

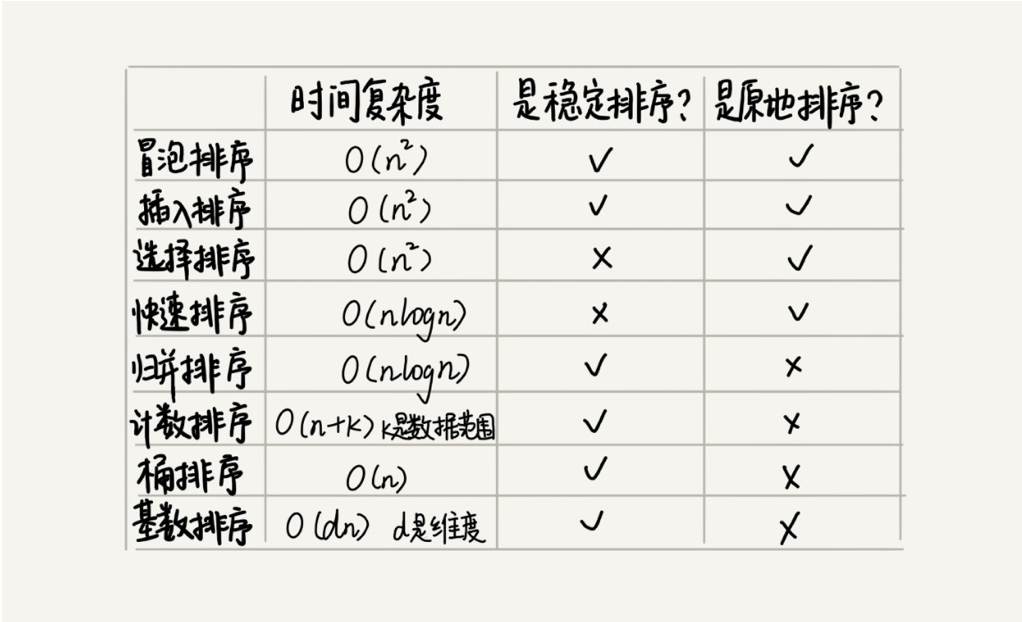
排序比较
优化快速排序
- 快速排序的最坏时间复杂度是O(n2);原因是数据是有序或接近有序的,而每次区分点都选最后一个,则需要交换次数太多,时间复杂度就会退化到O(n2)。 因此这种时间复杂度出现的主要原因还是分区点选的不够合理。 比较常用简单的分区算法:1.三数取中法;2.随机发
- 快速排序使用递归实现的,就可能出现栈溢出的问题。解决办法:1.限制递归深度;2.通过在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈的过程,这样就没有了系统栈大小的限制。
排序函数
C中qsort()函数的实现: qsort优先使用归并排序,如果数据量过大的话,再使用快速排序;
快排的分区点的选择是“三数取中法”;
对于递归太深导致栈溢出的问题,qsort是通过自己实现一个堆上的栈,手动模拟的。
在递归的过程中,当要排序的数据区间中,元素个数<=4时,退化为插入排序,不再用递归(在小规模数据的情况下,O(n2)和O(nlogn)就差不多了)。
因此实际的排序函数,具体情况具体分析。
