

目录
背景介绍
JVM知识回顾
ES配置说明回顾
现状分析
调优实战
总结与展望
一. 背景介绍
项目中的服务集成了springboot-admin做服务监控,最近一直收到邮件告警,提示es出错。错误信息如下:
org.elasticsearch.ElasticsearchTimeoutException: java.util.concurrent.TimeoutException: Timeout waiting for task.
频繁收到这个告警,所以决定花时间研究一下。从报错信息看,并发超时异常。ES作为java开发的中间件,我们没有对任何代码做过修改,所以就从JVM开始着手尝试解决,同时还涉及到部分ES知识和springboot的知识。
二. JVM知识回顾
可参考另一篇学习笔记: 深入理解java虚拟机
1. JVM内存模型
- JVM gc的对象:堆
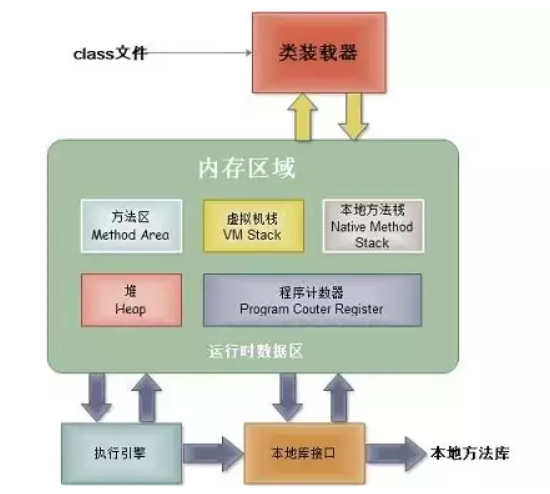
2. 堆内存
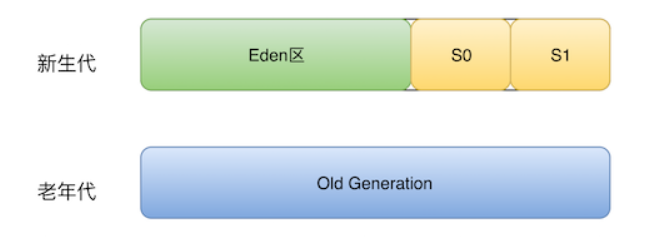
2.1 堆内存划分
- 堆区分为新生代和老年代
- 新生代又分为Eden区,from survivor区,to survivor区
- Eden区和两块较小的survivor空间。大小比例为8:1:1
- java8已经没有持久代了,改为元数据区,主要存放元数据,例如Class、Method的元信息,与垃圾回收要回收的Java对象关系不大
2.2 堆内存查看
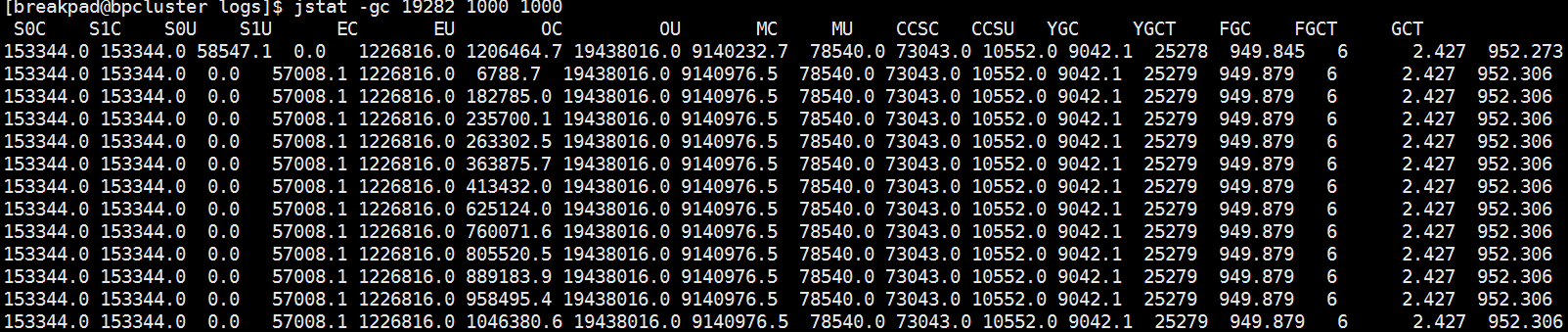
使用 jstat -gc(-gccapacity, -gcutil)命令查看堆分配情况
- S0C:survivor0区总内存大小(Capacity)
- S1C: survivor1区总内存大小
- S0U: survivor0区当前内存大小(Used)
- S1U: survivor1区当前内存大小
- EC:Eden区总内存大小
- EU:Eden区当前内存大小
- OC:老年代总内存大小
- OU:老年代当前内存大小
- MC:meta data区总内存大小
- MU:meta data区当前内存大小
2.3 内存分配和回收策略
2.3.1 分配策略
- 大部分对象创建时,在eden区分配
- 大的对象直接进入老年代,比如很长的字符串或数组。这些对象对垃圾回收不友好。
- 长期存活的对象,将从新生代晋升到老年代
2.3.2 回收策略
- eden区满:触发一次minor gc,存活的对象复制到其中一个survivor。对象的年龄+1
- 一个survivor区满:满足晋升条件的,进入老年代。不满足的,复制到另一个survivor区
2.3.3 晋升条件的判断
- Serial和ParNew GC中通过MaxTenuringThreshold参数设定,默认为15
- Parallel收集器自动调整年龄:survivor空间中相同年龄所有对象大小大于空间的一半,大于等于该年龄的对象就直接进入老年代
2.3 关于堆划分的思考
2.3.1 大堆和小堆堆程序的影响
- 堆太大:垃圾回收时STW的时间过长,影响程序响应时间。据说ZGC(java11发布)回收器能解决这个问题。java11中ZGC的介绍
