

测试环境:python3.6,MacOS
目标:爬取keep的explore页面图片
发现gotokeep.com本想学习用scrapy-splash框架爬取keep的图片,结果发现只有第一次打开的页面的图片的URL是用js动态加载的,用鼠标滑到底部之后,新加载的页面的图片的URL都是在返回的json数据格式里面,因此直接放弃首页图片获取,直接获取后面新增图片。
第一次加载页面截图:
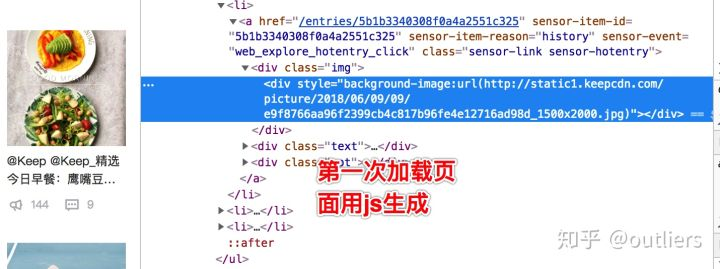
鼠标滑动到底部之后,新增图片和文字:
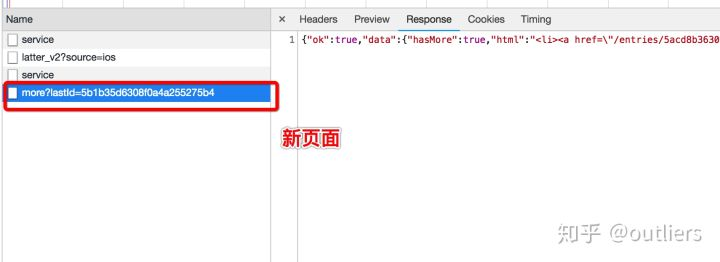
经过分析发现,每次新的request请求有个lastid的参数,这个参数从哪里来呢?初步猜测应该是从首次访问页面返回给浏览器的,应该在response。去response body搜索发现果然在首次返回里面。这很像链表的数据结构,只要找到链表头就可以一环一环的找下去。并且没有js动态加载,使用简单的requests包就可以实现keep图片下载:
获取第一个lastid之后,就可以无限循环下去,初步分析发现每个图片使用hash命名的,目前还没有加图片去重机智,直接用数字给图片命名。用i来控制循环次数,每次访问差不多十多张图片,根据需要控制下载图片总数量。经过测试,i为200时候,下载图片🈶3600多张,一个多G,并且速度很快,没有遇到反爬机制。
domain = "https://gotokeep.com"
response = requests.get("https://gotokeep.com/explore")
# print(response.content)
pattern = re.compile(r'''<div data-url="/explore/more?(.*)" ''')
find_res = pattern.findall(response.text)
more_page_id = find_res[0]
# find_res = pattern.search(response.text)
print(find_res)
last_id_pattern = re.compile(r'''lastId":"(.*?)"}''')
i = 0
while i < 10:
more_page_url = "{0}/explore/more?{1}".format(domain, more_page_id)
response = requests.get(more_page_url)
content = response.text
res = last_id_pattern.findall(content)
more_page_id = res[0]
download_pic(content, i)
i = i + 1下载图片部分:
def download_pic(content, num):
pattern = re.compile(r"""(http://static1.*?jpg)""")
res = pattern.findall(content)
i = 0
for item in res:
print("=" * 40)
print(item)
response = requests.get(item)
with open("./pictures/{0}{1}.jpg".format(num, i), "wb") as f:
f.write(response.content)
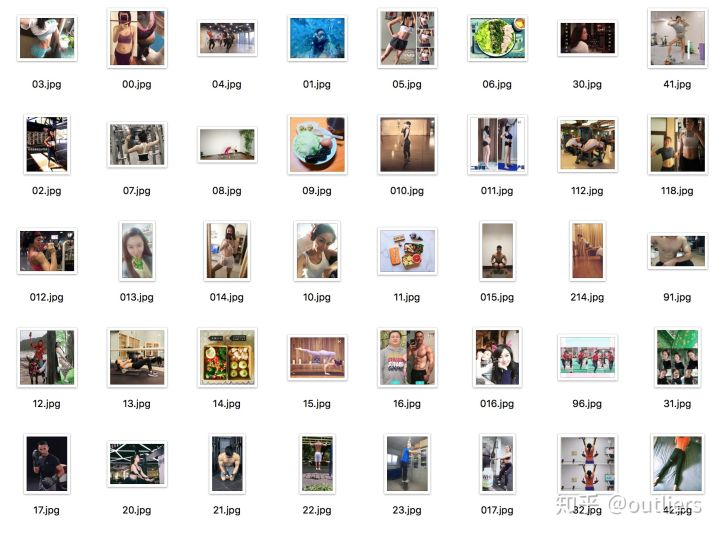
i = i + 1效果截图:
代码地址:
Danielyan86/keep_scrapygithub.com
此文仅作学习交流用,欢迎讨论。
