并行工作者模式:
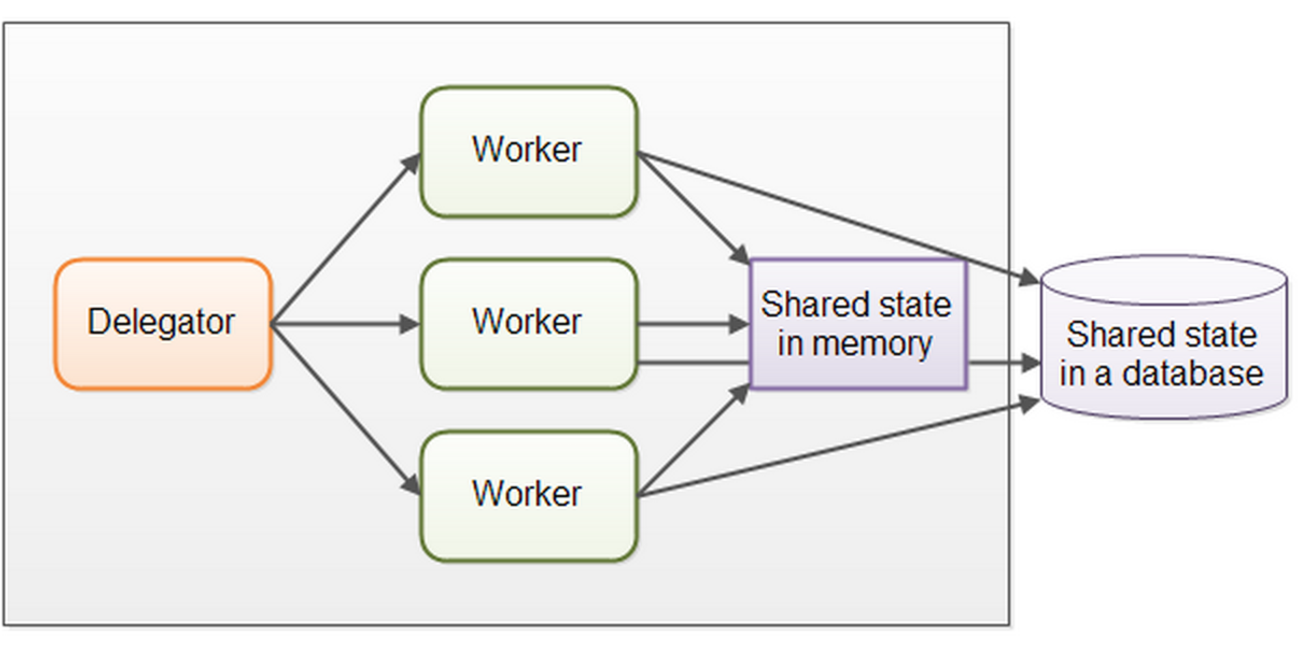
并行工作者模型虽然容易理解,只需添加更多的工作者就可以提高性能。但也有缺点: 1.多个工作者需要共享数据,如果A工作者和B工作者共享了内存,那么每个工作者为了保持所操作的是最新数据版本,在每次调度之前都需要进行重新载入,刷新。 2.无法保证执行顺序,例如作业A在作业B之前被分配了,但是执行顺序是B->A。 3.如果在存储中使用了阻塞的数据结构,那么同一时间只能允许一个线程来对数据结构进行操作,降低了并行性。 Java中的Executor属于并行工作者模型,在使用时,我们指定某个Task给某个线程来运行。如果对于线程A来说,他同时需要负责计算工作与IO工作,则线程A可以自己进行工作的切换,在遇到IO工作时先处理计算工作。
流水线模型(pipline):
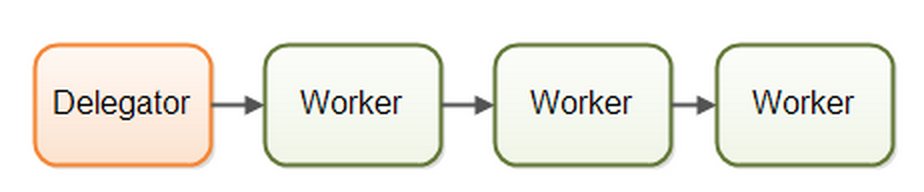
那么,流水线工作者有何优点?
1.无需共享状态,工作者分工明确,无需考虑因并发而带来的共享数据的问题。例如:不同工序的工人所使用的工具肯定不同,不是共享的。
并发模型的选择:
如果作业本身就是并行的、独立的并且没有状态共享。就可以使用并行工作者模式。例如:在消息中间件场景中,我们常常使用kafka作为消息队列,producer生产并发送消息,consumer获取消息进行消费,consumer消费任一条消息的过程都是独立的。
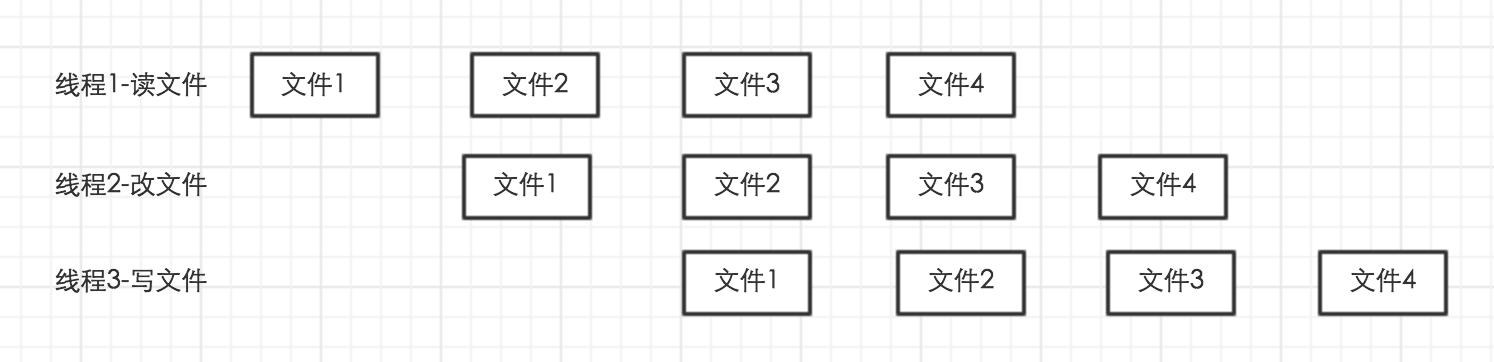
如果作业本身不是并行的、非独立的,就可以使用流水线工作模式。例如:我们需要将一大批文件由小写改成大写,就可以分出3个步骤:1.读文件。2.改大小写。3.写文件。