知识点:
1) zookeeper的基本概念
2) zookeeper的环境搭建
3) zookeeper客户端使用
4) zookeeperAPI的使用
分布式环境特点:
1)分布性 异地多活
2)并发性 程序运行过程中,并发性操作是很常见的,同一个分布式系统中的多个节点,同时访问一个共享资源,如数据库或者分布式存储。 分布式并发是基于多进程
3)无序性 进程之间的消息通信会出现顺序不一致问题
分布式环境下面临的问题
1)网络通信 网络本身的不可靠性 光缆被挖断火灾等等
2) 网络分区 (脑裂)
当网络发生异常,导致分布式系统中部分节点之间的网络遗憾吃不断增大,最终导致分布式架构的所有节点,只有部分节点能够正常通行。
3) 三态
在分布式架构中,除了成功,失败还有一种状态叫超时
4)分布式事务 同时成功同时失败,事务回滚
ACID 原子性 一致性 隔离性 持久性
中心化和去中心化
冷备或者热备
分布式架构里面,很多的架构思想采用的是:当集群发生故障的时候,集群中的人群会自动个选举出一个新的领导。
最典型的就是;zookeeper / etcd
经典的CAP/BASE理论
1)CAP理论
C 一致性 (Consistency) 所有节点上数据,时刻保持一致
A 可用性(Availability) 每个请求都能够收到一个响应,无论响应成功或者失败
P 分区容错 (Partition-tolerance)表示系统出现脑裂以后,可能导致某些server与集群中的其他机器失去联系。
CP / AP
仅仅适用于原子读写的Nosql场景,不适用于数据库系统
2)BASE理论
基于CAP理论,CAP理论并不适用与数据库事务(更新一些错误的数据导致数据紊乱,无论怎样的数据库高可用都是徒劳)XA事务虽然可以保证数据库在分布式系统下的ACID特性,但是会带来性能上的影响。
eBay尝试了一种完全不同的方式:放宽了对事务ACID的要求,提出了BASE理论:
Basically availbale 基本可用 数据库采用分片模式,把100万用户数分布在5个实例上,破坏其中一个实例。仍然可以保证80%的用户可用。
soft-state 软状态 在基于client-server模式的系统中,server端是否有状态,决定了系统是否具备良好的水平扩展,负载均衡,故障恢复等特性。
server端承诺会维护client端状态数据,这个状态仅仅维持一小段时间,这段时间以后,server端就会丢弃这个状态,恢复正常状态。
Eventually consistent 数据的最终一致性
初步认识zookeeper
zookeeper是一个开源的分布式协调服务,是由雅虎创建,基于google chubby。
zookeeper是分布式数据一致性的解决方案。
zookeeper能做什么?
数据的发布/订阅 (配置中心:disconf,watcher机制)
负载均衡(dubbo利用zookeeper机制实现负载均衡)
命名服务
master选举(kafka,hadoop,hbase)
分布式队列
分布式锁
zookeeper特性:
1)顺序一致性
从同一个客户端发起的事务请求。最终会严格按照顺序被应用到zookeeper中
2)原子性
所有的事务请求的处理结果在整个集群中的所有机器的应用情况是一致的,也就是说,要么整个集群的所有机器都成功地应用了某个事务,要么就都不应用。