- 堆太小:垃圾回收太频繁
2.3.2 为什么要划分为不同的年代
- 每个对象的生命周期是不一样的,将不同存活时间的对象划分到不同的区,然后采用不同的垃圾回收算法
- java很多对象都是朝生夕死的,这些对象不会进入老年代。
2.3.3 为什么要有survivor区
- 没有survivor区,只有eden区的话,每进行一次minor gc,对象就被送入老年代。很容易触发full gc,影响性能
- survivor存在的目的就是减少送入老年代的对象数量,减少full gc的发生
2.3.4 为什么要设置两个survivor区
每次minor gc,通过将eden和一个survivor的内容复制到另一个survivor, 避免碎片化问题
3. 垃圾回收算法
3.1 标记-清除算法
- 最基础的收集算法
- 分为标记和清除两个阶段
- 不足之处:
- 效率问题
- 产生大量不连续的内存碎片
3.2 复制算法
- 将内存分为大小相等的两块,每次使用其中的一块
- 一块用完时,将存活的对象复制到另一块
- 现代虚拟机新生代都用该算法
- 不足:
- 内存利用率不高
3.3 标记-整理算法
- 对象存活率高时大量的复制会影响效率,老年代使用该算法
- 标记过程与标记-清除算法一样
- 后续步骤并不是清理对象,而是让所有存活的对象都向一段移动,清理边界以外的内存
3.4 分代收集算法
- 根据对象存活周期不同,采用不同的收集算法
- 新生代大量对象死亡,少量存活,采用复制算法
- 老年代对象存活率高,采用标记-清理或者标记-收集算法
4. 垃圾回收器
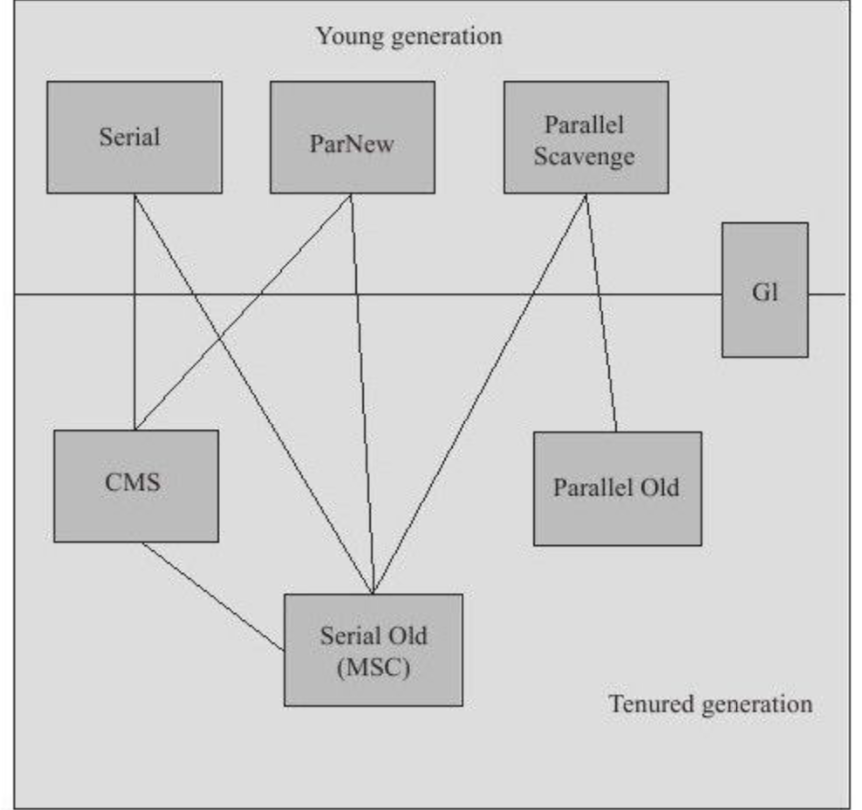
4.1 年代划分
- 新生代收集器有:Serial,ParNew,Paraller Scavenge
- 老年代收集器有:CMS Serial old,Parallel Old
- G1收集器可作用与新生代和老年代
- 没有连线的两个收集器不能共存,比如CMS和Paraller Scavenge
4.2 工作机制划分
- 串行收集器:Serial,Serial Old,单线程的一个回收器,简单、易实现、效率高
- 并行收集器:ParNew,Serial的多线程版,可以充分的利用CPU资源,减少回收的时间
- 吞吐量优先收集器:Parallel Scavenge
- 并发收集器:CMS(Concurrent Mark Sweep),停顿时间少优先,基于“标记-清除”算法实现。
4.3 其他说明
- java11 新出了一款ZGC收集器,性能比G1更高效(还在实验阶段)
- java5默认采用CMS收集器,java9默认收集器被G1代替
- 用户可自己指定使用哪种垃圾收集器
- 各个垃圾收集器详细介绍参考深入理解java虚拟机
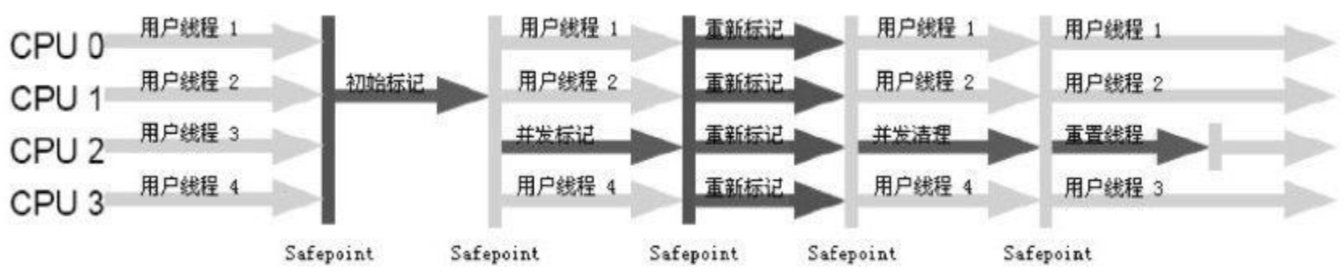
4.4 CMS工作原理
- 不会等到老年代空间快满了才回收(和用户线程并发,留内存给用户线程)。配置参数为-XX:CMSInitiazingOccupanyFraction。默认为75%
- 使用标记-清除算法。整个过程分为四步:
- 初始标记:STW,标记GC Roots能关联到的对象,速度很快
- 并发标记:GC Roots Tracing过程。耗时。和用户线程一起执行(并行)
- 重新标记:STW,标记并发标记过程中程序运行导致标记变化的对象,时间比初始标记长,远比并发标记短
- 并发清除:耗时。和用户线程一起执行(并行)
三. ES配置说明回顾
可参考另外一篇笔记:Elasticsearch学习笔记
主要介绍es官网手册特别说明的一些注意点
1. 关于配置的说明
1.1 ES使用的垃圾回收器
- 默认为CMS,2.x版本官方推荐不要修改为G1,某些版本JAVA G1存在的Bug,会造成Lucene的段文件损坏。
- 不过5.x以及之后版本,没有明确说推荐或不推荐G1,默认还是用的CMS
1.2 ES内存分配要求
- 不超过32G。因为每个对象的指针都变长了,就会使用更多的 CPU 内存带宽,也就是说你实际上失去了更多的内存。
- 不要超过内存的一半,因为Lucene也需要内存,且这些内存不被JVM管理
- 如果不需要对分词做聚合运算,可降低堆内存。堆内存越小,Elasticsearch(更快的 GC)和 Lucene(更多的内存用于缓存)的性能越好。
2. 关于滚动重启的说明
- 保证不停集群功能的情况下逐一对每个节点进行升级或维护
- 先停止索引新的数据
- 禁止分片分配。cluster.routing.allocation.enable" : "none"
curl -XPUT http://{ip}:9200/_cluster/settings -d' { "transient" : { "cluster.routing.allocation.enable" : "none" } }' - 关闭单个节点,并执行升级维护
- 启动节点,并等待加入集群
- 重启分片分配。cluster.routing.allocation.enable" : "all"
curl -XPUT http://{ip}:9200/_cluster/settings -d' { "transient" : { "cluster.routing.allocation.enable" : "all" } }' - 对其他节点重复以上步骤
- 恢复索引更新数据
四. 现状分析
1. 版本及硬件情况介绍
- java:1.8.0_131
- elasticsearch:5.5.1
- es集群:4个数据节点
- os: centos7 24核 128G
- 垃圾回收器:老年代(CMS)+ 新生代(ParNew)
2. 目前堆分配情况
要针对jvm调优,必不可少的是先查看堆内存状况,有以下几种查看方法
2.1 jstat -gc命令查看堆分配情况
2.2 统计ES各个节点堆分配信息
| 节点 | 堆总大小 | 新生代 | survivor | eden | 老年代 | 元数据区 |
|---|---|---|---|---|---|---|
| 节点A | 32G | 1.46G | 0.146G | 1.16G | 30.5G | 81M |
| 节点B | 32G | 1.46G | 0.146G | 1.16G | 30.5G | 85M |
