会谈论Alpha Go,我希望更多的人在聊到人工智能的时候也会提起——「让我们来聊聊GAN吧」。毕竟,如果我现在不写,说不定哪天,就有一个训练出来专门会写数据冰山文的GAN,到时候我也就只能GAN尬了。
至于你问我GAN未来会不会让你失业?
只要把老板交代的活GAN好,应该暂时不会被GAN取代。
更多回答请看: AndrewHuang的知乎主页
特别鸣谢:
张戎的知乎主页
孙竞的知乎主页
(题图:小学生的陶艺作品。摄影:张戎,2018年3月。)
参考资料附录:
论文:
- A Neural Representation of Sketch Drawings:
[1704.03477] A Neural Representation of Sketch Drawings
2. 提出GAN的第一篇论文:
[1406.2661] Generative Adversarial Networks
3. 本文的代码采用的主要方法:
[1704.00028] Improved Training of Wasserstein GANs
4. 生成的高清人像的那篇论文:
[1710.10196] Progressive Growing of GANs for Improved Quality, Stability, and Variation
5. 把低清图片高清化,本文中引用的论文:
[1609.04802] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
6. 文中的风格迁移图片来源,Cycle-GAN:
[1703.10593] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Google通过QuickDraw收集到的数据:
https://console.cloud.google.com/storage/browser/quickdraw_dataset/full/numpy_bitmap/
论文的展示视频片段GIF来源:
https://www.youtube.com/watch?v=G06dEcZ-QTg
推荐的其他有意思的GAN的资料:
台湾大学李宏毅老师的深度学习课程,里面介绍GAN的部分非常清晰明了:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