3)可靠性
一旦服务器成功应用了某一个事务数据,并且对客户端做了响应,那么这个数据在整个集群中一定是同步并且保留下来。
4)实时性
一单一个事务被成功应用,客户端能够立即从服务器读取到事务变更后的最新数据状态。(zookeeper仅仅保证在一定时间内,接近实时)
zookeeper的安装【单机环境下】
1)下载zookeeper的安装包
apache.fayea.com/zookeeper/


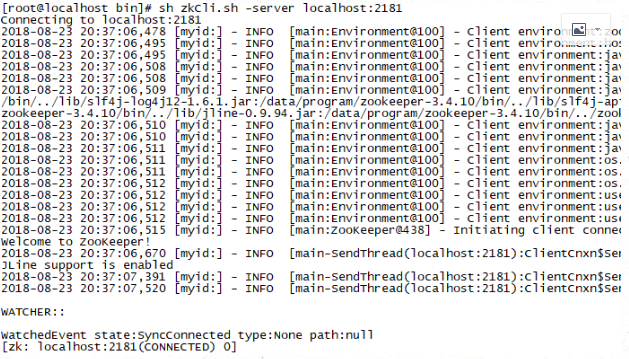
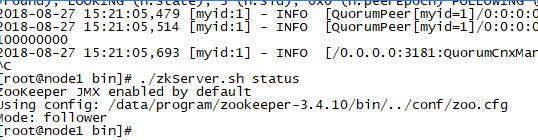
zookeeper的安装【集群环境】 zookeeper集群,包含三种角色:leader/follower/observer
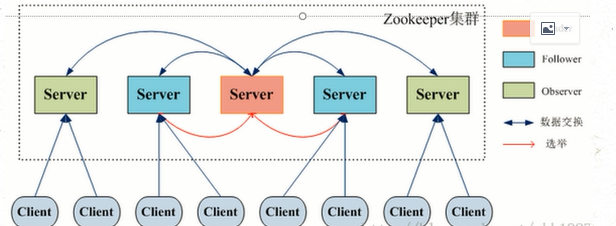
leader:接受所有follower的提案请求并且统一协调发提案的投票,负责与所有的follower进行内部的数据交换(同步) follower:直接为客户端服务并且参与提案的投票,同事与leader进行数据交换(同步) observer:直接为客户端服务但是不参与提案的投标,只是也与leader进行数据交换(同步)
弄个三台服务器 一个master 俩个follower 一台observer
192.168.48.128
192.168.48.130
192.168.48.131
192.168.48.132 observer
首先现在三台服务器上都部署zookeeper,安装步骤如单机的操作
- 修改配置文件 zoo.cfg
在配置文件的尾部加上如下内容
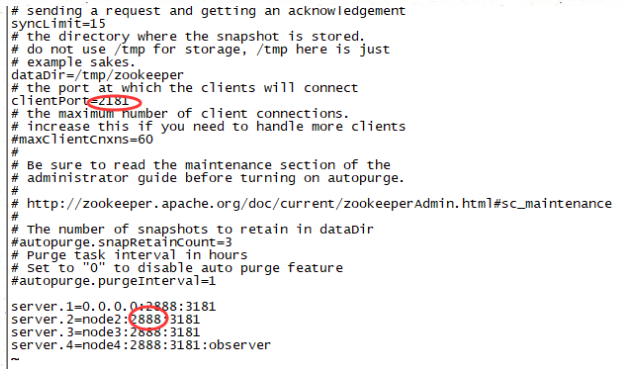
server.id=host:port:port
id的取值范围:1~255 用id来标志该机器在集群中的机器序号
2181是zookeeper的端口号 follower节点跟leader节点交换信息的端口号 不能使用2181 这是客户端访问zookeeper的端口号
3181是leader选举的端口号
server.1=192.168.48.128:2888:3181
server.2=192.168.48.131:2888:3181
server.3=192.168.48.132:2888:3181
2)创建myid
3)启动zookeeper【防火墙先关掉】
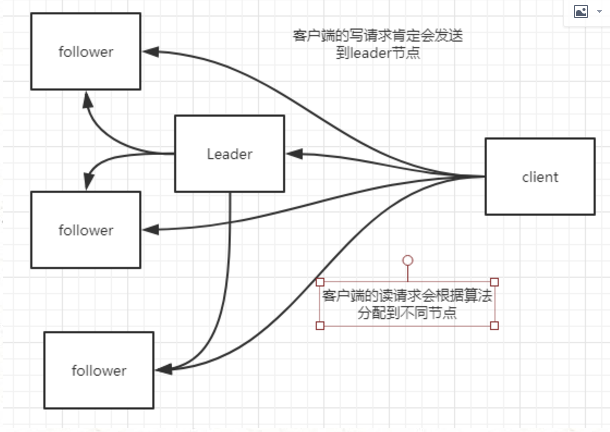
observer是一种特殊的zookeeper节点,可以帮助解决zookeeper的扩展性 大量客户端访问zookeeper集群,需要增加zookeeper集群机器数量,从而增加zookeeper集群性能,导致zookeeper写性能下降。zookeeper的数据变更需要半数以上服务器投票通过,造成网络消耗,增加投票成本。
1)observer不参与投票,只接受投票结果
2)不属于zookeeper的关键部位
如何配置一个observer
1)在zoo.cfg里面增加一行
peerType=observer
2)配置文件尾部增加
server.1=192.168.48.128:2181:3181:observer
leader: