

今天Flood和大家分享一下Chelsea Finn的博士论文赏析。
Chelsea Finn,想必很多人还是很熟悉的,可以说是AI圈最牛逼的博士之一吧。我也算是自来粉,虽然曾经的paper还被她弊了,但是她的paper我都看啊。
所以我们来看看她的博士论文,吊炸天的博士论文,应该还是可以有所启发的。

她的博士论文名称叫Learning to Learn with Gradients,大家Google一下可以找到原文。
看到这个名称,我的第一感觉是她真的对自己的MAML及之后基于MAML的各种应用有一个非常深刻的理解。MAML的方法可以说是Meta Learning三大方法之一,另外两个方法就是conditional neural network条件神经网络及neural network parameter generator神经网络参数生成,具体我们可以单独开一个blog说。MAML的特点在于通过梯度下降的方法来Learning to Learn。想来还是蛮特别的,所以很多应用本来加个条件神经网络加以处理,改用MAML就显得很fancy。
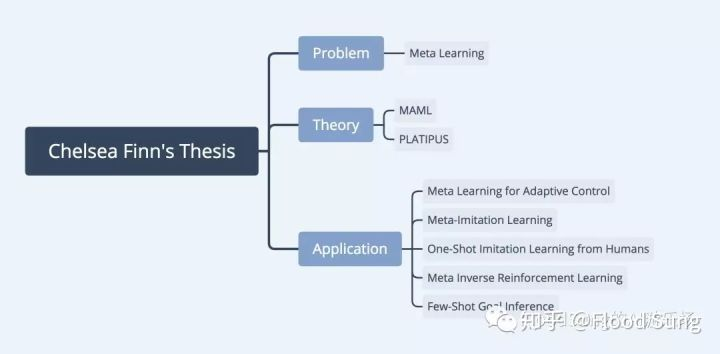
现在我们来说说Chelsea Finn的工作。她的工作给人的感觉就是非常的完整solid,简单的说就是:
1)选择一个新问题
2)构造一个新的方法论
3)基于新的方法论做应用
Chelsea Finn完美的做到了。她的博士论文简直就是一个Meta Learning或者MAML的教程。MAML现在的影响力非常大,虽然方法论看起来真的非常简单。但可能也是正因为简单,所以大家都在用。某种程度上,MAML可以类比Ian Goodfellow提出的GAN,都是各种领域的一个全新方法,并且基本原理都非常简单,只是GAN可以做出很酷炫的视觉效果,而MAML在Meta Learning上相对比较局限,特别是Chelsea Finn只是在Robot Learning领域上做,不过也足够酷了。这确实是一个顶级PhD做出来的事情,很佩服。
那么看她的博士论文,我们应该思考什么问题呢?
1. 为什么选择Meta Learning这一研究方向?
2. 为什么构造出MAML这一通用Meta Learning算法?
3. 为什么选择做这些robot learning的应用?
Meta Learning一开始只是在Few-Shot Learning问题上做,然后当时Reinforcement Learning这块大家最大的质疑恐怕就是测试集就是训练集本身(比如玩Atari游戏,就只是在Atari这个游戏本身上玩高分)。那Reinforcement Learning如果才能在新的任务中学的更好,更快呢?这就不知不觉演变成了Fast Reinforcement Learning的问题,而具体看就是Meta Learning的问题设定了。所以,Chelsea Finn显然是看到了这个问题的潜力,所以就来做了Meta Learning。而事实也充分证明了Chelsea Finn选择这个课题的眼光是非常好的,现在Meta Learning已经成为一个非常火的话题了,今年的ICLR19投稿的Meta Learning文章有70多篇,是Reinforcement Learning的一半。估计到明年会全领域大火。就如我之前说的,Meta Learning是一个通用的深度学习涡轮增压器,什么问题都可以加。
选择一个有潜力的研究方向,可能就成功了一大半了。然后就是Chelsea Finn的超强实力,提出了MAML这一全新的Meta Learning方法。当我分析Meta learning的三大方法论的时候,我觉得MAML并不是最好的方法,毕竟它需要二次梯度,训练速度慢,并且数据样本必须有loss来做梯度下降(老实说就因为二次梯度这一点,让MAML很难做到large scale,这可能是Chelsea会去解决的问题。OpenAI提出Reptile简化MAML但是在RL上效果并不好,甚至不如简单joint-training)。相比之下可能条件神经网络什么都能做。但是条件神经网络一听好土啊,这就是Meta Learning了?大家会不屑,但是MAML一听,很酷很Fancy。Chelsea Finn还用强大的理论能力证明MAML和其他方法一样,具有通用性,能够逼近任意一个函数。这就奠定了MAML的江湖地位了。然后我们必须承认,能想到MAML其实很不容易的事情,需要对Meta Learning有一个很深刻的认识,而这一点Chelsea Finn应该是比大多数人都超前了。
有了MAML这个理论基础之后,Chelsea Finn或者整个Sergey Levine团队都开启了疯狂水paper的模式。把Robot Learning中的Imitation Learning,Reinforcement Learning等各个环节都变成Few-Shot Learning或者Fast Adaptation问题加以研究。而Chelsea自己则在Few-Shot Imitation Learning上做得非常强,把MAML的用处发挥得淋漓尽致,在One-Shot Imitation Learning from Demonstration上得到完美体现。
做完Few-Shot Imitation Learning,Chelsea Finn又开始做Meta Inverse Reinforcement Learning及Few Shot Goal Inference,说白了就是学一个meta reward function,只要少量样本,就能学到一个reward function,然后用RL训练。这种思路倒是相比之下比较容易想到了。但是Sergey Levine他们团队的研究连续性让其他研究团队基本没有任何机会了,这也导致Meta Robot Learning这一块的问题全部让他们做了。
从Chelsea Finn几年的研究看下来,真的是自己挖个大坑,然后疯狂填坑。这确实是大神才能做出来的事情。
对我们Researcher来说可以有什么启发呢?
1. 选对研究方向确实是最重要的。Meta Learning with Robot Learning恐怕是很难做了,但是如果你做Meta Learning with NLP还可以做,或者Multi Agent Meta Learning也可以做。或者当然了,最好是选择一个更新的更没有人想到去做的问题。比如Meta Learning的下一步是什么?
2. 构建自己的理论根基然后再做更具体更细的应用。这当然是非常非常难的事情了。但是实际上很多大神及公司都是这么做的。比如DeepMind,在DQN上开发了多少新版本。然后个人的话很类似的就是DeepMind的Adam Santoro,自从提出了relational network之后,就疯狂在这上面水paper了。
最后就是Meta Learning的理论层面就只有这样了吗?
我觉得不然。
说白了Meta Learning就是要学习一个y = F(D,x;theta) 这样一个函数,F是神经网络,theta是对应的参数。D是训练样本,x是当前输入。对于这样一个神经网络,怎么学才能学的更好?我们可以改网络结构,可以改训练模式。MAML在Few-Shot Learning也早已不是最好的方法,所以在RL上,在Robot Learning也没有道理只用MAML来做。我想这些都是值得去研究的。
今天的赏析就到这里,感谢大家的阅读与支持!
最后,欢迎大家关注本人公众号:FloodSung的AI游乐场,可以扫描顶部图片的二维码,本人所有文章都将在公众号优先发布!谢谢!