| 节点C | 32G | 1.46G | 0.146G | 1.16G | 30.5G | 81M |
| 节点D | 20G | 1.46G | 0.146G | 1.16G | 18.5G | 76M |
3. 监控工具对比
| 工具名称 | 各分区情况 | 数据是否直观 | 是否可查看历史数据 | 是否免费 | 备注 |
|---|---|---|---|---|---|
| jstat | 是 | 否 | 否 | 是 | 主要用于查看各分区大小 |
| ElasticHQ | 否 | 是 | 否 | 是 | 主要用于浏览es整体信息 |
| cerebro | 否 | 是 | 否 | 是 | 主要用于浏览es整体信息 |
| x-pack | 否 | 是 | 是 | 试用期一年 | 试用期到相关功能不可用,不影响现有功能。6.3版本x-pack已经开源,后续版本可能会免费 |
- 由于线上报异常邮件的时间是不确定的,不可能随时盯着监控面板看,所有必须有查看历史数据的功能,因此x-pack是我们监控的首选工具
- x-pack监控功能只是其中之一,但是真的非常强大,强烈推荐!!同时期待ES官方尽快使之免费
- 网上有破解x-pack的方法,将jar包反编译之后修改代码,再打包回去,还没做尝试。
x-pack安装过程的一些小问题总结
第一步:证书申请
- register.elastic.co/marvel_regi…
- 填写信息后,得到一个json文件,导入到es中, 有效期一年。
curl -XPUT 'http://{ip}:9200/_xpack/license?acknowledge=true' -H "Content-Type: application/json" -d @sivabalan-nagarajan-2327c0fa-f56b-443a-a3d6-abef7ecf2220-v5.json
第二步:安装x-pack插件, 包括es和kibana
./bin/kibana-plugin install x-pack 安装很慢,先把文件下载下来,用下一个命令安装
./bin/elasticsearch-plugin install file:///home/breakpad/softs/x-pack-5.5.1.zip
第三步:修改配置文件
es配置文件里,只启用监控功能
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
kibana配置文件里,只启用监控功能
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.reporting.enabled: false
报错问题解决
rpm安装后,systemctl方式启动kibana报权限不足的问题?
- 卸载x-pack,以kibana用户去安装 sudo -u kibana bin/kibana-plugin install file:///usr/share/kibana/x-pack-5.5.1.zip
- 还是报权限错误,修改报错的文件权限都为kibana
- 安装包权限报错,修改安装包权限为kibana
kibana启动后网页打不开怎么解决?
