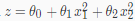Machine Learning(机器学习)之二:juejin.cn/post/684490…
分类问题
要尝试分类,一种方法是使用线性回归并将大于0.5的所有预测映射为1,将所有小于0.5的预测映射为0.但是,此方法不能很好地工作,因为分类实际上不是线性函数。
分类问题就像回归问题一样,除了我们现在想要预测的值只占用少量离散值。现在,我们将重点关注二进制分类 问题,其中y只能处理两个值0和1.(我们在这里所说的大多数也将推广到多类情况。)例如,如果我们正在尝试为电子邮件构建垃圾邮件分类器X (i ) ,如果是一封垃圾邮件,则y可能为1,否则为0。因此,y∈{0,1}。0也称为负类,1表示正类,它们有时也用符号“ - ”和“+”表示。X(i ) ,相应的Y(i ) 也称为训练范例的标签。
假设函数的表达式
我们可以忽略y是离散值的事实来处理分类问题,并使用我们的旧线性回归算法来尝试预测给定x。但是这种方法的效果非常差。
直观地说,当y∈{0,1}时,h θ(x) 取大于1或小于0的值没有什么意义。要解决这个问题,让我们改变假设函数的形式 hθ(x)让它满足
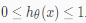
我们的新形式使用“Sigmoid函数”,也称为“逻辑函数”:
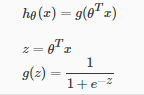

hθ(x)会给出输出为1的概率。例如:hθ(x) = 0.7,意思就是我们的输出为1的概率是70%,我们的预测为0的概率只是我们概率为1的补充(例如,如果它是1的概率是70%,那么它的概率是0 0是30%)。
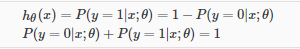
决策边界
为了得到离散的0或1分类,我们可以将假设函数的输出转换如下:
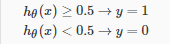
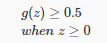
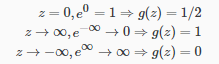
所以
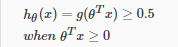
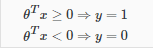
该决策边界是其中y = 0且其中y = 1,这是由我们的假设函数创建分离区域的线条。
示例:
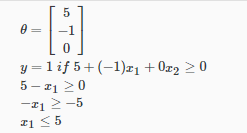
在这种情况下,我们的决策边界是一条直线垂直线放置在图形中X1=5,左边的所有东西都表示y = 1,而右边的所有东西都表示y = 0。
实例:
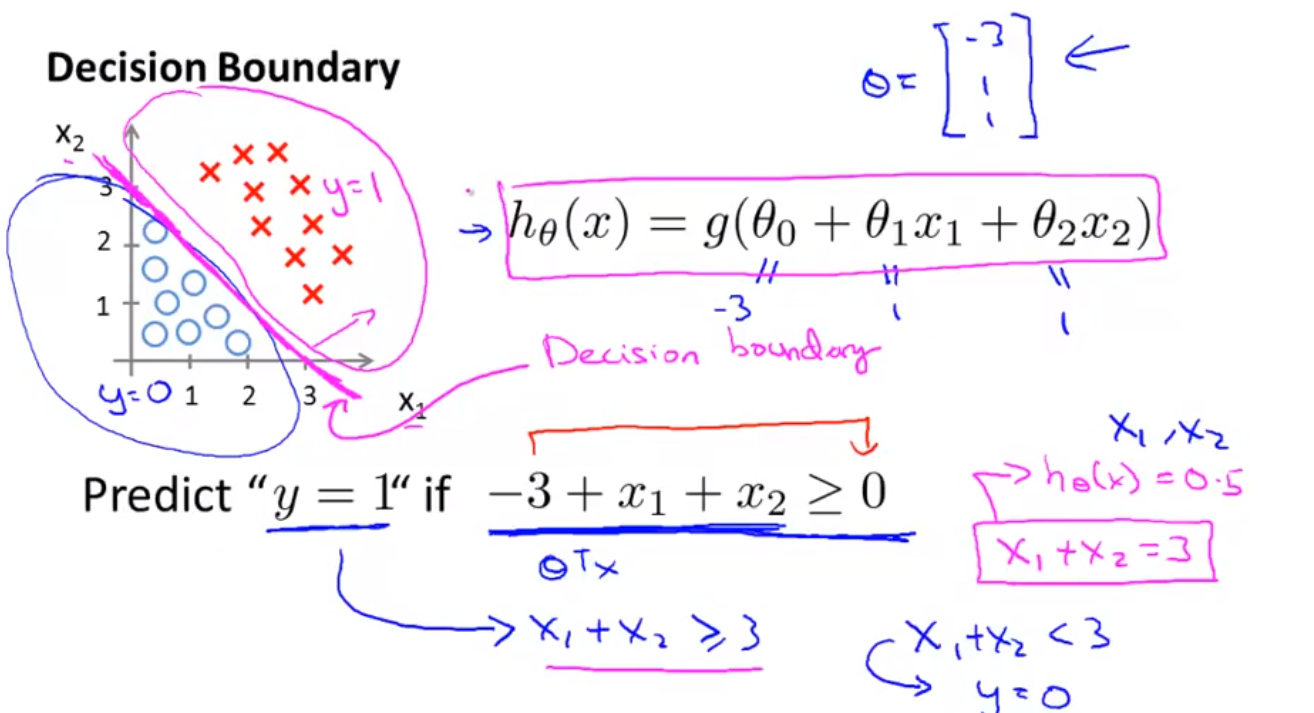
同样,sigmoid函数g(z)的输入(例如,θ^TX)不需要是线性的,并且可以是描述圆的函数(例如,