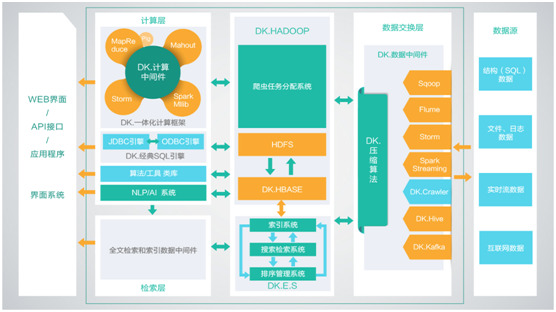
如今有很多公司都在努力挖掘他们拥有的大量数据,包括结构化、非结构化、半结构化以及二进制数据等,来探索对数据的深入利用。 大多数公司估计他们只分析了已有数据的12%,剩余88%还没有被充分利用。大量的数据孤岛和分析能力的缺乏是造成这种局面的主要原因。另外一个难题是如何判断数据是否有价值。尤其是在大数据时代,为了避免数据丢失你必须采集并存储这些数据。一些看起来与业务无关的数据,如手机GPS数据,将来也可能会有大用处。 所以,大量公司都寄希望于使用Hadoop解决如下难题: 采集并存储与公司业务职能相关的所有数据。支撑先进的分析功能,包括商业智能,采用现代方式对数据进行先进的可视化和预测性分析。将数据快速分享给所需之人。整合多个数据孤岛来解答以前根本没人提过,甚至是未知的复杂问题。Hadoop支持解决方案规模的快速、有效扩大,使不断增长的容量、速度以及多样的数据能够得到快速的处理。 如今Hadoop的购买周期正处于上升阶段,因此在该领域催生了越来越多的厂商。尽管Hadoop是Apache的开源项目,任何人都可以免费下载,但大多数消费者还是倾向于采用厂商的打包方案。除了将所有的Hadoop组件打包并保证其能正常使用(兼容版本)之外,厂商一般还会提供企业级支持和扩展:以Apache Hadoop(HDFS)作为方案的核心组件,搭配额外实现增强Hadoop的功能,并增加差异化功能使其解决方案更具吸引力。 在大数据Hadoop解决方案评测中,厂商有Amazon Web Services、Cloudera、Hortonworks、IBM、MapR科技、华为和大快搜索。这些厂商都是基于Apache开源项目,然后增加打包、支持、集成等特性以及自己的创新等内容以弥补Hadoop在企业中的短板。所有厂商都实现了这些功能,尽管方式略有不同——从各厂商的评测得分和厂商资料可见一斑。 大快大数据平台(DKH),是大快搜索为了打通大数据生态系统与传统非大数据公司之间的通道而设计的一站式搜索引擎级,大数据通用计算平台。传统公司通过使用DKH,可以轻松的跨越大数据的技术鸿沟,实现搜索引擎级的大数据平台性能。 DKH,有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。