- 在config/kibana.yml里配置日志路径:logging.dest: /var/log/kibana.log
- 修改日志权限 touch /var/log/kibana.log chown kibana:kibana /var/log/kibana.log
- 日志也没有错,但是浏览器就是打不开。最后无意间换了个浏览器竟然正常了,再重新把之前打不开的chrome浏览器升级之后,也能正常打开了!!
4. x-pack监控情况分析(以节点B,周期为7天为例)
曲线中每一天大概24个点,即计算的是每个小时的数据
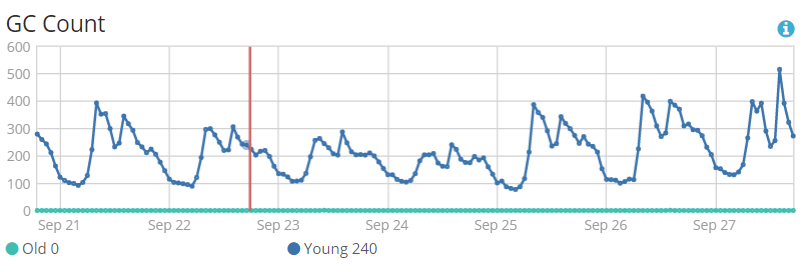
4.1 gc次数:平均值为250次/h 左右
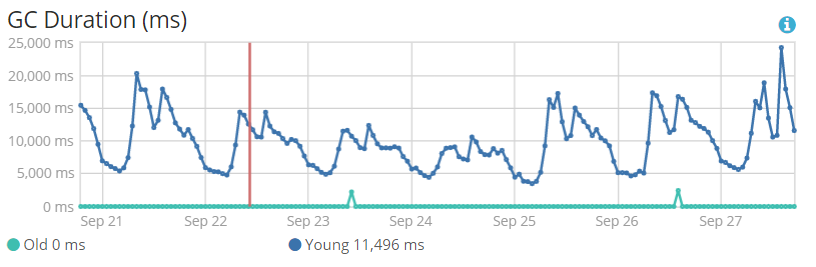
4.2 minor gc耗时:平均值为10000ms/h
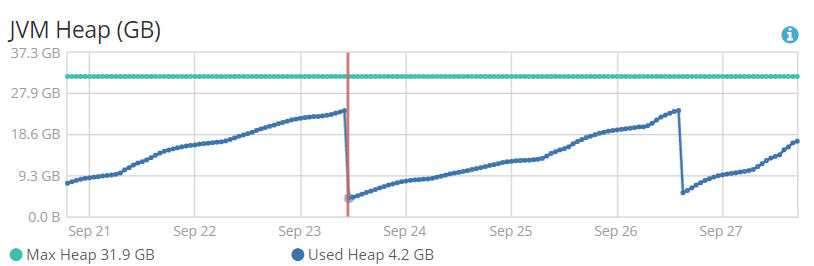
4.3 full gc后:剩余堆大小:4.2G,两次full gc的时间分别为2.224s,2.438s
5. 观察到的现象
- 新生代和老年代分配比例不合理,新生代太小,老年代太大
- 网上很多文章指出新生代和老年代的默认比例为1:2,但是通过观察发现并不是这样(我们的机器上约是1:20)。
- 具体原因在网上目前只找到这样一篇文章有过说明。CMS默认新生代是多大?
