

Kafka源码系列之Broker的IO服务及业务处理
一,kafka角色
Kafka源码系列主要是以kafka 0.8.2.2源码为例。以看spark 等源码的经验总结除了一个重要的看源码的思路:先了解部件角色和功能角色,然后逐个功能请求序列画图分析,最后再汇总。那么,下面再啰嗦一下,kafka的角色。kafka在生产中的使用,如下图。
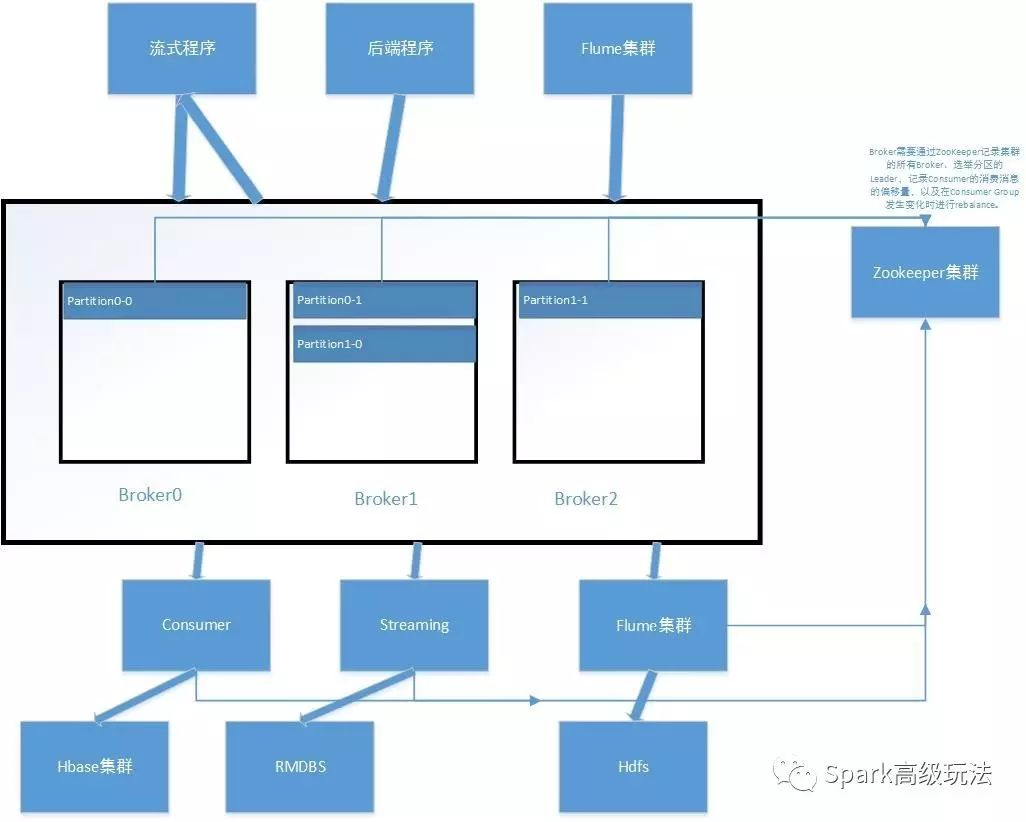
从图中可以看到其主要角色:
1,Zookeeper:Broker需要通过ZooKeeper 记录集群的所有Broker,controller等信息,记录Consumer 的消费消息的偏移量等信息。
2,Broker:主要负责管理数据,处理数据的生产、消费请求及副本的同步等信息。
3,Topic:标识一个类别的消息。
4,Partition:针对topic进行了进一步细分,增加并发度。牵涉到副本及 leader选举。
5,Producer:主要与Broker进行交互,来生产消息到 broker。
6,Consumer:主要是从Broker上获取消息,将自己的消费偏移等信息记录与 zookeeper。
从各个角色的功能来看,我们整个数据服务请求的中心就是Broker,自然也是由Broker来负责各种事件处理及应答各个部件的。
二,Broker请求及应答机制的实现
在JAVA的网络IO模型彻底讲解的那篇文章里,已经彻底讲解了 Java的各种网络IO实现的机制及优缺点。其实,kafka的 Broker就是通过JAVA的NIO来实现监听和请求处理及应答的。
主要牵涉到的类:
1),KafkaServer
该类代表了一个kafka Broker的生命周期,处理kafka启动或者停止所需要的所有功能。
2),SocketServer
一个NIO 服务中心。线程模型是
1个Acceptor线程,用来处理新的链接请求
N个加工Processor线程。每个线程拥有一个他们自己的selector ,主要负责IO请求及应答。
3),KafkaRequestHandler
实际会在KafkaRequestHandlerPool中创建多个对象,负责加工处理request线程。
会创建M个处理Handler线程。负责处理request 请求,将responses重新写会加工线程Processor,以便于其写回给客户端。
4),RequestChannel
该类主要是封装了requestQueue,responseQueues, responseListeners,便于个各类中同时引用并作出自己的处理。
5),KafkaApis
Kafka多样请求的逻辑处理程序。
具体如图:
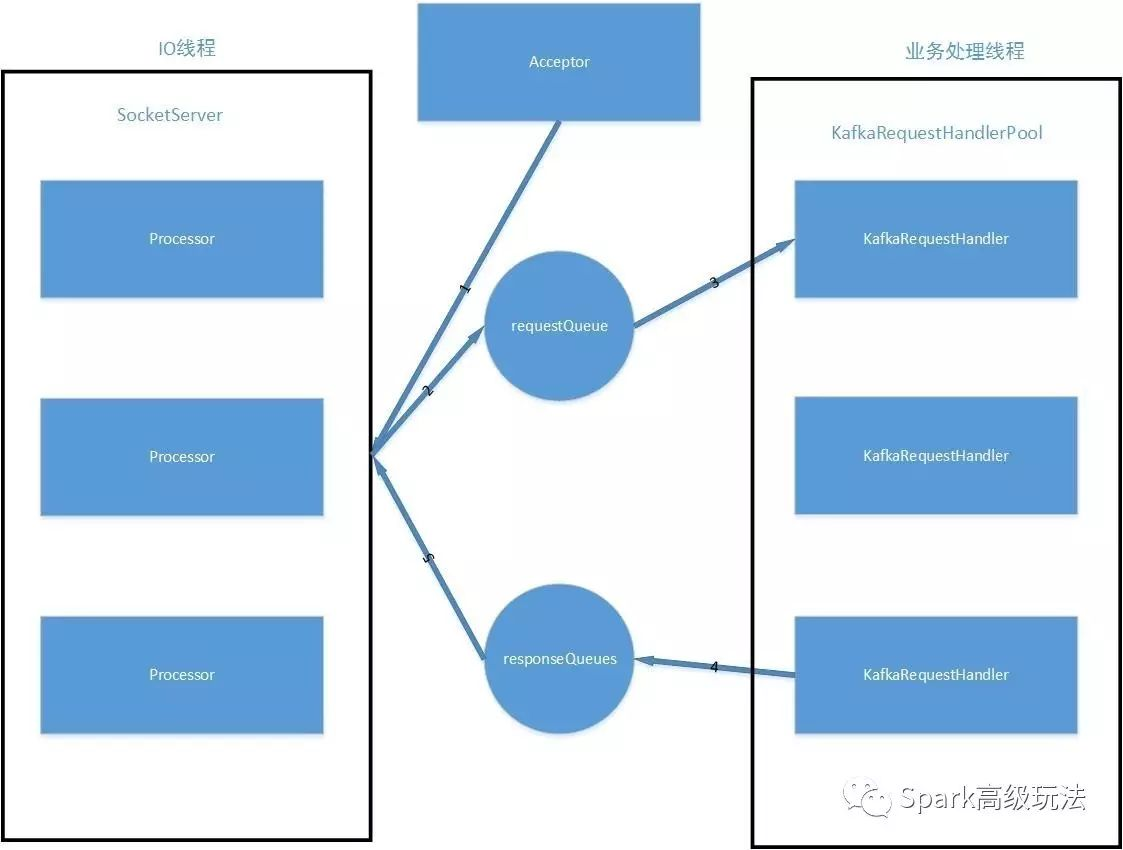
下面讲解1,2,3,4,5,具体含义:
1,SocketServer.startup(),会启动一个后台线程,该线程会持有一个acceptor ,负责接收新的链接请求,并轮训所有的Processor,将新的链接请求加入Processor对象的成员变量ConcurrentLinkedQueue 里,Processor会在其run方法里面处理。
// start accepting connectionsthis .acceptor = new Acceptor(host, port, processors , sendBufferSize, recvBufferSize , quotas)Utils.newThread ("kafka-socket-acceptor", acceptor , false).start() acceptor.awaitStartup
Processor池的初始化
