

首先介绍一下什么是yarn资源管理器:
YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度。 其核心出发点是为了分离资源管理与作业调度/监控,实现分离的做法是拥有一个全局的资源管理器(ResourceManager,RM),以及每个应用程序对应一个的应用管理器(ApplicationMaster,AM),应用程序由一个作业(Job)或者Job的有向无环图(DAG)组成。
YARN可以将多种计算框架(如离线处理MapReduce、在线处理的Storm、迭代式计算框架Spark、流式处理框架S4等) 部署到一个公共集群中,共享集群的资源。
简而言之,可以提供如下功能:
- 资源统一的管理和调度
集群中所有节点的资源(内存、CPU、磁盘、网络等)抽象为Container。计算框架需要资源进行运算任务时需要向YARN申请Container, YARN按照特定的策略对资源进行调度进行Container的分配
- 资源隔离
YARN使用了轻量级资源隔离机制Cgroups进行资源隔离以避免相互干扰,一旦Container使用的资源量超过事先定义的上限值,就将其杀死。
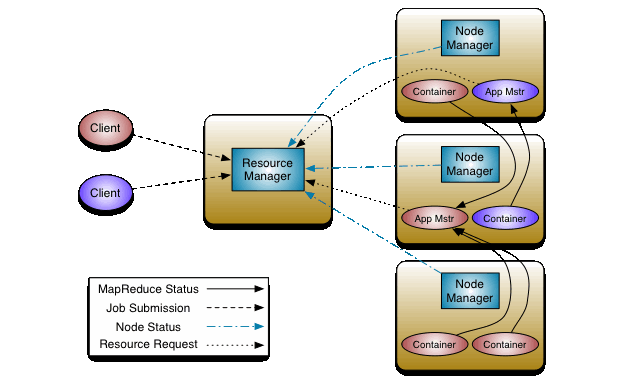
贴一张随处可见的yarn的架构图
下面直接带大家配置hadoop的yarn资源管理
第一步,配置master主节点
进入到hadoop的目录下的/etc/hadoop里,编辑yarn-site.xml文件
vi yarn-site.xml
默认里面都是空的,在configuration标签内配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value> //resourcemanager的主机
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
然后编辑mapred-site.xml文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置mapreduce作业的资源管理框架为yarn
第二步 配置slave从节点
进入到slave从节点的hadoop的目录下的/etc/hadoop里,编辑yarn-site.xml文件
vi yarn-site.xml
默认里面都是空的,在configuration标签内配置
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value> master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> master:8031</value>
</property>
在从节点里配置好master节点的资源管理地址,保证slave从节点可以找到master主节点里的resourcemanager资源管理器
同时为了保证MapReduce作业能够正常运行还需要配置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
然后就可以启动yarn资源管理器了。仍然可以通过集群的方式启动,在master节点中执行以下命令
start-yarn.sh 启动yarn集群
stop-yarn.sh 停止yarn集群
可以看到
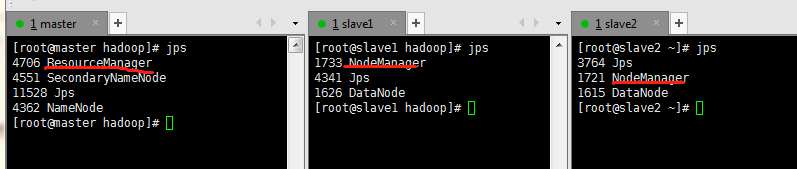
yarn集群已经成功启动了。一般我们会先启动hadoop集群start-dfs.sh,再启动yarn集群start-yarn.sh.也可以通过start-all.sh命令可以一键全部启动。