- 大致就是:取默认NewRatio计算出来的值和另外一个公式计算出来的值对比,取小的那一个
- 计算公式为:计算机核数*某个参数(64M)*13/10。我们的机器算出来的值为2G,勉强符合这个说法。
- 新生代垃圾回收频繁
- 老年代收集后:有效内存只达4G左右(活跃数据)
6. 针对观察到现象的初步分析和解决
- 新生代太小:导致minior gc回收频繁,可适当加大新生代大小
- 老年代太大:导致major gc或full gc回收时间过长,可适当减少老年代大小
- 如何确定新生代老年代大小:根据美团gc优化实战文章所述:
- 总大小:3-4倍活跃数据大小:
- 节点B为4.2G*4,我们设置为20G。
- 其他机器大概为3.6G*4,我们设置为16G
- 新生代:1-1.5倍活跃数据大小
- 老年代:总大小-新生代。综上,我们设置新生代:老年代=1:4
- 总大小:3-4倍活跃数据大小:
五. 调优实战
通过以上分析发现的问题,然后尝试调整参数,并且观察调整后的监控结果,验证我们的推测是否正确。
1. 修改配置参数
- 文件为{es_home}/config/jvm.options
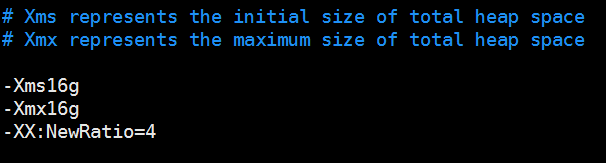
2. 修改后的堆配置参数
| 节点 | 堆总大小 | 新生代 | survivor | eden | 老年代 | 元数据区 |
|---|---|---|---|---|---|---|
| 节点A | 16G | 3.2G | 320M | 2.56G | 12.8G | 77M |
| 节点B | 20G | 4G | 400M | 3.2G | 16G | 66M |
| 节点C | 16G | 3.2G | 320M | 2.56G | 12.8G | 77M |
| 节点D | 16G | 3.2G | 320M | 2.56G | 12.8G | 77M |
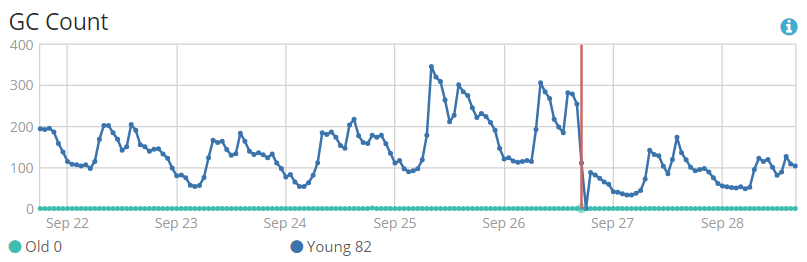
3. 修改后的监控信息
3.1 gc次数整体呈下降趋势
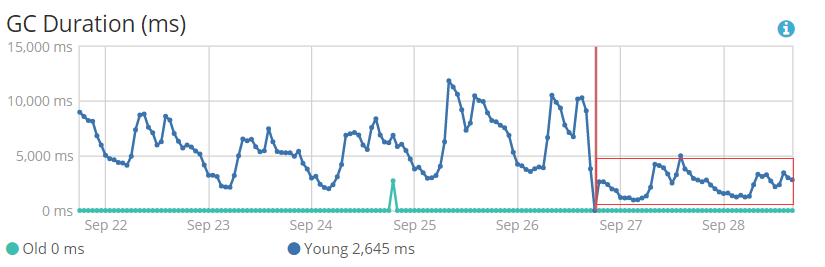
3.2 gc耗时整体呈下降趋势,full gc时间大致在900ms左右
4. springboot参数的调整
- 通过对JVM参数调整后,发现还是有不定时报警的情况。于是研究了一下springboot-admin的原理,它是基于springboot-actuator做了封装,然后看了一下springboot-actuator的原理,找到了其中一个很重要的参数:
management.health.elasticsearch.response-timeout - 该参数表示监控程序向es集群发送心跳,允许最大的响应时间的多少? 聪明的你应该明白了,如果发送心跳的时候,es的JVM正在执行垃圾回收,STW导致响应迟迟得不到回复,就会收到邮件告警。它的默认值是100ms,所以必须将该值设置为至少超过minior gc的时间。
- 但是,如果发送心跳的时候,恰好JVM正在执行full gc,因为STW的时间一般比较长,所以你必然会收到告警邮件,除非你把response-timeout的值设置为比full gc的时间还长
- 综上分析,需要根据垃圾回收的时间,给该值设置合理的值。
六. 总结与展望
1. 最终优化总结
1.1 关于JVM的调优
- 减少ES节点分配给JVM的堆大小
- 调整新生代和老年代的比例
1.2 关于springboot的调优
- 加大springboot-actuator针对Elasticsearch健康检查时的响应时间(默认为100ms)
2. 展望
- 业务优化:此次优化仅仅从JVM的角度做了参数调整,es官方文档其实给出很多高效使用es的方法。后续优化可以从业务的角度去分析,包括:
- 很多不需要分词的字段,都没有做配置,默认都分词了。特别影响性能。
- 很多查询没有用filter,用了query。无法缓存。
- 同时,期待将来ZGC投入使用,同时ES很好的兼容ZGC,或许那时就不需要任何调优了(不管多大的堆,gc时间在10ms内)。
七. 参考
- 《深入理解java虚拟机》
- 《elasticsearch权威指南》
- 美团gc优化实战