for(i <- 0 until numProcessorThreads) { processors (i) = new Processor(i, time , maxRequestSize, aggregateIdleMeter , newMeter("IdlePercent", "percent" , TimeUnit.NANOSECONDS , Map("networkProcessor" -> i.toString)), numProcessorThreads, requestChannel , quotas, connectionsMaxIdleMs) Utils.newThread ("kafka-network-thread-%d-%d".format(port , i), processors (i), false ).start()}
accepttor轮训Processor
val ready = selector.select(500)if(ready > 0) { val keys = selector.selectedKeys() val iter = keys.iterator() while(iter.hasNext && isRunning) { var key: SelectionKey = null try { key = iter.next iter.remove() if(key.isAcceptable) accept(key, processors(currentProcessor)) else throw new IllegalStateException("Unrecognized key state for acceptor thread.") // round robin to the next processor thread currentProcessor = (currentProcessor + 1) % processors.length } catch { case e: Throwable => error("Error while accepting connection", e) }
2,Processor的run方法里面,会针对可读事件调用 read方法里将request请求信息通过requestChannel.sendRequest(req)添加到 RequestChannel的成员变量里面。
requestQueue = new ArrayBlockingQueue[RequestChannel.Request](queueSize)
3,在KafkaServer的startup 方法里面构建KafkaRequestHandlerPool对象的时候,会构建若干handler线程。
for(i <- 0 until numThreads) { runnables (i) = new KafkaRequestHandler(i , brokerId, aggregateIdleMeter , numThreads, requestChannel , apis) threads (i) = Utils.daemonThread( "kafka-request-handler-" + i, runnables (i)) threads (i).start()}
在KafakRequestHandler的方法里面会对我们的request进行处理
req = requestChannel.receiveRequest(300) apis.handle(req)
实际上,是通过KafkaApis对象的handle方法进行各种逻辑的处理的。
def handle(request: RequestChannel.Request) { try{ trace("Handling request: " + request.requestObj + " from client: " + request.remoteAddress) request.requestId match { case RequestKeys.ProduceKey => handleProducerOrOffsetCommitRequest(request) case RequestKeys.FetchKey => handleFetchRequest(request) case RequestKeys.OffsetsKey => handleOffsetRequest(request) case RequestKeys.MetadataKey => handleTopicMetadataRequest(request) case RequestKeys.LeaderAndIsrKey => handleLeaderAndIsrRequest(request) case RequestKeys.StopReplicaKey => handleStopReplicaRequest(request) case RequestKeys.UpdateMetadataKey => handleUpdateMetadataRequest(request) case RequestKeys.ControlledShutdownKey => handleControlledShutdownRequest(request) case RequestKeys.OffsetCommitKey => handleOffsetCommitRequest(request) case RequestKeys.OffsetFetchKey => handleOffsetFetchRequest(request) case RequestKeys.ConsumerMetadataKey => handleConsumerMetadataRequest(request) case requestId => throw new KafkaException("Unknown api code " + requestId) } } catch { case e: Throwable => request.requestObj .handleError(e, requestChannel, request) error("error when handling request %s" .format(request.requestObj ), e) } finally request.apiLocalCompleteTimeMs = SystemTime.milliseconds }
4,在每一种请求处理结束之后会产生对应的response
requestChannel.sendResponse(new RequestChannel.Response(request , new BoundedByteBufferSend(response)))
并将response存储到RequestChannel的 responseQueues存储。
5,最终,由我们的Processor在其run 方法里面,取出RequestChannel的responseQueues存储的时间,匹配到写事件,然后通过其write 方法对具体的request进行应答。
else if(key.isWritable) write(key)
三,总结
这是一个典型的Reactor多线程模型,并且实现了IO线程和业务线程进行隔离。这样做的优点有以下几种 :
1,充分利用资源
可以充分利用CPU资源,增加并发度,使业务响应速度加快。
2,故障隔离:
业务处理线程,无论是处理耗时,还是发生阻塞,都不会影响IO请求线程。保证服务器能在某些业务线程出故障的情况下,正常进行IO请求应答。
3,可维护性
职责单一,可维护性高,方便定位问题。
此处再次建议大家仔细阅读,浪尖关于JAVA的网络IO模型彻底讲解那篇文章,彻底领会其意境。
此乃,原创。欢迎大家扫描二维码,关注浪尖微信公众号,大家共同进步。

